目标检测 | YOLOv3开启的回归网络下的多尺度策略
1.简介
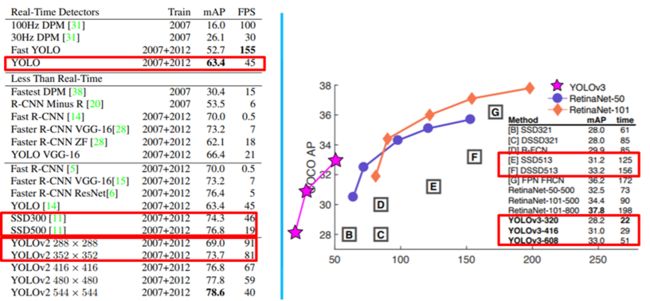
通过文章目标检测 | 让YOLOv1算法告诉你回归网络的能力和目标检测 | 让YOLOv2告诉你Trick的力量讲述了YOLO算法的原理和部分改进策略。YOLO系列算法在刚被提出时其目的在于提升检测网络的速度,因此其算法的召回率和检测率相对于Faster RCNN系列算法会要低一些。作者为了提升YOLO算法的实用性,提出了YOLOv2,在不损失速度的情况下提升了网络精度。但从下图的左图中我们可以发现,在输入同等级分辨率图片的情况下,YOLOv2的精度是没有SSD系列算法好的。而YOLOv3的提出,彻底稳固了YOLO系列算法的地位,因为如下图右图所示YOLOv3使得YOLO系列算法的性能超越了SSD系列。因此本文就从原理上来简单阐述下YOLOv3算法的主要改进点,后续会针对YOLOv3算法解析darknet框架下的训练源码。
2.改进点
1.box是否含有物体改进
利用logistic回归计算每个bounding box是否含有物体(二分类:有或者没有)。在该过程中,之前的YOLOv2算法是看ground truth的位置中心坐标在哪,来判定当前bounding box是否含有物体。而在YOLOv3中将与ground truth的IOU最大的那个bounding box认为是包含该物体,因此YOLOv3的特点是每个ground truth都仅仅分配一个bounding box。对于那些没有被分配的bounding box,网络计算损失时,仅仅计算是否包含物体损失,不计算坐标和类概率损失。
2.类概率预测改进
对于类概率预测,在YOLOv2中是直接利用softmax进行类概率预测。而在YOLOv3中对于每一个类,使用独立的logistic分类器,使用交叉熵损失计算类概率损失。用这种策略的原因是,考虑到在利用softmax分类时,需要把所有的类别独立开来(one hot编码的特点),但是一旦遇到如(女人 ,人)这种包含类别时,用softmax就不是那么合适了。因此才引入logistic分类器结合多标签,来处理此类问题。
3.多尺度检测策略改进
YOLOv3的多尺度策略在三个不同的尺度作detection。
v2只有一个detection,v3一下变成了3个,在3个不同尺度的feature map上进行detection。在输入为416的情况下这三个特征图的尺度为13*13,26*26,52*52,这应该是对小目标影响最大的地方。
如下图所示,在输入为640*352的情况下,三个不同尺度的detection位置和特征图大小(分辨率搞成宽高不一样,感觉更直观一点)。
70 conv 27 1*1/1 20*11*256 -> 20*11*27
71 detection
72 route 29
73 conv 256 3*3/2 80*44*128 -> 40*22*256
74 route 73 48
75 conv 256 1*1/1 40*22*512 -> 40*22*256
76 conv 256 3*3/1 40*22*512 -> 40*22*256
77 conv 256 1*1/1 40*22*512 -> 40*22*256
78 conv 27 1*1/1 40*22*512 -> 40*22*27
79 detection
80 route 10
81 conv 128 3*3/2 160*88*64 -> 80*44*128
82 route 81 29
83 conv 256 1*1/1 80*44*256 -> 80*44*256
84 conv 256 3*3/1 80*44*256 -> 80*44*256
85 conv 256 1*1/1 80*44*256 -> 80*44*256
86 conv 27 1*1/1 80*44*256 -> 80*44*27
87 detection
3.YOLOv3的网络框架图
如下图所示,左边虚线框就是YOLOv3网络的特征提取模块的示意图,以416分辨率的图像作为输入,根据网络的深入,会产生3中不同尺度的特征图(52,26,13),YOLOv3在这三个尺度上进行不同尺度的目标检测。

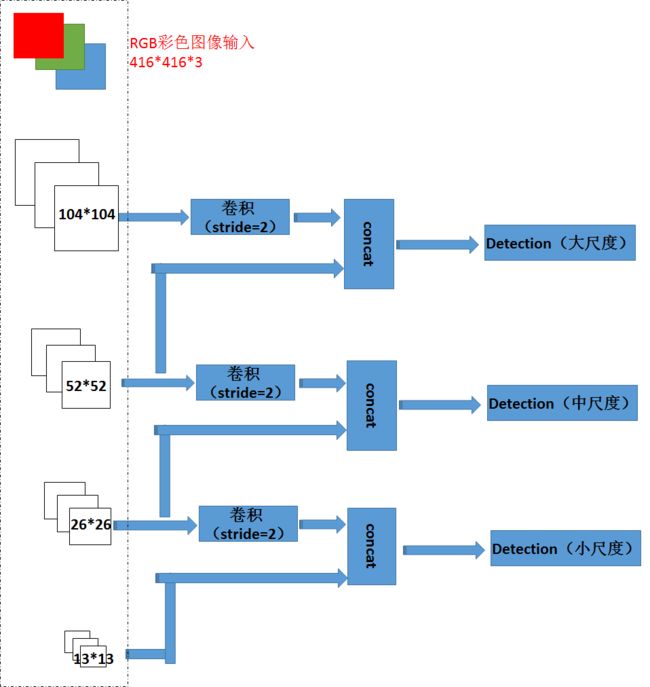
如上图的框架所示,我们发现整个网络中用到了上采样操作,这其实是一种相对比较耗时,而且性价比不高的手段,因此在我用YOLOv3网络时做了一点小改动,在不损失网络精度和网络思想的前提下去掉网络的上采样过程。思路就如下图所示,通过stride为2的卷积实现下采样,最终也能实现三个尺度的detection,而且可以不用到上采样操作。
本文简单介绍了一下YOLOv3的策略,后续会更新一些YOLOv3的源码解读,欢迎持续关注~