BigGAN
论文:LARGE SCALE GAN TRAINING FOR HIGH FIDELITY NATURAL IMAGE SYNTHESIS
Github:https://github.com/AaronLeong/BigGAN-pytorch
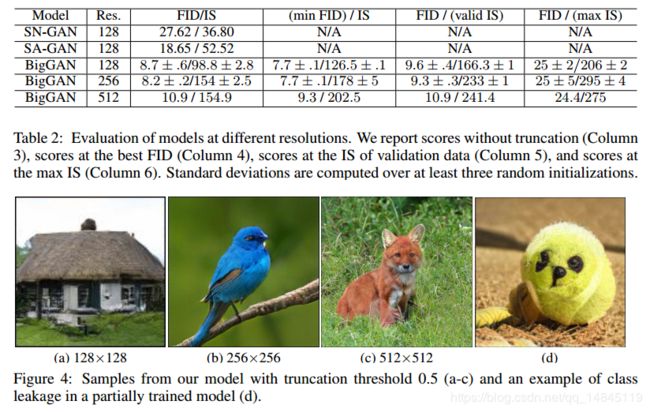
BigGAN作为GAN发展史上的重要里程碑,将精度作出了跨越式提升。在ImageNet (128*128分辨率)训练下,将Inception Score (IS,越大越好) 由之前最好的52.52提升到166.3,Frechet Inception Distance (FID,越小越好) 由之前最好的18.65提升到9.6。

论文贡献:
- 通过2-4倍的增加参数量(增加channel),8倍的扩大batchsize,可以使GAN获得最大的性能提升。
- 通过使用截断技巧(truncation trick),可以使得训练更加平稳,但是需要在多样性和逼真度之间做平衡。
- 通过现存的和其他新颖的各种技术的集合,可以保证训练的平稳性,但是精度也会随之下降,需要在性能和训练平稳性之间做平衡。
背景知识:

其中,Z为服从正态分布N (0; I) 或者均匀分布U[-1; 1] 的随机噪声。
Batchsize和channel number增加:

Batch:batch size
Ch:channel
Param:参数量
Shared:使用共享嵌入(shared embeddings ),在生成器的BN层中加入类别信息嵌入,将会大大的增加参数量,因此选择共享嵌入,也就是对每层的weighs和bias做投影,这样将会减少计算和内存的开销,将训练速度提升37%。
Hier:使用分层的潜在空间(hierarchical latent space ),也就是在生成器网络的每一层都会被喂入噪声向量。分层空间增加了计算量和内存消耗,但是可以使得精度提升4%,训练速度加快18%。
Ortho:使用正交正则化(Orthogonal Regularization )
最原始的正交正则化如下面式子,
![]()
其中W为权重矩阵,β 为超参数。
论文通过将对角线的元素全部去掉,实现了对其的改进,即放松了截断的限制,也保证了模型的平滑性。
改进的式子如下,
![]()
其中,1表示一个全部为1的矩阵。
Itr:迭代次数
FID:Frechet Inception Distance,表示生成图像的多样性,越小越好
IS:Inception Score,表示生成图像的质量,越大越好
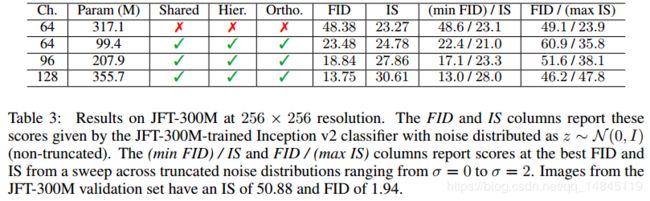
从上图可以看出,随着batchsize和channel数的增加,精度越来越高,同时论文还验证将深度增加为原来的2倍,将会使得性能下降。
截断技巧(truncation trick):
所谓的“截断技巧”就是通过对从先验分布 z 采样,通过设置阈值的方式来截断 z 的采样,其中超出范围的值被重新采样以落入该范围内。

(a)从左到右依次增加截断的区间,阈值分别为2,1.5,1,0.5,0.04,可以看出随着截断区间的增加,生成图像质量(FIDELITY )越来越高,但是多样性(VARIETY )越来越差。
(b)对较弱的模型使用截断会带来饱和想象(伪影)。为了解决该问题,问题引入了正交正则化的改进版。
特征的平稳性:
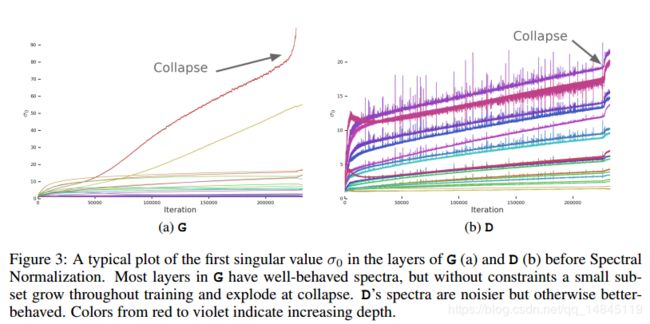
横轴为迭代次数,纵轴为频谱参数σ0 ,其中不同的颜色的曲线表示不同的层,从红色到紫色深度不断增加。
(a)表示生成器,大部分的层训练中参数σ0表现的很平稳,当然有一些层的参数会爆炸。
(b)表示判别器,大部分的层都有很大的噪声
生成器特征的平稳性:
在对权重矩阵进行奇异值分解,前3个值(σ0,σ1,σ2 ),对每个矩阵具有最大的影响。
因此,首先考虑对σ0进行正则化操作。
![]()
V0,u0表示奇异值向量,σclamp或者被设置为固定的值σreg 或者被设置为r · sg(σ1) ,表示σ1的的r倍。
最终结果,不管有无频谱归一化(Spectral Normalization ),这样的改进都可以提升训练的平稳性,但是不能解决爆炸的问题。因此论文对判别器进行改进。
判别器特征的平稳性:
论文假设频谱噪声是导致训练不平稳的因素,因此很自然的想法是进行梯度惩罚,通过对R1进行0均值的正则化惩罚来进行改善。
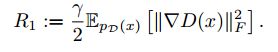
其中,r表示常数,10。
论文实验表明,惩罚越大,训练越平稳,但是精度也越来越低。
网络结构:

网络基于ResNet进行了修改,每一个block的输入和输出都相等。
网络输入为N (0; I)的正态分布。
左侧实心线c表示共享嵌入(shared embeddings ),右侧实心线表示分层的潜在空间(hierarchical latent space )。(a)表示整体网络结构,(b)表示每个block结构。
实验:
IMAGENET实验:
JFT-300M实验:
负面结果:
- 增加网络深度会使得精度降低。
- 在判别器上使用贡献嵌入参数的方法,对参数的选择非常敏感,刚开始有助于训练,后续则很难优化。
- 使用WeightNorm 替换BatchNorm 会使得训练难以收敛,去掉BatchNorm 只有Spectral Normalization 也会使得难以收敛。
- 判别器中增加BatchNorm 会使得训练难以收敛。
- 在128*128的输入情况下,改变attention block对精度没提升,在256*256输入的情况下,将attention block上移一级,会对精度有提升。
- 相比采用3*3的滤波器,采用5*5的滤波器会使精度有略微提升,而7*7则不会。
- 使用膨胀卷积会降低精度
- 将生成器中的最近邻插值换为双线性插值会使得精度降低。
- 在共享嵌入中使用权值衰减(weight decay),当该衰减值较大(10-6 )会损失精度,较小(10-8 )会起不到作用,不能阻止梯度爆炸。
- 在类别嵌入中,使用多层感知机(MLP)并不比线性投影(linear projections)好。
- 梯度归一化截断会使得训练不平稳。
总结:
BigGAN是GAN发展史上新的里程碑,论文贡献包括,大batchsize,大channel数,截断技巧,训练平稳性控制等。