tensorflow实现风格迁移
风格迁移主要的就是两个损失,一个是内容损失,一个是风格损失,论文使用vgg19做实验,内容损失是在conv4_2上将原始图片在vgg19该层的输出与我们想要生成的图片在该层的输出计算内容损失,风格损失是风格图片和我们想要生成的图片在’conv1_1’, ‘conv2_1’, ‘conv3_1’, ‘conv4_1’, ‘conv5_1’这些层的风格损失求和求平均,首先我们看下内容损失如何计算:

他就对应像素点做差的平方和,实现代码看如下:
def content_loss(layer_name,sess,net):
p = sess.run(net[layer_name])
x = net[layer_name]
loss = 0.5*tf.reduce_sum(tf.pow((p-x),2))
return loss风格损失计算公式如下:

其中计算gram矩阵公式如下:
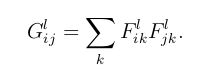
其中gram矩阵的计算就是相当于每层输出的任意两个通道做点乘,包括自己和自己,风格损失的计算方法就是,先求风格图像在卷积的输出的gram矩阵,在求我们所要生成的图片的gram矩阵,然后在算风格损失,也是对应gram矩阵对应元素做差的平方,最终的损失函数为:

这就是总的损失,其中alpha越大,生成的图像和原始图像越像,beta越大,生成图像和风格图像更加接近。
手先是定义vgg19的模型,代码如下:
def get_weight_bias(vgg_layers, i):
weights = vgg_layers[i][0][0][0][0][0]
weights = tf.constant(weights)
bias = vgg_layers[i][0][0][0][0][1]
bias = tf.constant(np.reshape(bias, (bias.size)))
return weights, bias
def build_net(layer_name,inputs,nwb=None):
# net_type 需要定义网络层的名字
if layer_name == 'conv':
out = tf.nn.relu(tf.add(tf.nn.conv2d(inputs,nwb[0],[1,1,1,1],'SAME'),nwb[1]))
elif layer_name == 'pool':
out = tf.nn.max_pool(inputs,[1,2,2,1],[1,2,2,1],'SAME')
return out
def bulit_vgg19(path,image_shape):
net = {}
vgg_rawnet = loadmat(path)
vgg_layers = vgg_rawnet['layers'][0]
net['input'] = tf.Variable(np.zeros(image_shape).astype('float32'))
net['conv1_1'] = build_net('conv', net['input'], get_weight_bias(vgg_layers, 0))
net['conv1_2'] = build_net('conv', net['conv1_1'], get_weight_bias(vgg_layers, 2))
net['pool1'] = build_net('pool', net['conv1_2'])
net['conv2_1'] = build_net('conv', net['pool1'], get_weight_bias(vgg_layers, 5))
net['conv2_2'] = build_net('conv', net['conv2_1'], get_weight_bias(vgg_layers, 7))
net['pool2'] = build_net('pool', net['conv2_2'])
net['conv3_1'] = build_net('conv', net['pool2'], get_weight_bias(vgg_layers, 10))
net['conv3_2'] = build_net('conv', net['conv3_1'], get_weight_bias(vgg_layers, 12))
net['conv3_3'] = build_net('conv', net['conv3_2'], get_weight_bias(vgg_layers, 14))
net['conv3_4'] = build_net('conv', net['conv3_3'], get_weight_bias(vgg_layers, 16))
net['pool3'] = build_net('pool', net['conv3_4'])
net['conv4_1'] = build_net('conv', net['pool3'], get_weight_bias(vgg_layers, 19))
net['conv4_2'] = build_net('conv', net['conv4_1'], get_weight_bias(vgg_layers, 21))
net['conv4_3'] = build_net('conv', net['conv4_2'], get_weight_bias(vgg_layers, 23))
net['conv4_4'] = build_net('conv', net['conv4_3'], get_weight_bias(vgg_layers, 25))
net['pool4'] = build_net('pool', net['conv4_4'])
net['conv5_1'] = build_net('conv', net['pool4'], get_weight_bias(vgg_layers, 28))
net['conv5_2'] = build_net('conv', net['conv5_1'], get_weight_bias(vgg_layers, 30))
net['conv5_3'] = build_net('conv', net['conv5_2'], get_weight_bias(vgg_layers, 32))
net['conv5_4'] = build_net('conv', net['conv5_3'], get_weight_bias(vgg_layers, 34))
net['pool5'] = build_net('pool', net['conv5_4'])
return net
定义我们需要使用到的函数,放在utils.py中:
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
mean = np.array([[[[123.68, 116.779, 103.939]]]])
def save_image(img,path,iter):
image = img+mean
image = np.squeeze(image,0)
image = image.astype('uint8')
image = Image.fromarray(image)
image.save(path+'gen%d'%iter+'.png',format='png')
def load_images(path,img_shape):
img = Image.open(path)
img = img.resize((img_shape[1], img_shape[2]))
img = np.asarray(img)
img = img[np.newaxis,:]
img = img - mean
return img
def gen_noise_img(image_shape,content_image,ratio=0.6):
noise_img = np.random.uniform(-10,10,image_shape)
noise_img = noise_img*noise_ratio + content_image*(1 - noise_ratio)
return noise_img
def content_loss(layer_name,sess,net):
p = sess.run(net[layer_name])
x = net[layer_name]
loss = 0.5*tf.reduce_sum(tf.pow((p-x),2))
return loss
def gram_matrix(x):
M = x.shape[1] * x.shape[2]
N = x.shape[3]
g = tf.reshape(x,[-1,N])
G = tf.matmul(tf.transpose(g),g)
return G
def count_style_loss(g,a):
M = g.shape[1]*g.shape[2]
N = g.shape[3]
A = gram_matrix(a)
G = gram_matrix(g)
return 1/(4*N**2*M**2)*tf.reduce_sum(tf.pow((G-A),2))
def style_loss(layers,sess,net):
loss = 0
for layer in layers:
g = sess.run(net[layer])
a = net[layer]
loss += count_style_loss(g,a)
return loss/len(layers)然后是训练的train.py文件具体如下:
import tensorflow as tf
from scipy.io import loadmat
from build_model import bulit_vgg19
from utils import*
vgg_weight_path = 'imagenet-vgg-verydeep-19.mat'
save_img_path = './out'
image_shape = [1,512,512,3]
style_pic_path = './styles/picasso.jpg'
content_pic_path = './pic/nn.jpg'
content_layer = 'conv4_2'
style_layer = ['conv1_1', 'conv2_1', 'conv3_1', 'conv4_1', 'conv5_1']
alpha = 1
beta = 300
lr = 1
iterations = 1000
style_img = load_images(style_pic_path,image_shape)
content_img =load_images(content_pic_path,image_shape)
gen_img = gen_noise_img(image_shape,content_img,ratio=0.6)
vgg_net = bulit_vgg19(vgg_weight_path,image_shape)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
sess.run([vgg_net['input'].assign(content_img)])
loss_content = content_loss(content_layer,sess,vgg_net)
sess.run(vgg_net['input'].assign(style_img))
loss_style = style_loss(style_layer,sess,vgg_net)
total_loss = alpha*loss_content+beta*loss_style
optimizer = tf.train.AdamOptimizer(lr).minimize(total_loss)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
sess.run(vgg_net['input'].assign(gen_img))
for iter in range(iterations):
sess.run(optimizer)
if iter%100 == 0:
gen_pic = sess.run(vgg_net['input'])
gen_pic = gen_pic
save_image(gen_pic,save_img_path,iter)
print('have save %d' % (iter / 100 + 1))
这就是风格迁移了,附上我自己跑的几张图像。

