kaggle 蛋白质 第一名kernel 解读1
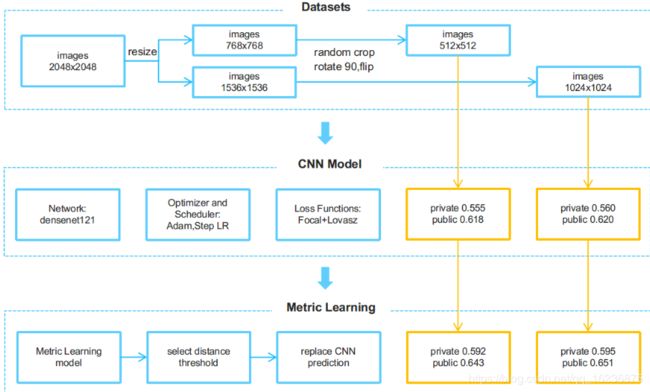 挑战: 数据极度不平衡,稀有的类别难以训练和预测,但是对得分有非常重要。
挑战: 数据极度不平衡,稀有的类别难以训练和预测,但是对得分有非常重要。
数据的分布在训练集,测试集以及hpa v18 额外数据集中都非常不平衡。
图像质量高,但是必须在模型效率和准确性之间找到平衡点。
用CNN 验证:
根据https://www.kaggle.com/c/human-protein-atlas-image-classification/discussion/67819的说法,我发现整个Val 集合的Focal loss 对模型能力是一个很好的度量,F1 并不是很好因为它对阈值敏感,阈值取决于训练和Val 集的分布。
我试图通过设定训练集中每个class 的比值一样来评估模型的能力,我这样做是因为我认为我不会通过公共的LB 来调整阈值,但是如果设置稳定的预测的比例, 如果模型更强,分数就会提高,也就是说,我把公共的LB 作为了另外一个验证集。(不懂)
数据增强:
翻转90 度,从768 *768的图像中随机生成512*512 的图片(或者从1536 *1536的图像中随机生成1024*1024的图片)
数据预处理:
从v18 中删除6000个重复的样本,用hash 方法去找测试集中的相同的(是说test 数据集中会存在train 的图片吗)
计算训练集+测试集的均值,在把图片放到模型中前使用它们(怎么使用?)
模型训练:
优化器:Adam
学习率:
Scheduler:
lr = 30e-5
if epoch > 25:
lr = 15e-5
if epoch > 30:
lr = 7.5e-5
if epoch > 35:
lr = 3e-5
if epoch > 40:
lr = 1e-5Loss:FocalLoss+Lovasz,我没有使用 macro F1 soft loss 因为batch size 很小,有些类很少见,我认为它不适合这次比赛,lovasz损失函数 可以在一定程度上平衡Recall 和precision。
我没有用过采样。
我最好的模型是densenet121 ,它非常的简单,模型的头部几乎是和它一样的。https://www.kaggle.com/iafoss/pretrained-resnet34-with-rgby-0-460-public-lb

我根据多标签分类文件尝试了各种网络结构,结果并没有因为结构的不同而提高。
预测数据集增强:
在最好的focal loss 的epoch 下,我用4 随机数随机地从768*768 的图片截取512*512 去预测测试集,并从预测中得到了最大的概率。
后处理:
在比赛的最后阶段,我决定提出两个建议:
1 保持公开测试集标签的比例,因为我们不知道稀有的class 的比例,所以把它们设置为和train 一样的
2 第二个是保持 训练数据集和测试集平均的标签比例。
原因是我试图通过2-5 个样本来减少或增加稀有类别的数量,公共的LB 可以提高,但是这是一个危险的方式,我只是用它来苹果可能的摇摆。
度量学习:
我再2015 年5 月参加了 landmark recognition challenge,我曾计划在该比赛中使用度量学习,但在我完成TalkingData competition 比赛后时间有限。但我读了很多相关的论文,之后做了很多实验。
当我分析的模型的预测时,我想找到最近的样本进行比较,我首先使用了cnn模型的特征,我发现它们不是很好,所以我决定尝试度量学习。
我发现在这个比赛中训练非常困难,花了我很多时间但是结果不是很好,我发现同样的算法在鲸鱼识别比赛中可以很好的发挥作用,但我并没有放弃,最后两天终于找到了一个好的模型。
通过使用模型,我可以在验证集上找到最近的样本,top1的精度>0.9
以下是演示:
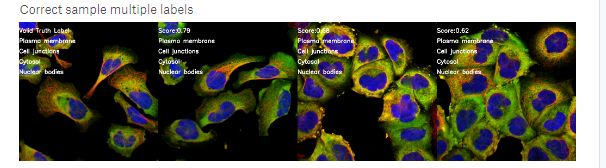
单标签的正确样本:

多标签的正确样本:
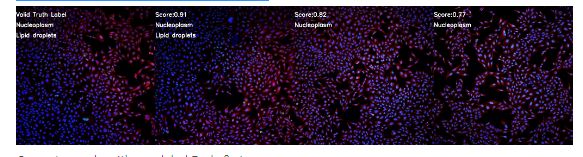
有稀有标签的正确样本:脂滴
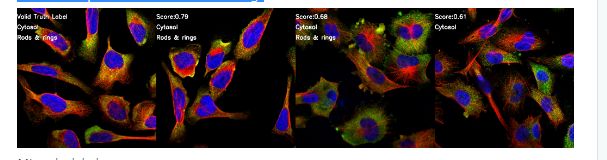
有稀有标签的正确样本:棒和环
缺了一个标签:
错误的添加了一个标签
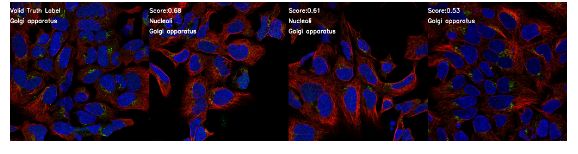
自从top1的精确度>0.9,我想可以用度量学习的结果来设置测试集的标签。但是我发现测试集与v18有点不同,有些样本在训练集和v18中找不到最近的邻居。所以我设置了一个阈值,用找到的样本来替换标签。幸运的是,阈值对阈值不敏感。在测试集中替换1000个样本与替换1300个样本的分数几乎相同(不懂)。这样,我的分数就能提高0.03+,这在这次比赛中是一个巨大的进步。
我认为我的方法是重要的,不仅提高分数,而且能以下面的方式帮助hpa和他们的用户:
1.当有人想给图片贴上标签或学习给它贴上标签或检查其质量时,他可以找到最近的图片供参考。
2.我们可以用度量法对图像进行聚类,找出标签噪声,然后提高标签的质量。
3.我们可以通过可视化预测来解释为什么模型是好的。
融合:
为了保持解决方案的简单,我在这里不讨论融合,一个单一的模型甚至一个折叠+度量学习的结果是足够得到第一名的。
在lb上的分数:
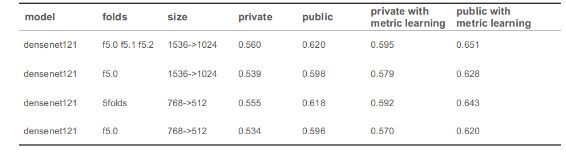
很抱歉,我现在无法描述这部分的细节,正如我之前提到的,鲸鱼鉴定比赛仍在进行中。
回复总结:
1 使用的是 imagenet pretrained 的weight
2一个分类模型和一个度量学习模型,然后在分类步骤中,如果测试图像与培训集中的图像之间的距离低于某个阈值,则使用度量学习模型;如果距离高于阈值,则使用分类模型。
3 梯度积累对这个比赛没有帮助
4 Prediction time augmentations的时候:Did you use only the crops with max probability out of several crops inferenced with the same model? Or several crops with several folds? Did you just used max or votes between the crops?
ame fold,several crops,max probability from the predictions.( 不懂)
5 数据集中有些类,如细胞动力学桥,以一种非常局部的方式出现,每个图像只有一到两次。
你是如何避免这些区域(细胞动力学桥)被随机的裁剪从图像中去掉的?
我可以计算出,在tta中的max(概率)足够解决这个问题的……训练这样一个不平衡的数据集不是更糟的吗?
根据经验,训练集数据增强能很好地避免过拟合,有些标签的噪音没有多大的影响,对于测试集,最大概率可以解决标签缺失的问题。
6 我在想你能不能详细解释一下TTA,对于最大的概率。有的一张图片可能有超过4类,从4个crops 中选择最大prob也只会有4类,你如何绕过这个?
如果批次大小是b,4 crops的概率结果将是bx4x 28,max1(检验结果1概率值)将返回bx28向量,在对结果施加阈值后,我们可以得到每个样本的标签。
7 没有使用过采样的原因是提高不了分数吗还是单纯没有做,对于metric learning:你有这个数据集用siamese or triple-net (like anchor-positive-negative) ?“我设置了一个阈值,用找到的样本替换标签。幸运的是,阈值对阈值不敏感。” 这句话不理解
(1)根据我的经验,通过过采样会改变一些类的概率,但不大幅度的提升模型的能力,真正的问题一个类的概率上,问题是他们的顺序不一致。但是,我必须说,我没有做实验来验证它。也许我会在其他比赛中使用oversample,例如,在鲸鱼比赛中,ovdersample 非常耗费时间,比赛需要找到一个最有希望的方法。
2)不想说太多
3).我必须决定更换哪些样本,所以我设定了一个距离,也就是0.35,如果距离小于0.35,那么我就用v18中找到的样品替换标签。如果我把阈值设为0.3,那么lb的分数不会有太大的变化,我们可以说,它对阈值不敏感。因为在选择cnn模型的阈值时,我并没有试图过度去过拟合public lb,所以我可以说,我的解决方案在整体上对阈值不敏感。
8 Andrew Ng's Deep Learning Course on Coursera introduces Siamese network and Triplet Loss,I remember it's Part 4.2-4.5
metric learning,I invite you to the Whale identification challenge,you will find some kernels useful https://www.kaggle.com/c/humpback-whale-identification/kernels.
9 对于第一阶段的cnn模型(在度量学习之前),您如何选择测试预测的阈值?
请参考“后处理”部分的解决方案,选择阈值以确保在一个类中有一定数量的样本。所以我有28个门槛。
10 有什么特别的原因可以解释DenseNet 的表现胜过了resnet34或是Incep tionResNet50的?另外模型选择的要点是什么呢?
你能告诉我为什么你选了丹尼塞特吗?
通常从一个简单的网络开始,比如resnet 18,我几乎做了所有的实验。然后我将把模型结构和参数,增强...转移到resnet 3434,再到resnet 50。如果时间足够的话,我会试试densenet,初始化,inception v3。
我喜欢resnet,resnet 50的结果也不错,但在这次比赛中,densenet表现得更好一些。
在选择模型时,如果数据集很大,我会选择大的和深的模型,但我也会从resnet开始
11 如何找到测试和val 中最近的样本的?
我训练了一个模型,为每个样本生成一个向量(rgby-4通道),然后计算出每个val/测试集样本和每个train/v18样本之间的距离,并对距离进行排序,然后我就可以得到每个val/测试集样本的最近样本。
12 你有用pretrained models吗(especially for your lr schedule)
是的,我使用了预先训练过的模型, lr schedule 是ok的,我没有尝试太多其他的选择,我通常比较注意数据和grain-val损失的关系。
13 你通过train+testing example的平均值和STD来标准化数据,并且还可以使用一个预先培训的模型。在训练预训练的模型,您是否再次使用图像的平均值和STD来缩放数据呢?
14 我正在尝试使用focal loss,但是它收敛很慢。我在5个epoch 后得到4.1。你是怎样使用gamma and alpha? (I used 2 and 0.25)
我使用focal loss,模型收敛迅速,唯一的问题是过度拟合训练集,所以我添加了crop augment and 512x512 image size,focal损失代码我在这里给你参考。

、不确定是否如预期的那样工作。它收敛得很快,100 epoch 之后损失是0.05,所以这里一定有什么问题。