目标检测网络的感性认识(一)之演进之路RNN、SPPNet
目录
Faster-RCNN简述
RCNN网络
SPPNet网络
Faster-RCNN简述
Faster-RCNN是目前two-stage的代表作之一,首提于2016年。
进化之路:RCNN(第一个利用深度学习特征来完成目标检测的模型)->SPPNet->Fast-RCNN->Faster-RCNN
奠定了two-stage进行的传统目标检测的基本框架即:
首先,输入一幅图像,然后,从这幅图像中提取一些候选框(可以采用滑动窗口的策略或者选择性搜索的策略),接下来针对于提取出来的候选框来提取特征,并且针对提取出来的特征来进行分类进而确定目标和背景的判断,最后,对提取的候选框得到置信度的平分和iou,作为NMS的输入,利用该算法,来进行过滤和筛选,来得到最终的结果的输出。

RCNN网络
背景:传统目标检测遭遇了很大的瓶颈。
整体框架沿用传统的目标检测框架,区别在于,在提取出候选区域之后,通过卷积神经网来完成特征的提取,代替了原先的颜色、纹理等低层次的视觉特征。
缺点:1)候选框选择算法耗时严重(因为还是沿用传统的目标检测框架)
2)重叠区域特征重复计算(对每个候选区域,都用一个CNN网络进行预测,如果两个候选区域重复,那么会累加无效的计算)
3)分步骤进行,过程繁琐(先CNN,再SVM,最后再Reg,过程复杂)
首提于2014年。
宏观流程:
SETP1:采用预训练模型(AlexNet)
SETP2:模型做fine-tuning,更改的地方有:
(1)将输出类别由1000更改为20(因为用的是VOC训练集的缘故,只有20个类别)。
(2)将FC层去掉(因为AlexNet的分类任务是面向1000个对象进行的,而在目标检测的过程中,最终需要分类的总类别数=20(类别)+1(背景),预训练得到的FC层的参数与实际需要的参数不同),只保留AlexNet主干网络层。
SETP3:特征提取:
(1)采用选择性搜索的策略(并非滑动窗口,因为要考虑滑窗的步长跟大小,要计算候选区域,会造成时间上的效果,降低效率)
选择性搜索的策略流程:
setp0:采用区域分割的模型(对整个图进行区域分割),进而得到一系列的分割好的区域(这些区域往往是图像中某些可能的物体),组成区域集R。
setp1:计算区域集R里面每个相邻的区域的相似度S={s1,s2,...,},且找到相似度最高(通过颜色、纹理等低层次的视觉特征来进行 )的两个区域,将其合并成一个新的区域。将其合并为新区域,添加进R。
setp2:将R中与setp1中获得的有关子集从S中移除出去。
setp3:计算新集R'与所有子集的相似度。然后再跳回到setp1计算相似度,然后,再执行setp2,setp3,直至S为空集停止。
那么,最后提取出的子集就是提取到的候选框。
SETP4:训练SVM分类器:对每个类别(共21)个训练SVM分类器。
SETP5:回归器精修候选框位置:利用线性回归模型判断框(针对候选框的偏移值进行回归)的准确性。
SPPNet网络
sppnet针对RCNN的缺点进行了改进,更快,精度更高,主要体现再一点上:如何对卷积特征进行共享?
sppnet中提出了一种金字塔池化层,利用这个层完成卷积特征的共享。
首先,先来看看RCNN的网络处理流程:

将“Image”理解为候选区域(一个候选框框定的图像),那么,"Crop/warp"环节通过对候选区域进行抠图和resize到一个固定的尺寸,完成候选区域的提取,(这里的缺陷就是,resize可能会导致图像畸变和扭曲,在一定程度上影响最终提取出来的特征),将处理后的图像继续向后,输入到"Conv layer"中,进行特征的提取,最后通过 ''FC''层,得到输出向量(需要注意,FC层的使用就意味着"Conv layer"的输出图像的尺寸必须保持一致,但我们使用的是同一个卷积神经网,那么又继续意味着卷积神经网的输入图像尺寸,也得保持一致,这其实也就是"Crop/warp"中resize的意义了)。
通常针对于不同候选区域,会分别采用卷积来提取(分别走一遍上面的流程),如果候选区域重复了,这就造成了计算量的重复。
针对这种状况,sppnet给出了一种新的改进方法:1)对输入的图像采用不同的尺寸作为输入,这样就会得到不同大小的featuremap的输出,那么,如何得到一个同样大小的FC层的输出呢?,这就引入了spp层,就可以完成卷积特征的共享。
spp层结构如下:
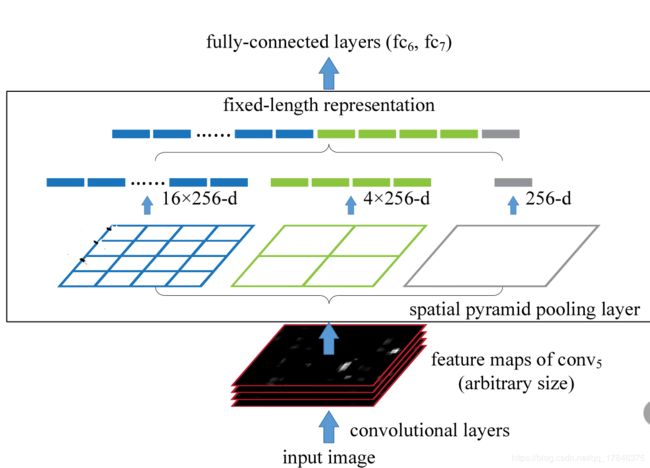
对于三种不同的尺寸,分别提取不同维度的特征,和保证不同尺寸,输入到FC层,他们的大小依然是一致的呢?我们将卷积层的结果直接输入,那么得到的FC的参数量也不一样,sppnet将每个不同的卷积层的输出,固定的通过一个spp层之后得到21维度的特征(21*c,c表通道数),从图示中可以当看到,输入FC之前的卷积的尺寸是16*256,4*256,1*256,(256表通道数)虽然这样一加(16+4+1)的确是21,但是怎么得到的呢?是这样得到的,如果我们想得到16个featumap,那么我们就需要将图像平均的划分为4*4的网格,针对每个网格内的特征点,我们只得到一个特征值,那么,同理,剩下的两个也这么搞,就将featuremap的数量可控了起来。这样就得到了固定尺度的输出。这个固定的输出再输出到后面的FC层就行了。
而上述的这个过程都是通过pooling操作来完成的,换句话说,spp层就是一个特殊的池化层。
另外,为了克服重复计算的问题, sppnet仅对原图提取依次卷积特征。 下面对着流程记录,sppnet与rcnn网络流程不一样,再候选区域一输入后就进行了一次卷积,spp层的输入并不是原图,而是卷积之后得到的featuremap,这个featuremap可能是多通道的,这也就可以解释了为啥spp层中卷积通道是256,不是一般的3,因为不是原图作为输入的,这样就可以节省更多的计算量了。
