pyspark及Spark报错问题汇总及某些函数用法。
此贴,主要记录本人在工作中遇到的某些报错问题,并提出自己的解决办法。
1.
spark = SparkSession.builder() TypeError: 'Builder' object is not callable
解决办法:.builder() 改为 .builder https://issues.apache.org/jira/browse/SPARK-18426
spark = SparkSession.builder() 改为 spark = SparkSession.builder2.
py4j.protocol.Py4JJavaError: An error occurred while calling o49.load.
: java.lang.NoSuchMethodError: scala.Product.$init$(Lscala/Product;)V
此报错是scala的版本过低所致,本人当前环境选用的是scala 2.11.0版本,升级到2.11.8后【版本建议和spark所支持的版本一致,版本号2.11.8仅作参考】,没有再出现此报错。
3.
'PipelinedRDD' object has no attribute '_jdf'
报这个错,是因为导入的机器学习包错误所致。
pyspark.ml 是用来处理DataFrame
pyspark.mllib是用来处理RDD。
所以你要看一下你自己代码里定义的是DataFram还是RDD。
sc = SparkContext() 【RDD】 应导入
from pyspark.mllib.feature import HashingTF, IDFspark = SparkSession(sc) 【DataFrame】 应导入from pyspark.ml.feature import HashingTF, IDF
4.
PySpark spark.sql 使用substring及其他sql函数,提示NameError: name 'substring' is not defined
解决办法,导入如下的包即可。
from pyspark.sql.functions import *Scala则导入
import org.apache.spark.sql.functions._
5.
org.apache.spark.sql.DataFrame = [_corrupt_record: string]
读取json文件报错。
此问题首先要明白spark读取文件的原理,是按行作为一个record,所以你要看下你的json文件是否是平整的。下面我举个例子,
原json文件内容如下:【文件中存在换行符】
{
"staffList":{
"total":3,
"result":[
{
"toco":41,
"id":1,
"name":"张三",
"typeJoin":[
"22"
],
"type":2
},
{
"toco":46,
"id":2,
"name":"李四",
"typeJoin":[
"22"
],
"type":2
},
{
"toco":42,
"id":3,
"name":"王五",
"typeJoin":[
"22"
],
"type":2
}
]
}
}解决方法①
应该将文件内容"压平"成为平面文件,转换成如下格式:
{"staffList" : {"total" : 3,"result" : [ { "toco" : 41, "id" : 1, "name" : "张三", "typeJoin" : 22, "type" : 2}, { "toco" : 46, "id" : 2, "name" : "李四", "typeJoin" : 22, "type" : 2}, { "toco" : 42, "id" : 3, "name" : "王五", "typeJoin" : 22 ], "type" : 2} ]}}再读取json文件,即可。

解决方法Ⅱ
或者在读取json文件时,指定读取多行为真,option("multiLine", true) 。
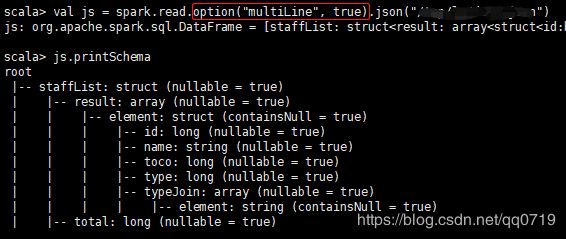
6.
==========================================================
Spark SQL 和 DataFrames 支持下面的数据类型 :
- 数值类型
- ByteType : 表示 1 字节长的有符号整型,数值范围 : -128 到 127。
- ShortType : 表示 2 字节长的有符号整型,数值范围 : -32768 到 32767。
- IntegerType : 表示 4 字节长的有符号整型,数值范围 : -2147483648 到 2147483647。
- LongType : 表示 8 字节长的有符号整型,数值范围 : -9223372036854775808 到 9223372036854775807。
- FloatType : 表示 4 字节长的单精度浮点数。
- DoubleType : 表示 8 字节长的双精度浮点数。
- DecimalType : 表示任意精度有符号带小数的数值。内部使用 java.math.BigDecimal,一个BigDecimal 由一个任意精度的整数非标度值和一个 32 位的整数标度 (scale) 组成。
-
字符串类型
-
StringType : 表示字符串值
-
- 二进制类型
- BinaryType : 表示字节序列值
- 布尔类型
- BooleanType : 表示布尔值
- 日期类型
- TimestampType : 表示包含年月日、时分秒等字段的日期值
- DateType : 表示包含年月日字段的日期值
- Complex types(复杂类型)
-
ArrayType(elementType, containsNull) : 数组类型,表示一个由类型为 elementType 的元素组成的序列,containsNull 用来表示 ArrayType 中的元素是否能为 null 值。
-
MapType(keyType, valueType, valueContainsNull) : 映射类型,表示一个键值对的集合。键的类型由 keyType 表示,值的类型则由 valueType 表示。对于一个 MapType 值,键是不允许为 null值。valueContainsNull 用来表示一个 MapType 的值是否能为 null 值。
-
StructType(fields) : 表示由 StructField 序列描述的结构。
- StructField(name, datatype, nullable) : 表示 StructType 中的一个字段,name 表示字段名,datatype 是字段的数据类型,nullable 用来表示该字段是否可以为空值。
-
==========================================================
对于嵌套结构数据,如何定义schema
首先导入包 import org.apache.spark.sql.types._
其次,对于StructType的定义,参考spark源代码,有说https://github.com/apache/spark/blob/master/sql/catalyst/src/main/scala/org/apache/spark/sql/types/StructType.scala
// Extract multiple StructFields. Field names are provided in a set. 提取多个StructField。字段名称以集合形式提供
https://www.programcreek.com/scala/org.apache.spark.sql.types.ArrayType
还是参考之前一个嵌套结构json数据,定义一个Schema
{
"staffList":{
"total":3,
"result":[
{
"toco":41,
"id":1,
"name":"张三",
"typeJoin":[
"22"
],
"type":2
},
{
"toco":46,
"id":2,
"name":"李四",
"typeJoin":[
"22"
],
"type":2
},
{
"toco":42,
"id":3,
"name":"王五",
"typeJoin":[
"22"
],
"type":2
}
]
}
}下面给出我写定义的schema
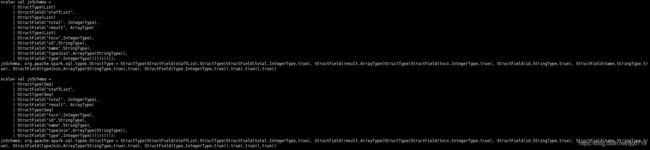
val jsSchema =
StructType(Seq(
StructField("staffList",
StructType(Seq(
StructField("total", IntegerType),
StructField("result", ArrayType(
StructType(Seq(
StructField("toco",IntegerType),
StructField("id",StringType),
StructField("name",StringType),
StructField("typeJoin",ArrayType(StringType)),
StructField("type",IntegerType))))))))));
# 或者
val jsSchema =
StructType(List(
StructField("staffList",
StructType(List(
StructField("total", IntegerType),
StructField("result", ArrayType(
StructType(List(
StructField("toco",IntegerType),
StructField("id",StringType),
StructField("name",StringType),
StructField("typeJoin",ArrayType(StringType)),
StructField("type",IntegerType))))))))));spark上验证定义的schema正确
7.
WARN Utils: Truncated the string representation of a plan since it was too large. This behavior can be adjusted by setting 'spark.debug.maxToStringFields' in SparkEnv.conf.
==========
在交互环境,暂时修改
scala> spark.conf.set("spark.debug.maxToStringFields","100")
===========
永久修改
在节点(集群)的sparkEnv.sh中修改或新增spark.debug.maxToStringFields变量
8.
java.lang.IllegalArgumentException: Can't zip RDDs with unequal numbers of partitions这个报错,是因为使用rdd的zip函数时,两个rdd的分区个数不一致所致。
摘录一段官方api说明:
Zips this RDD with another one, returning key-value pairs with the first element in each RDD, second element in each RDD, etc. Assumes that the two RDDs have the same number of partitions and the same number of elements in each partition (e.g. one was made through a map on the other).
解决的办法是: 将两个rdd的分区个数统一后,再zip。
附上伪代码:
RDD1.coalesce(1).zip(RDD2.coalesce(1))9.
foreach(println)无法将RDD的字段,打印到stdout中?
Printing elements of an RDD
Another common idiom is attempting to print out the elements of an RDD using rdd.foreach(println) or rdd.map(println). On a single machine, this will generate the expected output and print all the RDD’s elements. However, in cluster mode, the output to stdout being called by the executors is now writing to the executor’s stdout instead, not the one on the driver, so stdout on the driver won’t show these! To print all elements on the driver, one can use the collect() method to first bring the RDD to the driver node thus: rdd.collect().foreach(println). This can cause the driver to run out of memory, though, because collect() fetches the entire RDD to a single machine; if you only need to print a few elements of the RDD, a safer approach is to use the take(): rdd.take(100).foreach(println).
关于RDD的输出,官网上是以上叙述:
意思就是:利用rdd.foreach(println) 或者 rdd.map(println),在一台机器上时,会得到理想的输出,打印出所有的RDD的数值;但在集群环境中,输出会被executors唤起,被写到executors的输出,而不是驱动所在的主机,所以在主机上不会显示打印信息,为了能够在主机上打印信息,要使用collect()函数首先把RDD放到主机节点上,rdd.collect().foreach(println),但因为collect()会将整个RDD的数据放到主机上,会使得驱动主机内存溢出。如果你只想打印出有限个RDD数据,一个靠谱的方法就是用take():rdd.take(100).foreach(println)
10.
spark Sql使用md5的方法:
详情参考:
https://stackoverflow.com/questions/45035944/function-over-multiple-spark-dataframe-columns-at-once
11.
spark sql yyyymmdd to yyyy-MM-dd:
详情参考:
https://stackoverflow.com/questions/40433065/scala-spark-sql-to-dateunix-timestamp-returning-null
#伪代码
select(date_format(unix_timestamp(substring($"date",1,8), "yyyyMMdd").cast("timestamp"), "yyyy-MM-dd"))
spark.sql("""
SELECT DATE_FORMAT(
CAST(UNIX_TIMESTAMP('20161025', 'yyyyMMdd') AS TIMESTAMP), 'yyyy-MM-dd')
""")
#如果传的日期是整型,需要使用cast转换成string
# date 20161025
spark.sql("""
SELECT DATE_FORMAT(
CAST(UNIX_TIMESTAMP(cast(date as string), 'yyyyMMdd') AS TIMESTAMP), 'yyyy-MM-dd')
""")12.
Spark sql 将array类型字符串转换成为一个字符串。
How to convert column of arrays of strings to strings?
https://stackoverflow.com/questions/38924762/how-to-convert-column-of-arrays-of-strings-to-strings
In Spark 2.1+ to do the concatenation of the values in a single Array column you can use the following:
concat_wsstandard functionmapoperator- a user-defined function (UDF)
13.
spark sql scala row_number over 函数用法
https://stackoverflow.com/questions/46584773/update-spark-dataframes-window-function-row-number-column-for-delta-data
#伪代码
select(
col("KEY1"), col("KEY2"), col("VAL"), row_number().over(
Window.partitionBy(col("KEY1"), col("KEY2")).orderBy(col("Row_Num"))
).alias("New_Row_Num")
14.
Joining Multiple DataFrames using Multiple Conditions Spark Scala
https://stackoverflow.com/questions/41999385/joining-multiple-dataframes-using-multiple-conditions-spark-scala?rq=1
伪代码:
val result = df1.as("df1").join(df2.as("df2"),
$"df1.col1"===$df2.col1" && $"df1.col2"===$df2.col2").join(df3.as("df3"),
$"df3.col1"===$df2.col1" && $"df3.col2"===$df2.col2", "left_outer")
15.
spark Sql 对于嵌套的结构的提取。
使用explode函数来操作,如果有多层嵌套,使用多次explode函数即可。
http://bigdatums.net/2016/02/12/how-to-extract-nested-json-data-in-spark/
单层嵌套
{
"user": "gT35Hhhre9m",
"dates": ["2016-01-29", "2016-01-28"],
"status": "OK",
"reason": "some reason",
"content": [{
"foo": 123,
"bar": "val1"
}, {
"foo": 456,
"bar": "val2"
}, {
"foo": 789,
"bar": "val3"
}, {
"foo": 124,
"bar": "val4"
}, {
"foo": 126,
"bar": "val5"
}]
}//explode content field
scala> val dfContent = df.select(explode(df("content")))
dfContent: org.apache.spark.sql.DataFrame = [col: struct]
//output
scala> dfContent.show
+----------+
| col|
+----------+
|[val1,123]|
|[val2,456]|
|[val3,789]|
|[val4,124]|
|[val5,126]|
+----------+
//rename "col" to "content"
scala> val dfContent = df.select(explode(df("content"))).toDF("content")
dfContent: org.apache.spark.sql.DataFrame = [content: struct]
//output
scala> dfContent.show
+----------+
| content|
+----------+
|[val1,123]|
|[val2,456]|
|[val3,789]|
|[val4,124]|
|[val5,126]|
+----------+
//extracting fields in struct
scala> val dfFooBar = dfContent.select("content.foo", "content.bar")
dfFooBar: org.apache.spark.sql.DataFrame = [foo: bigint, bar: string]
//output
scala> dfFooBar.show
+---+----+
|foo| bar|
+---+----+
|123|val1|
|456|val2|
|789|val3|
|124|val4|
|126|val5|
+---+----+ 多层嵌套
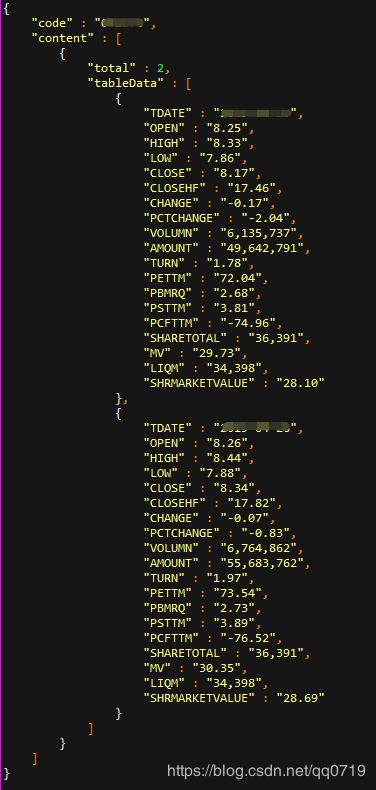
提取tableData的数据
伪代码
val DailyPriceDimDF = DailyPriceDimDF_
.select($"code", explode($"content") as "data")
.select($"code", explode($"data.tableData") as "data")


16.
scala spark sql 将yyyymmdd的字符串转为yyyy-mm-dd日期类型:
伪代码
#openingHours 19970413000000
select(date_format(unix_timestamp(substring($"openingHours",1,8), "yyyyMMdd").cast("timestamp"), "yyyy-MM-dd").alias("approveDate")
)
spark.sql("""
SELECT DATE_FORMAT(
CAST(UNIX_TIMESTAMP('20161025', 'yyyyMMdd') AS TIMESTAMP), 'yyyy-MM-dd')
""")
#如果传的日期是整型,需要使用cast转换成string
# date 20161025
spark.sql("""
SELECT DATE_FORMAT(
CAST(UNIX_TIMESTAMP(cast(date as string), 'yyyyMMdd') AS TIMESTAMP), 'yyyy-MM-dd')
""")
17.
Spark Sql 日期函数的综合应用:
https://www.cnblogs.com/feiyumo/p/8760846.html
https://www.obstkel.com/blog/spark-sql-date-functions
上述两个帖子,有日期函数的使用说明
下面说下重点,求出某一天对应年及月及日的指标,伪代码如下
//新增 day_of_year, week_of_year, month_of_year, day_of_week, day_of_month, days_of_month, days_of_year
#年的第几天
.withColumn("day_of_year", dayofyear(from_unixtime(col("unix_time"), "yyyy-MM-dd")).cast(LongType))
#年的第几周
.withColumn("week_of_year", weekofyear(from_unixtime(col("unix_time"), "yyyy-MM-dd")).cast(LongType))
#年的第几个月
.withColumn("month_of_year", month(from_unixtime(col("unix_time"))).cast(LongType))
#一周的第几天(周一为第一天,未使用dayofmonth,该函数的每周第一天是周日)
.withColumn("day_of_week", from_unixtime(col("unix_time"), "u").cast(LongType))
#月的第几天
.withColumn("day_of_month", dayofmonth(from_unixtime(col("unix_time"))).cast(LongType))
#所在月份有几天
.withColumn("days_of_month", datediff( last_day(trunc(from_unixtime(col("unix_time"), "yyyy-MM-dd"), "MM")), trunc(from_unixtime(col("unix_time"), "yyyy-MM-dd"), "MM")).cast(LongType) +1)
#所在年份有几天
.withColumn("days_of_year", datediff( concat(year(from_unixtime(col("unix_time"), "yyyy-MM-dd")), lit("-12-31")), trunc(from_unixtime(col("unix_time"), "yyyy-MM-dd"), "year")).cast(LongType) +1 )
#所在月份对应季度的最后一天
.withColumn("quarter_date", l
last_day(concat(year(from_unixtime(col("unix_time"))).cast(StringType),
lit("-"),
when(quarter(from_unixtime(col("unix_time"))) === 1, lit("03"))
.when(quarter(from_unixtime(col("unix_time"))) === 2, lit("06"))
.when(quarter(from_unixtime(col("unix_time"))) === 3, lit("09"))
.otherwise(lit("12")),
lit("-01"))
) 补充一个函数的说明:
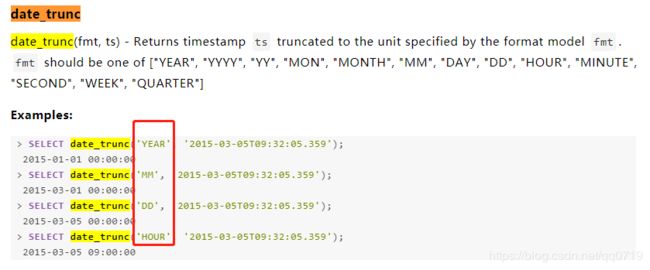
date_trunc函数用法,我参考了官网的说明,发现其示例有错误。
https://spark.apache.org/docs/2.3.0/api/sql/#date_trunc
date_trunc
date_trunc(fmt, ts) - Returns timestamp ts truncated to the unit specified by the format model fmt.fmt should be one of ["YEAR", "YYYY", "YY", "MON", "MONTH", "MM", "DAY", "DD", "HOUR", "MINUTE", "SECOND", "WEEK", "QUARTER"]

正确用法
https://www.iteblog.com/archives/2336.html
18.
工作中遇到了一些字符串中偶然含有 \n (软回车) \r (软空格),在写入到hive后,建Kylin cube时有报错,说明在数据清洗时,没有考虑到这一点。要在数据清洗时,去除 \n (软回车) \r (软空格)
伪代码
# RDD的替换方法
s.replaceAll("[\\r\\n]", "")
# Spark Sql的替换方法
select(regexp_replace(trim($"name"), "[\\r\\n]", "").alias("name"))19.
Spark Dataframe WHERE Filter 这两个函数的讲解
鉴于原贴写的很好,我就给个链接。
http://sqlandhadoop.com/spark-dataframe-where-filter/
http://sqlandhadoop.com/spark-dataframe-in-isin-not-in/
http://sqlandhadoop.com/spark-sql-dataframe/ 一些用法值得借鉴
我只说一点 in 的用法,在spark sql里,需要用 filter( .isin) 的形式来展现。
20.
spark sql window函数初探:
先附上相关网站链接,后续给出自己的伪代码示例:
https://blog.csdn.net/weixin_42379136/article/details/86675049
https://blog.csdn.net/Shie_3/article/details/82890897
https://databricks.com/blog/2015/07/15/introducing-window-functions-in-spark-sql.html?utm_source=twitterfeed&utm_medium=twitter
https://riptutorial.com/apache-spark/example/22861/window-functions---sort--lead--lag---rank---trend-analysis
21.
spark sql 从某一个表读取数据,之后再将数据写回原表,没有数据?
原因:回归问题本质,Spark是惰性执行。 具体解释请看如下帖子中的说明。
最佳答案
问题出在您的代码中.因为您覆盖了一个您尝试读取的表,所以在Spark实际访问它之前,您会有效地删除所有数据.
请记住,Spark是懒惰的.创建数据集时,Spark会提取所需的元数据,但不会加载数据.因此,没有魔法缓存可以保留原始内容.实际需要时将加载数据.在这里,当您执行写入操作时,当您开始写入时,不再需要获取数据.
你需要的是这样的:
>创建数据集.
>应用所需的转换并将数据写入中间MySQL表.
> TRUNCATE原始输入和INSERT INTO … SELECT从中间表或DROP原始表和RENAME中间表.
替代但不太有利的方法是:
>创建数据集.
>应用所需的转换并将数据写入持久性Spark表(df.write.saveAsTable(…)或等效表)
> TRUNCATE原始输入.
>读取数据并保存(spark.table(…).write.jdbc(…))
> Drop Spark表.https://codeday.me/bug/20190309/744771.html
https://codeday.me/bug/20190301/716426.html
22.
org.apache.spark.sql.AnalysisException: Reference 'XXXXX' is ambiguous
原因是:多表join后,存在重复列的问题。
①解决办法,选择重复列时,指明该列来自之前join的DataFrame即可。
②join时,把重复列取别名。
下面对方法①做一个demo演示。
val joined = df.join(df2, df("course") === df2("course") && df("name") === df2("name"), "left_outer")
#出现了重复course 和 name 列
#取 course 和 name 列时,指定对应df的列即可
# 报错代码
val errCode = joined.select("name", "course")
#org.apache.spark.sql.AnalysisException: Reference 'XXX' is ambiguous
###########################
#正确代码
val rightCode = joined.select(df("name"), df("course"), df2("name"), df2("course"))
23.
SparkSQL - The correlated scalar subquery can only contain equality predicates
https://stackoverflow.com/questions/41631199/sparksql-the-correlated-scalar-subquery-can-only-contain-equality-predicates
写spark Sql时,用到了嵌套select查询,但sql解析报错,究其原因,和spark本身sql解析机制有关,解决办法是:
改写原有sql即可。下面给出我的一个demo
##有个需求:填充非交易日股票价格,那么需要找到离非交易日最近的那个交易日股价。
###########
# 报错sql
val wrongDF = ss.sql("""
select a.stock_id, a.code, a.date_id, a.date_value,
(select max(b.date_id)
from stockPriceNotNullDF b
where b.stock_id = a.stock_id and b.date_id < a.date_id
) as oid
from stockPriceNullDF a
group by a.stock_id, a.code, a.date_id, a.date_value
order by a.stock_id, a.date_id
""")
#提示
The correlated scalar subquery can only contain equality predicates
###################
# 改写之后的sql,放弃使用子查询方式
val rightDF = ss.sql("""
select a.stock_id, a.code, a.date_id, a.date_value,
max(b.date_id) as oid
from stockPriceNullDF a, stockPriceNotNullDF b
where b.stock_id = a.stock_id and b.date_id < a.date_id
group by a.stock_id, a.code, a.date_id, a.date_value
order by a.stock_id, a.date_id
""")
24.
Spark SQL 的日期函数 dayofweek ,返回的天数,不是国人习惯的日期。
参考官方文档解释:https://people.apache.org/~pwendell/spark-nightly/spark-master-docs/latest/api/sql/#dayofweek
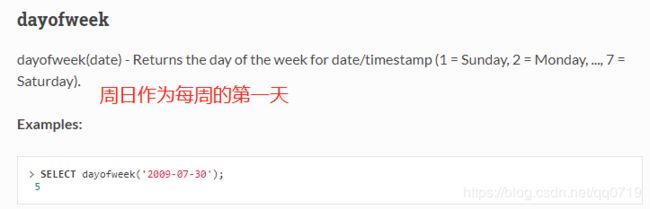
https://www.cnblogs.com/chenzechao/p/9336764.html
若改成国人习惯的日期,则需要自行转换,下面给出demo (scala中用when else 来判断)
//新增days_of_week 当周第几天(按照国人习惯,周一为第一天)
.withColumn("days_of_week", when(dayofweek(from_unixtime(col("unix_time"), "yyyy-MM-dd")) === 1, 7)
.otherwise(dayofweek(from_unixtime(col("unix_time"), "yyyy-MM-dd")) -1)
.cast(LongType))
25.
Spark Sql求出每一周的周一和周日
当看到这个需求时,很自然的想到用 date_sub或date_add函数,但参考官方文档的函数说明,发现其用法跟关心型数据库sql语法不太一致,需要做一些转换才可以达到想要的效果。
https://spark.apache.org/docs/1.6.0/api/java/org/apache/spark/sql/functions.html#date_add(org.apache.spark.sql.Column,%20int)
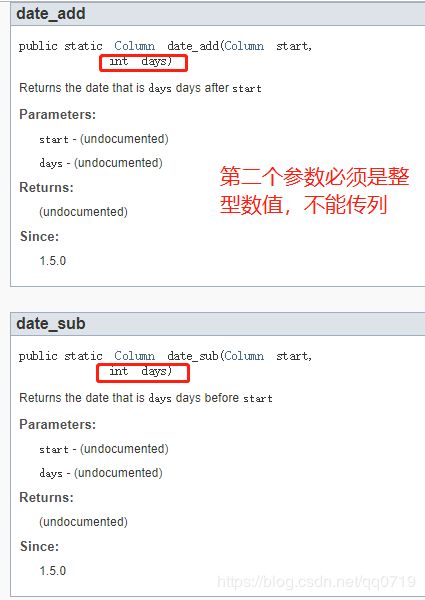
所以有一个变通的方法。 date_sub或者date_add与next函数相结合来满足这个需求
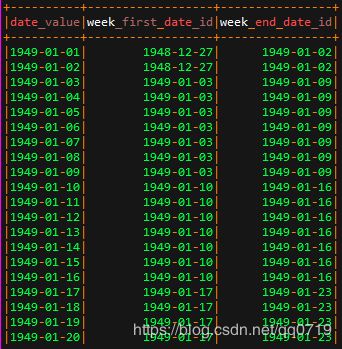
# date_value 2019-07-31
.withColumn("week_first_date_id", date_sub(next_day($"date_value", "monday"), 7))
.withColumn("week_end_date_id", when($"days_of_week" === 7, $"date_value")
.otherwise(next_day($"date_value", "sunday").cast(StringType))
)如下是demo输出结果
26.
Spark DataFrame写入Hive Orc 分区表
分区表建立过程不过多演示,只给出写入hive表的过程。
addStgCompanyDF.write.partitionBy("dt").mode(SaveMode.Overwrite).orc("hdfs://XXXX/apps/hive/warehouse/XXXX.db/XXXXX/")数据写入hdfs后,如果通过hive去查询,表中无数据,还需要使用 msck 修复hive元数据信息。
https://community.hortonworks.com/questions/198754/msck-repair-hive-external-tables.html
https://www.ibm.com/support/knowledgecenter/en/SSCRJT_5.0.1/com.ibm.swg.im.bigsql.commsql.doc/doc/biga_msckrep.html
- hive> Msck repair table
.
27.
Spark : org.apache.spark.sql.AnalysisException: Reference 'XXXX' is ambiguous
这个问题是大多是因为,多个表join后,存在同名的列,在select时,取同名id,无法区分所致。
解决办法:
①对于列名相同的列,在DataFrame中更名。alias或withColumnRenamed可以实现,demo代码就暂时不提供。
②在join后,drop掉同名的列
df1.join(df2,df1.a == df2.a,'left_outer').drop(df2.a)
28.
Spark Dataframe 保存为ORC表的方法
Overwrite形式举例:
.write.mode(SaveMode.Overwrite).format("orc").saveAsTable("库名.表名")
Append形式举例:
.write.mode(SaveMode.Append).format("orc").insertInto("库名.表名")
分区表Overwrite形式举例:
.write.partitionBy("XX").mode(SaveMode.Overwrite).format("orc").saveAsTable("库名.表名")29.
Spark 的Scala项目中,读取mysql数据
https://www.cnblogs.com/wwxbi/p/6978774.html
①在sbt配置文件中,添加mysql依赖。版本很多,选用哪一个版本均可以的,以下是示例:
libraryDependencies XXX
添加 "mysql" % "mysql-connector-java" % "5.1.28"
②sbt assembly
③读取mysql表方法:
import java.util.Properties
val mysqlUrl = "jdbc:mysql://localhost:3306/test"
val mysqlTable = "name_map"
val user = "XXX"
val password = "XXX"
val properties = new Properties()
properties.setProperty("user", user)
properties.setProperty("password", password)
properties.setProperty("driver","com.mysql.jdbc.Driver")
val df2 = ss.read.jdbc(mysqlUrl, mysqlTable, properties)
df2.show()
如下帖子中有一些可能的报错,值得借鉴:
com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
https://stackoverflow.com/questions/2983248/com-mysql-jdbc-exceptions-jdbc4-communicationsexception-communications-link-fai
解决办法:

可能还会有的报错:
ERROR ApplicationMaster: User class threw exception: java.sql.SQLException: No suitable driver
java.sql.SQLException: No suitable driver在spark连接mysql的代码里指定driver为:"com.mysql.jdbc.Driver"
【properties.setProperty("driver","com.mysql.jdbc.Driver")】
30.
spark 累加历史 + 统计全部 + 行转列
此作者写的很好,附送原链接地址,在这里不做过多赘述,只说明一些关键用法
https://www.cnblogs.com/piaolingzxh/p/5538783.html
preceding:用于累加前N行(分区之内)。若是从分区第一行头开始,则为 unbounded。 N为:相对当前行向前的偏移量
following :与preceding相反,累加后N行(分区之内)。若是累加到该分区结束,则为 unbounded。N为:相对当前行向后的偏移量
current row:顾名思义,当前行,偏移量为0说明:上边的前N,后M,以及current row均会累加该偏移量所在行
31.
Spark SQL case when用法:
https://sparkbyexamples.com/spark-case-when-otherwise-example/
https://stackoverflow.com/questions/37064315/how-to-write-case-with-when-condition-in-spark-sql-using-scala
https://stackoverflow.com/questions/40522149/spark-sql-implement-and-condition-inside-a-case-statement
上述几个帖子已经写得很详细了,我就不再赘述,只放出链接。
32.
Spark 读取mongo 使用withPipeline的用法:
在工作中遇到过需要从一个公司列表中找出mongo中存在的公司信息。参考Mongo语法 $in可支持这个用法
https://docs.mongodb.com/manual/reference/operator/query/in/
需要配合spark的.withPipeline来使用。
https://docs.mongodb.com/spark-connector/current/scala/aggregation/
pipeline需要给出的条件是字符串,所以需要对一些字段转换成字符串即可
【 scala 的 mkstring 用法 https://blog.csdn.net/lan12334321234/article/details/84882002】
下面贴出关键的代码。
#dataFrame都只有公司名
val addCompanyNameArray = entryCompanyNameDF.except(stgCompanyNameDF).map(r => r.getString(0)).collect.toArray
#将公司Array转为字符串
// 将Array转换成String
var addCompanyNameStr = addCompanyNameArray.mkString("\"", "\",\"", "\"")
#读取Mongo的过程不做赘述
#下面 withPipeline 配合 $in来使用
val df = sc.loadFromMongoDB(readconf).withPipeline(Seq(Document.parse("{ $match: { 'name' : {$in : [" + addCompanyNameStr + "]} } }"))).toDF(schema)
33.
如何在spark Sql里 创建自增id字段,作为主键?
参考诸多网络上给出的 zipwithindex方法,感觉不能满足要求。
想到了使用window函数来创建id
下面给出示例:
import org.apache.spark.sql.expressions.Window
# 可以指定自增id的起始值,从maxCompanyId往后计数
val df1 = df.withColumn("id",row_number.over(Window.partitionBy(lit(1)).orderBy(lit(1))).cast(LongType)+lit(maxCompanyId))
#从1开始自增
val df2 = df.withColumn("id",row_number.over(Window.partitionBy(lit(1)).orderBy(lit(1))).cast(LongType))
34.
scala.collection.mutable.WrappedArray$ofRef cannot be cast to scala.collection.immutable.Set
在工作中,需要些UDF函数,对某些字段做替换。对数组类型转换时,遇到如下报错

情景复原:
原始代码中使用了 Array[] 来定义,根据网络上一些解释,此方法,会引用WrappedArray。 建议将Array 换成Seq。
参考:
https://stackoverflow.com/questions/40199507/scala-collection-mutable-wrappedarrayofref-cannot-be-cast-to-integer
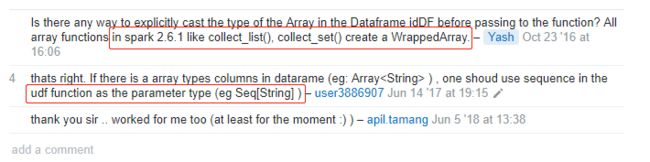
https://stackoverflow.com/questions/40764957/spark-java-lang-classcastexception-scala-collection-mutable-wrappedarrayofref
官方文档写的很详细
https://docs.scala-lang.org/zh-cn/overviews/collections/arrays.html