作者: Zongwei Zhou | 周纵苇
微博: @MrGiovanni
Email: [email protected]
项目: Minimizing Annotation Cost in Medical Image Analysis
1 引入
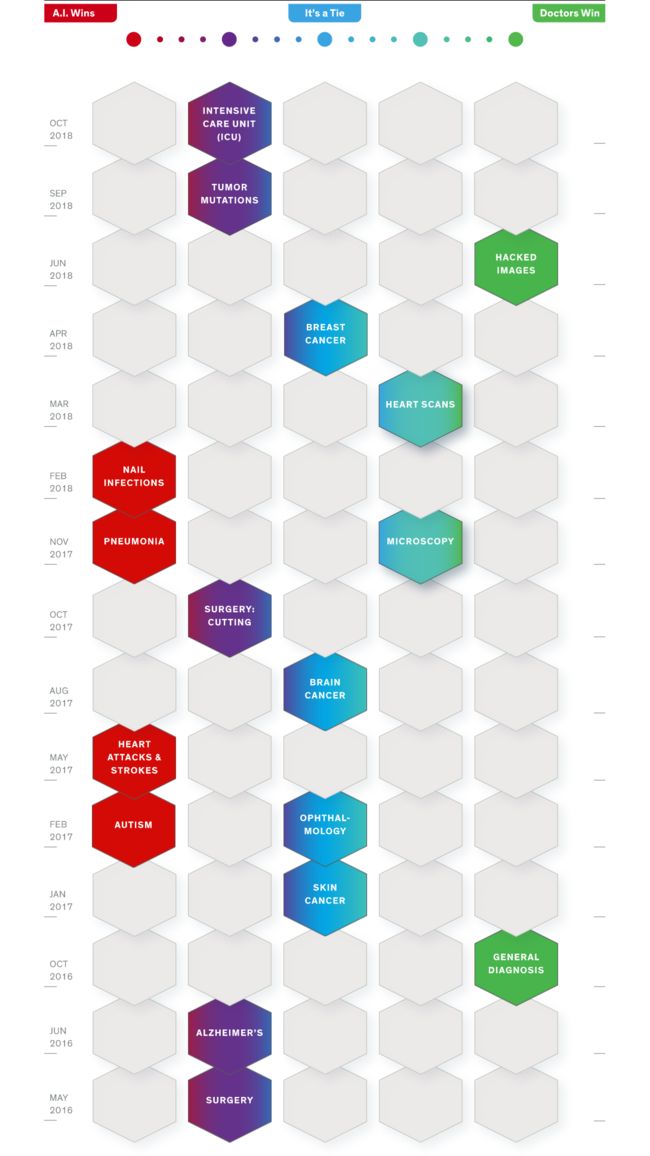
人工智能非常火。医学院开设了课程让学生使用人工智能辅助工具。 “神经网络之父”Hinton预言说放射科的医生将在5-10年內被计算机取代(Geoff Hinton: On Radiology),就像以前的高速公路,地铁,火车收费站的工作一样,同时,不持这个观点也大有人在(Despite AI, the Radiologist is here to stay)。总体来讲人工智能在这十年内无论在学术还是产业,确实取得了长足的进步,也渐渐融入我们的生活。IEEE Spectrum在2018新年推出专刊“AI vs Doctors”,统计了从2016年5月至今,人工智能与人类医生的较量。其中,肺炎,心脏病和中风等疾病的诊断准确度,人工智能远高于人类医生的水平。
先来简单介绍一下现在的人工智能在医学影像领域是如何工作的。比如要让计算机来根据一幅病人的CT图片,判断这个人是否得了癌症。目标非常简单,是个二分类问题,就告诉我得没得癌症,要让这个问题用计算机得到解决,需要经过三个步骤。
- 准备大量病人的CT数据集。其中既包括健康的,又包括得癌症的,并且每幅CT都需要标记好这个病人得没得癌症,称为标签。
- 根据图片和标签,训练计算机。用的方法就是让计算机的判断越接近标签越好。代价函数(objective function)在其中起到了重要的作用,代价函数就是当预测值与实际值不符合时给学习者的惩罚。试想你要让一个小朋友学习什么是苹果,就给他看一张苹果的照片,他说是梨,你给一个耳光,是桃子,给一个耳光,是樱桃,给一个耳光,直到他说是苹果,陪一个笑脸。下次再给另外一张苹果的照片,他可能还会犯错,但是慢慢的,为了让代价惩罚越来越小,小朋友就明白了什么是苹果。我们就是通过定义这样的代价函数来训练计算机的,让这个代价或者说是误差在学习的过程中变的越来越小。
- 测试这个计算机判断癌症的正确率有多大。这个阶段需要准备新的病人的CT数据集,当然也是标记好的。所谓的举一反三,就像期末考试一样,老师往往不会出平时讲课一模一样的题目,来判断学生到底掌握了没有。
总结一下,三步非常的清晰:准备数据,训练计算机,测试计算机。这就是目前主流的人工智能应用在实际问题中的步骤,对于用户来说,就只是使用训练完的“智能服务”即可,比如现在很火的指纹识别,人脸识别,自动驾驶等等,背后都是先经过了这样的三个步骤才可以提供服务的。
我们把上面的学习策略称为监督学习(supervised learning),也叫监督训练或者有教师学习,计算机通过已经提供的标签来学习。监督学习的概念很早的时候就广泛出现在了机器学习的领域,但是大部分研究都卡在了第二步和第三步,因为步骤2训练的模型不够好,导致步骤3的检验准确度不尽如人意,所以研究者又回到步骤2,就这样一直循环下去。由于近年来的神经网络算法和并行计算的改良,训练的计算机比以往大幅度的提升了,在很多领域甚至测试的时候准确度能超过人类专家的水平。这就是为什么近十年这样的监督训练模式会这么的火爆,人们称之为“深度学习”(deep learning)。
然而,深度学习能发挥这样的精度是有非常重要的前提的,那就是需要海量的步骤1中的标记数据,这也是它的致命伤。我给一个大概的描述,在计算机视觉领域,什么叫做“标记图像”,什么叫做“需要很多”。目前最大的标记数据集ImageNet有1400多万幅图片,涵盖2万多个类别。Microsoft COCO是物体分割的数据集,总共有超过32万幅图,里面的所有物体都人为地分割开了。这种数量和质量的标记数据,在医学图像,或者其他领域是很难达到的。而深度学习的方法因为其复杂性,当标记数据不够时常常没有办法匹敌一般的传统方法(图1),也就是很难达到人类的准确度,标记数据成为了深度学习应用落地的一个重要瓶颈。如何解决这个问题呢?



两个方向:
一、疯狂的找人标记
二、探索新的学习策略。
2. 被动学习与主动学习
先来讲第一个思路,找人标记。这个方法特别看决策者的水平,有些公司就是真的干花钱找人标记,特别的低效并且费钱,做的比较聪明的公司是通过自己的产品隐性地打标签,打个比方Facebook旗下的Instagram,这是一个类似微博的产品,用户在发表自己的照片的同时可以选择相关的标签(Tag),也相当于微博中的#话题#。这样Facebook每天都有大量的标签数据涌入,他们需要做的只是维护好这个生态,涌入的标签数据马上有用来训练他们的“人工智能”,反过来让Instagram更“懂”用户,整个产品生态得到一个良性反馈。当然这个标记数据集目前还没有公开,他们在上面已经开始做一系列的研究了(Exploring the Limits of Weakly Supervised Pretraining)。还有为了收集自动驾驶汽车的标记数据,智能导航,语音聊天等等,对应的公司都可以非常轻松的设计一系列的途径实现源源不断的得到隐性的标记。另外我发现非常聪明的标记方法是通过一些验证码。记得在登录一些网站的时候会出现,请挑出包含“猫”的图片,这样的验证,其实背后是一整套的投票标记策略,他们并不需要找人去真的标记,因为大部分人的答案都应该是正确的,换句话说,大部分的答案应该是一致的,那些和大部分人不一致的答案就是不正确,这个假设实现的前提是测试的样本足够多。所以那些验证图会多次的被不同的人标记,最终投一个票就能得到一个精度很不错的数据集了。这里隐约用到了“大数据”和“大数定理”的统计概念。有一个笑话是每次你看错Captcha验证码里的红绿灯,就有自驾车撞上一位行人(via Jonathan Libov)。最近朋友圈很火的小游戏,其中很大一部分也是为了收集数据的标签,聪明的决策者把这个让用户标记过程包装成好玩的游戏,或者抽奖,或者一些很微小的奖励,背后获得大量的标记数据。再举一个例子,有种手机app拍照不会摆POSE?Posing App软件来帮你,它专门负责指导用户摆pose,它会在相机屏幕上给出推荐的一系列pose的框架图,然后用户就按照草图摆pose即可。这个背后可以抓取大量的有用标签是么?比如哪儿是脸,哪儿是胳膊。像这样用非常聪明的方法来收集数据和标签,在我这儿是比较看好的“大数据”时代的策略,并且大有文章可做。

回到医学影像上,刚刚说的那些讨巧的方法可能在医学领域很难实现,主要原因是这不是普通人能完成的任务,所以不是设计产品正反馈的事儿。在医学影像的标记问题中,只有贵和更贵两个,比较幸运的是有些疾病专家是可以用肉眼看到并且给出正确判断的,比如肠道的早期肿瘤息肉检测(图2),但是更多的情况,是需要通过活体检验的,不是靠人眼就能完成的任务,这种标签,像我一开始的例子,判断得没得癌症,往往是活检的精标签,收集这种数据集真的能贵死。我们的最终目标是超过人类专家,所以在训练计算机的时候就不能用人类专家的标记,假设专家的准确度是60%,那么无论你训练一个多好的模型,最后撑死了也是60%,因此,需要大量活体检验的精标签。
更清晰地定义一下问题本身:
- 手头有很多没有标签信息的图片
- 由于人力和财力的限制,只能得到其中一部分的标签
在这种实际情况的设定下,我们如何更有效地利用“人工智能”?
我来介绍机器学习中,同样也是在人类学习中的两个学习策略:被动学习(negative learning)与主动学习(active learning)。学习有被动和主动之分,也就是所谓“要我学”和“我要学”之别。我们称传统意义上的机器学习,也就是先花钱把已有的数据全部标好,然后一股脑儿输给计算机,让它从中学习,这样的方法为被动学习,也就是学习的样本并不分主次,不分难易,不分先后地灌输。当然也有相对应的主动学习,即先花一部分的钱来训练计算机,然后根据计算机的反馈,有针对性地去把钱花在标记更重要的样本上,从而让学习者在短时间,短付出的情况下尽量地学到更多样,更有效地信息。这就是我们在2017年的CVPR中发表的工作【Fine-tuning Convolutional Neural Networks for Biomedical Image Analysis: Actively and Incrementally】想要传递的讯息。主动学习的核心问题是:如何定义对当前学习者来说更重要的样本?
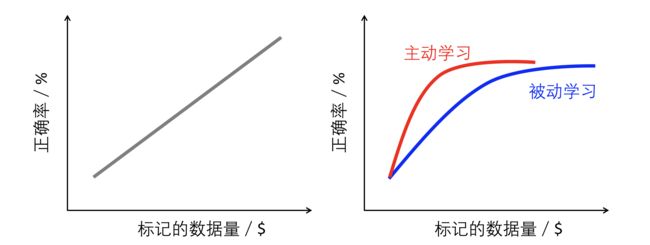
我们发现,如今深度学习下的监督学习真正的门槛变成了很简单概念——钱。这个钱有两个很重要的流向,一是计算机的运算能力(GPU Power),二是标记数据的数量。这儿就引出一个很重要的问题:是不是训练数据集越多,计算机的效果会越好呢?回答这个问题需要呈现的结果很简单,横坐标是标记的样本数,纵坐标是分类的准确度。一般来讲,人的惯性思维会引领一个默认的思路,就是训练样本越多越好,如图4左所示,这将直接导致许多工作的停滞不前,理由永远是“我们没有足够的数据,怎么训练计算机!”但是实际的情况是,你甚至可以花光所有的钱去标记数据,但是数据的增长对于计算机的智能程度存在一个天花板,越往后投入的钱的效益会越低,如图3右所示。对于很多从事深度学习的无论是研究员还是企业家都是一个十分有启发性的认知改变。了解了这一点,我们再利用主动学习的策略,可以进一步把这个饱和点前移,也就是标记尽可能少的数据来快速到达一个令人满意的精确度。
总结一下,对于暴力花钱标记,我们有两个策略:
- 建立一个产品的生态正反馈,用户在使用中不自觉提供的标签,进一步来优化计算机,回过头来提升产品的体验,更多的用户涌入,拿到更多的标签,实现“大数定理”下统计意义。
- 利用主动学习策略而不是被动学习策略来训练计算机,把资源用在刀刃上。
3. 迁移学习与自监督学习
回想一下一开始描述的监督学习三步骤,是不是感觉和媒体报道的有出入?媒体的描述是,人工智能现在已经逐步替代了人类,随着它进一步的自我学习,很快人类就完全跟不上计算机了,最终计算机统治地球。科幻片也是这么说的,只要人类打开了计算机自我学习的潘多拉魔盒,就一发不可收拾了。你会发现,根据我的描述,只要不给计算机标好的数据,它就什么也不学不了,并且一旦停止给新数据,计算机根本不会自动迭代。回看“人工智能”这个词,它既可以理解为由人类编写,设计,改进的“智能”,人工是定语,也可以理解为两个阶段,“人工”和“智能”。前面我们提到的监督式学习,有大量的劳力体现在“人工”标记上,这样的人工是计算机智能的前提,所以有人说现阶段的人工智能实际上是“有多少人工,就有多少智能”。并不是我们所期望的真正的智能体——广义人工智能( Artificial general intelligence)。并且现有的模型在少数据的情况下的精确度完全没有办法相信,例如大量的医学影像应用。是可以在小范围数据集上得到不错的结果,但是还远远没有办法保证临床的新样本的判断精度。因此需要拓宽新的方法,来摆脱监督式学习的限制。
想一想人类的学习过程就不难发现,这种大量的标记行为是很不自然的现象,人类,或者其他动物,在认识和理解世界的时候,并没有谁会给每个事物都打上标记,而是完全靠自己的视觉系统自发地分辨不同的东西。很多的基础视觉训练在学前就已经形成了,只不过是在上学后老师告诉你这个物体我们人类叫它什么名字。比如苹果和香蕉,孩子是可以很早就清晰分辨的,只是上学了以后书本上说这个的名字叫“苹果”,那个的名字叫“香蕉”,所谓的标签,也可以是这个的名字叫“apple”,那个叫“banana”,甚至把他们的名字调个个儿。再比如,图4中的数字09学习,人类通过肉眼是可以根据它们的形态进行分辨的,只是在上学前,你不知道它们的学名是什么,然后老师告诉你这一类像圈的学名是“0”,那个像个杆子的学名叫“1”,也就是给了它们各自一个易于交流的标签。你会发现对于人来说,标签的名字根本就是无关紧要的,给他什么名字都行,它并不真正包含在我们的视觉认知系统中,而是我们先学会分辨,然后为了方便交流给了它们一系列的名字(代号)罢了。像这样的先分辨,再给标签的视觉认知方法大量存在在学前训练中。如果人眼一秒可以捕捉到24张图(人眼是否存在「视觉频率极限」?),那么在十岁之前,假设每天平均有12个小时视觉系统在工作,那么总共不自觉处理过的照片数目高达3,784,320,000张(2436001236510),十岁以后也在持续不断的做这种处理,这种自然界中常见的在没有人工标签下的视觉训练称为预学习(Pre-training)或者表征学习(Representation Learning),这部分的学习往往被很多研究者忽视,误以为人类在认知一个物体时所需要看的图其实并不多。确实,当老师给出一些平常我们不能用肉眼的视觉系统感知并自发学习到的物体,比如细胞,CT影像,天体时,我们只需要看几张不同的图就可以大概了解并能分辨出他们。但是前提是学习者已经经过来大量的表征学习,如果把十张不同的细胞放在刚出生的婴儿眼前,是不可能这么轻易地学习到的。当人类第一次用肉眼见到放大的细胞图片时,首先做的就是类比,把这个完全陌生的东西和已经了解到东西进行对比来学习它。比如,细胞长的是一个球形,首先会联想到桃子,然后看到细胞里面有核,联想到桃核,慢慢的通过对比细胞这个新事物和我们熟悉的桃子的差异,真正掌握到什么是细胞这个概念。其实对于细胞整体的视觉理解是先于对它内部结构的命名的,像细胞,线粒体,细胞质等等。所以对于复杂的专有名词(像肿瘤,细胞),我同意视觉认知是可以实现少样本学习的,但是前提是有大量的表征学习过程。诟病“深度学习需要太多标签数据”的说法,问题不在于数据量本身,而在于表征学习过程是否需要标签。如果能做到表征学习是多样本的非监督,或者弱监督,后续的学习是少样本的强监督,这是非常自然,高效,而且节约的视觉学习策略。我们称这种根据已知的知识去类比学习未知知识的学习策略叫迁移学习。

迁移学习(Transfer learning) 顾名思义就是把已经在一个领域学习好的模型迁移到新的一个领域,来帮助模型训练。就是牛顿的那句话:“如果说我看得比别人更远些,那是因为我站在巨人的肩膀上”。如图4,一般来说,从问题A迁移到问题B的过程,A往往是拥有大量的标记数据,比如自然图像,而B就是那种很少能拿到足够多标记数据的领域,比如医学影像。我们希望计算机可以通过学习自然界常见的物体,来帮助它学习到事物之间细微的差别,也就是每种事物的特征,然后更容易地类比学习不那么常见的物体。迁移学习策略在人工智能中讨论非常火爆的。
目前最普遍和最好用的迁移学习模式是:
- 用监督学习在大量标记的自然图像(ImageNet)中训练(表征学习),图4A
- 用监督学习再在少量标记的目标领域训练,图4B
两个过程,从领域A学习到知识,迁移到领域B,融会贯通,得到的结果比直接从领域B学要好不少。我们称在领域A中的学习为表征学习(Representation Learning),原因是我们希望计算机可以在这个普遍的数据集上学习到一些比较抽象的视觉特征。刚刚我阐述了,对于不常见的物体,或者比较难理解的新物体,我不反对用监督式学习的策略。但是我不是很同意应该用监督式学习来做表征学习。
关于为什么表征学习不应该用像ImageNet中一对一标签式的监督学习?
我能想到的理由有两点(欢迎补充):
第一点,人类视觉系统的形成和发展其实大量的训练都不是“一对一“打标签,然后监督学习的结果。像刚过提到的一样,没有谁会给大自然的任何物体去打标签。你会发现,其实在老师告诉我们这个叫“苹果”,那个叫“香蕉”之前,这两个概念早就在我们的认知系统中划分成两个类了,人为的标记只是发生在我们认知之后,对于表征学习来讲这样的标记是无关紧要的。更直观的说法是,人类的视觉系统已经自发地学习到如何把不同的东西聚类,只是不知道每个类代表什么名称,后续的标签过程实质上就是给每个聚类中心了一个名称而已。
第二点,在表征学习的过程中,人为的标签(比如ImageNet)是低效的,并且会引入大量的冗余,错误和偏见。图片级的标签(image-level annotation)其实是一个很奇怪的东西,一幅图里面明明可能包含很多物体,却人为的只给了一个标签(one-hot vector)。例如图中有猫和狗的情况,但是标签却只包含了猫,这对于狗类别就是一个错误的标记。当然有人说可以改进嘛,在标记的时候不用one-hot vector,而是标上全部包含的标签。那也有问题,比如你如何去定义标签集,因为这个世界上的标签是没有办法穷举的,难道只标记那些关心的或者能够想到的标签,其他的物体都不管了?为什么要提这个事情呢?因为表征学习学的其实是图像特征,我们希望学到的特征是普遍适用的,但监督式学习无形中会扰乱这种特征,拿CAM(Class Activation Map)来举例,如果一幅图包含了多个目标,但是只标记了其中的一个目标,得到的特征CAM就会对这个目标产生偏见,而对其他的目标完全置之不理。
关于为什么我认为表征学习不应该是现在的监督式学习模式(像ImageNet的一对一标签),我还需要更多的思考,现在只是直觉判断。要是这个statement不能很清晰地阐述,随之而来的假象,实验,结论,论文都没有意义。
因此,理想的表征学习应该是不同于监督学习的另一套机制。
长尾分布:少量的类有大量样本,大量的类有少量样本。
通过学习大量的样本(头部),来迁移到少量样本的学习(尾部)。
如何从图像本身学习到有效的信息呢?我想着重介绍的就是自监督学习(Self-supervised Learning),它的目标就是让计算机像人一样的学习,真正能学习到本质的,或者普遍适用的特征。它的强大之处在于两点:
- 让计算机去学习某种映射关系,某种物理关系,而不是简简单单的学习标签
- 不需要人为的去标记,而是通过一定的规则去从数据本身中挖掘信息
现在问题的焦点集中在如何设计一个有效的表征学习?更本质的问题在于如何让计算机通过处理大量的图片,来学习到物体间内在的,抽象的特征?

举例,autoencoder就是最简单简单的自监督学习,Hinton早在2006年就把它发表在了Science上了( Reducing the Dimensionality of Data with Neural Networks),一幅图经过了编码-解码器,最后还是回到这幅图本身。试想一个1M的图像,经过编码变成了一个很小的向量,这个向量很小,可能只有几个K,它是原图丰富特征的抽象表征,储存起来特别的省空间,当我们想看原图的时候,只需把这个小小的向量放到解码器即可,理想情况下,1M的图像又回来了。就像饼干,你用一个编码器把它变成压缩饼干,想吃的时候用解码器再把它恢复原样。像金箍棒,不用的时候用编码器把它变小放耳朵,用的时候解码成那么大。通过编码解码的过程,让计算机学习到输入图像的特征。


这个思想一开始被广泛用在自然语言处理领域,叫做word embedding,假设是两个词靠的比较近,就意味着他们在语义特征上存在联系,从而可以对不同的词做一个初步的概率统计分析,这种先验知识对于后续的一系列问题会产生很大的帮助。


再举例,去噪。人为的在图片中加入噪声,然后通过训练模型来去燥,在去燥的同时学习到图片中的特征信息。再如,填色,给一幅黑白的图片,让模型学习给它上色,来学习特征。另外还有学习还原拼图等等。你会发现,在设计这些学习策略的过程中,我们是真正的在考虑或者模拟孩子的学习过程,这些自监督学习方法都可以在新华书店的儿童柜台买到,比如填色,找不同,拼图这样的启蒙游戏。自监督学习的核心问题是:如何从数据本身中找到有效的映射,来帮助计算机学习普遍适用的特征。
近年来,深度学习的研究者们在思考去打造一个不需要大量人工标签来做监督学习,但是需要人类智慧去找到一个引导的方法让计算机自我学习的途径,从而实现真正的“人工智能”。这里的人工将不再是人工标记,而是人工设计,或者人工引导,相比之下它的代价就变的非常之小,让计算机能像人一样的学习是我们的目标。同时,这也是一个对人工智能来说的进步,一般说来,计算机对人类的优势在于运算而不是理解,就像计算器的速度和精度很早就超过了人类,还有搜索,到现在的识别,下围棋,打游戏,都是在规则下的运算,所以像这些任务,计算机超过人类是很正常的。往往这些任务对人类来说,需要经过大量的监督训练,通常是这方面的专家才能完成。但是目前的人工智能在理解层面还远不如人类,这些任务却是人类潜意识就能很容易解决的事情,甚至是与生俱来的能力。
4. 结语
讨论的核心问题是:如何克服深度学习需要大量标签数据的技术瓶颈?提到了两个解决方案,第一是沿着选择的监督式学习的思路,找人大量地标记数据,聪明地去收集数据,聪明地去训练计算机。第二是探索人类的视觉系统认知模式,使用迁移式学习和自监督式学习,从根本上克服大量标签数据的问题。