MySQL大总结1-20(InnoDB存储引擎的关键特性、Insert Buffer、Double Write、异步IO、刷新临接页(Flush Neighbor Page))
MySQL290题链接:
https://blog.csdn.net/qq_18312025/article/details/79169903
MySQL结构图:

一、IT行业数据库布局分析
答:三类主机设备(图:)
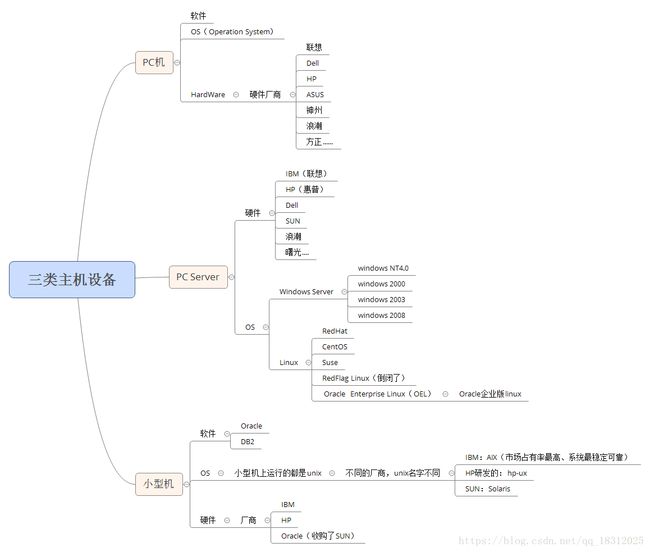
组成DB服务器系统的硬件平台:

小型机:跑unix、稳定、可靠、贵
小型机可用pc server+linux或pc server+Windows server代替
存储
①EMC:最好的,高端
②HITACHI(日立):日本的,也是高端存储
③IBM
④HP
⑤SUN
⑥DELL
常用数据库:
Oracle:(Oracle)
DB2:(IBM)
SQL SERVER 2014:(Microsoft)
Mysql:(Oracle收购SUN所得)、开源产品,互联网企业大量使用
Postgresql:开源产品、日本人使用的最熟练
Informix:(IBM收购informix所得)
Sybase:(SAP收购Sybase所得)
金融:oracle、db2、informix
运营商:oracle
互联网企业用的数据库:
mysql:很多
oracle:涉及到钱、余额的,一般用oracle;
国内的数据库厂商:
开源封装,informix
华胜天成:中国IT综合服务提供商
南大通用:国内领先的新型数据库产品和解决方案提供商
二、完整的描述sql工作过程中产生的”用户线程建立、工作区分配、内存读、物理读、commit、redo log(日志写)(用户空间)、物理写(为什么说是后台物理写)协同工作。

数据区由很多文件组成(如上图:)
数据区的特点:
- 占用空间很大;
- 主要放的是表数据,索引数据
- 数据区由很多数据文件组成
- 数据文件特点:被格式化成一个个的数据块(数据页)(data page),默认16K
- 表数据放在数据页中,以行的形式存放
执行SQL的工作过程(下图:)
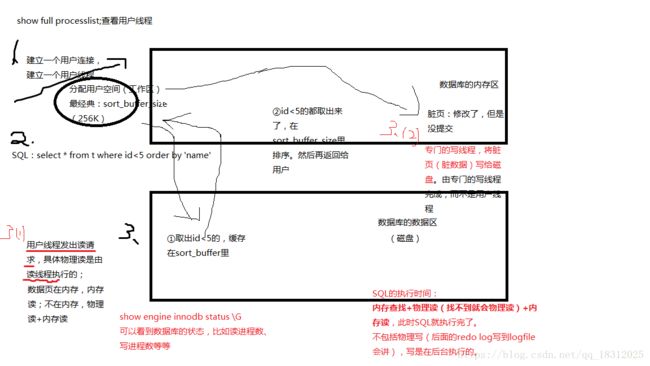
- 建立一个用户连接、建立一个用户线程,分配一个用户空间(每个用户线程都会分配一个sort_buffer)(256K指的是每个线程分配这么大);
- 执行sql,例select、insert、update、delete;
- 访问数据页,select、dml;在内存-》内存读;不在内存–》物理读+内存读。
物理读:
用户线程发出读请求,具体物理读这个动作是由专门的读线程执行的;
用户写线程负责将脏数据(已修改,但未提交的数据)写给磁盘,这个动作是由写线程来完成的,而不是用户线程来完成。
(PS:DML:数据操控语言)
DDL:数据定义语言data Definition language(create、drop、alter)
DML:数据操控语言data Manipulation language(insert、update、delete)
DCL:数据控制语言 data Control language(grant、deny、revoke)
DQL:数据查询语言 data Query language(select)
Redo log:日志本身
Log buffer:日志缓存
Log file:日志文件本身(物理存在–》文件系统–》磁盘)
进行DML操作,就会产生redo log(数据页的地址、数据行、具体动作、动作内容),redo log 就会往log buffer写,就算没提交,也会每隔一段时间不断的写,然后log buffer再写到磁盘的logfile里。
redo log会给人感觉修改了N多数据后,提交的时候,非常快!原因:其实只是把redo log写到了磁盘的logfile里,而大量的脏数据其实还没有写到磁盘里,而是在后台慢慢写,但我们并不用担心,因为redo log已经写到logfile里了!!!
(讲解图redo log_logfile:)

三、存储中的缓存和闪存工作机制
1.mysql服务器基本结构:
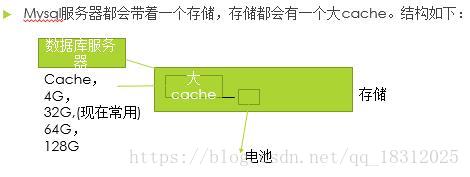
读缓存:从磁盘先读到cache,再从cache读到内存。最后给用户。
读缓存:对读操作原理上是有性能的提升,但是对于数据库系统来说,性能提升不是很明显,特别是系统稳定以后;对于写操作没有性能的提升(写的时候还是直接写到存储中…)
读缓存结构:

写缓存:对写性能有显著提升;对读性能基本上和读缓存差不多。
写缓存结构:
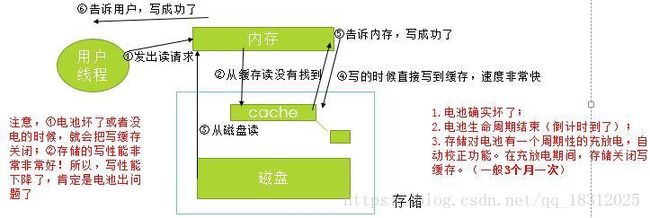
存储的写功能是很强大的,如果写缓存失效,则是因为电池导致写cache被关闭:
1.电池确实坏了;
2.电池生命周期结束(倒计时到了);
3.存储对电池有一个周期性的充放电,自动校正功能。
在充放电期间,存储关闭写缓存。(一般3个月一次)
为什么要充放电?因为cache要知道电池能给自己充多长时间的电啊~
2.闪存(现代存储)工作机制:

四、mysql存储引擎简单描述

引擎/存储引擎 mysql的特色之一
存储引擎:
1.在建立表的时候,会选择存储引擎engine
2.mysql支持多种存储引擎,每一种存储引擎有自己的独立的特色,面向不同的使用场景。
(现在大部分场景在用InnoDB引擎)
show engines;#显示所有引擎,会看到默认的是InnoDB(从mysql5.5)
InnoDB引擎的特点:
1.支持行锁(各干各的活,互补影响)、并发性能好;
2.支持MVCC(多版本并发控制Multi-Version Concurrency Control)(避免使用锁);
3.支持外键;
4.提供一致性非锁定读,并发性能更强;
5.能够使用大内存和充分利用cpu资源。
五、单台服务器上安装两套mysql实例库(可选择相同端口、不同端口)
发现这台服务器的资源占用率大约在20%左右(不忙)(正常80%左右最好)。此时,需要加入10个新服务,需要10台服务器:
【在一台mysql服务器上安装2个mysql实例库,可选择相同端口或不同端口】
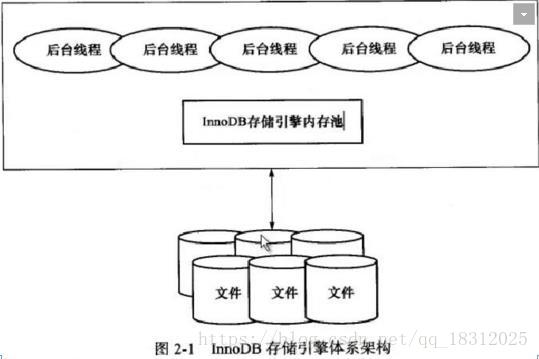
六、绘制innodb引擎的结构图,进行讲解

InnoDB存储引擎体系结构讲到了:
- 用户线程
- 后台线程
- 读线程、写线程、log线程
- innodb buffer pool(数据缓存池)
- log buffer
- logfile
七、详细描述一下commit的过程和rollback的过程,为什么commit速度总是那么快,rollback很多时候执行的很慢,可能非常慢。
根据SQL的完整执行过程来分析:
1.commit的过程很快,为啥?
commit过程很快,当用户要修改一万行表时,首先在工作区sort_buffer_size(256K)产生大量的redo log,redo log大量的写入到log_buffer_size中,但logbuffer很小(8M),存不下大量的redolog,但是logbuffer有很多的工作机制,比如①数据大于4M(1/2)时会写到logfile,②每秒会写入logfile,③commit时也会写入到logfile,但产生的大量脏块是在后台慢慢写入到磁盘的,所以commit时,会感觉速度很快。因为logbuffer中并没有太多的东西。
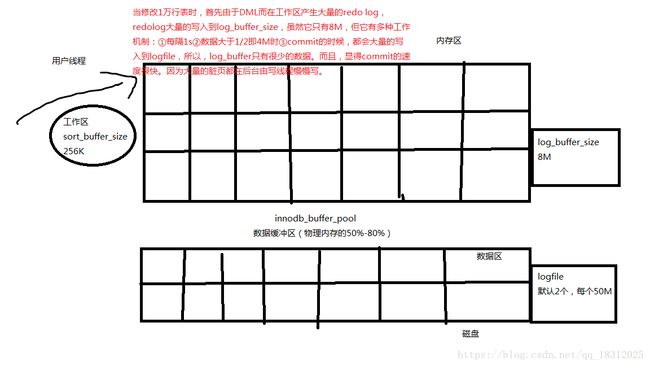
2.Rollback很多时候执行的很慢,为啥?
答:rollback时,首先要通过命令start TRANSACTION开启一个事务,在这个事务中执行的sql不会commit。所以可以rollback,在rollback时,首先要读取大量的undo,之后在执行sql,这个sql是之前sql相反的操作,之后产生大量的redo,在敲下rollback按下回车时(也就是事物结束之时)会自动回滚并且自动commit,undo页会清空,多了读取undo的过程,会导致速度比commit慢很多。

图2:

事务操作过程中:
- 物理读undo数据页
- 物理读表的数据页
- 修改undo数据页,产生redo
- 修改表的数据页,产生redo
- commit;速度非常快
- rollback;则是读取undo中的数据,根据这些数据,修改数据页,也会产生redo;然后commit
PS:undo
undo(oracle、mysql独有的东西)
①先开启一个事务:
START TRANSACTIONrollback时,首先要通过命令“start TRANSACTION”开启一个事务,在这个事务中执行的sql不会commit。所以可以rollback,在rollback时,首先要读取大量的undo,之后在执行sql,这个sql是之前sql相反的操作,之后产生大量的redo,在敲下rollback按下回车时(也就是事物结束之时)会自动回滚并且自动commit,undo页会清空,多了读取undo的过程,会导致速度比commit慢很多。
为什么需要undo?
对于一个事务来说,会有rollback和commit。
rollback本质:读取undo,反向操作,commit!
undo最基本的作用:
- rollback
- 提供一致性读,同时,写不锁定读(线程2上来要读的时候,线程1正在写,那么线程2就会去找undo)。
undo:
前滚方式:旧的数据块+redo log
回滚方式: 假设产生了8万行undo,rollback时,会读取undo log,反向操作,把8万行数据改回去,会产生大量的redo,实际就是反向操作,然后commit。所以,rollback会很慢。
后台线程(读线程、写线程、日志线程等)的作用:
- 脏页的刷新(write线程的作用)
- 合并插入缓冲(insert buffer)
- undo页的回收
- 日志写入
- 物理读
在数据库里面,有这么一个现象:如果这个线程或者进程是多个,那么这个进程或者线程就是一个主要的干活的线程,工作量很大。
master thread线程
是一个非常核心的后台线程,主要负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性,包括脏页的刷新、合并插入缓冲(insert buffer、undo页的回收等)
八、如何调整相关参数:
innodb_purge_threads=6;
innodb_read_io_threads=6;
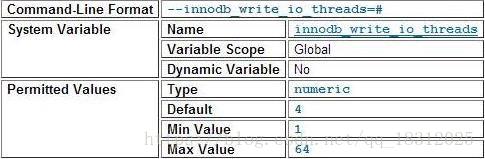
innodb_write_io_threads=6;
innodb_buffer_pool_size:物理内存的50%;
增加logfile的大小(2G),增加logfile的组数(5组)。
答:对数据库工程师来说,核心的技术是怎么监控指标和参数,确认是否需要做调整,重点不在于怎么调整!
innodb_purge_threads: 回收已经使用并分配的undo页;
innodb_read_io_threads: 读线程;
innodb_write_io_threads:写线程。
1、理论依据
- 1.这些线程都很繁忙;
- 2.这些线程对应的作用,出现了异常
2、如何改参数
- 仔细阅读官方文档
- 看参数是不是动态变量
- 动态变量:
set @@global.变量名=修改的值;让所有会话重新登录- session变量:
set @@session.变量名=修改的值;不用重新登录- 静态变量:
修改/etc/my.cnf文件即可。
3.innodb_buffer_pool_size:
什么时候增加池子的数量。
1.调整buffer大小
60-70%
2.调整instance的数量-》池子的数量。
讲到锁的时候再详解。现在默认即可。

(InnoDB 内存数据对象)
九、描述一下free list、lru list、flush list的作用,以及为什么需要这三种链。
1.为什么有这三种链:
读线程将数据页从磁盘中调入内存之中时,会首先寻找free数据块,如果有free数据块,就将新来的数据放入free数据块中,如果没有free,就会寻找冷数据块,放入冷数据块中。而存储中的logfile文件也存在着轮转覆盖,一般有两个logfile文件,logfile0写满后会写logfile1,logfile1写满后会覆盖logfile0,这时候如果logfile0中对应的脏块还没有写完,就会先将脏块写入到磁盘之中再覆盖,首先要将较早脏的数据块写入到磁盘之中,这时候就会有问题,系统怎么知道哪个是free数据块,那些是冷数据块,那些是较早脏的快。这时候就引入了free list,lru list,flush list。
2.是干什么的:
Free list(free链):需要经常找free数据块 。能够将free块串起来,当寻找free块时,就按照某种顺序来将新来的数据写入到free数据块中。
lru list(最近最少使用链):需要经常找冷的数据块 。将冷数据块连接起来,按照某种顺序将新来的数据覆盖上去 。
flush list(按照脏的早晚链起来的链):需要系统把这些logfile对应的脏页,写入到磁盘上 。原理相同,通过链把脏数据按照某种顺序(比如最早脏的在最左边)将脏数据连接起来,方便写入。
十、描述一下latch争用的过程、表现的现象、监控指标、解读指标。如何降低latch争用。
1.引入
锁,是用来管理对共享文件的并发访问
latch称为栓锁(轻量级的锁),因为其要求锁的时间非常短。
在innodb存储引擎中,又可以分为mutex(互斥量)和rwlock(读写锁)。其目的是用来保证并发线程操作临街资源的正确性,并且通常没有死锁检测的机制。
而lock锁的对象是事务,用来锁定数据库的对象,如表、页、行。并且一般lock的对象仅在事务commit或者rollback后释放(不同事务的隔离级别释放的时间可能不一样)。有死锁机制。
2.latch争用的过程
当一个线程持有latch时(也就是对这个链进行操作的时候),其他的线程得在一边看着。比如线程1持有latch,正在对freelist进行遍历,线程2也想进行遍历,是不可能的,所以现在线程2阻塞,只有两种选择,一是退出,二是等待,但如果等待就会占用cpu,如果想占用cpu就要有事可做,否则cpu’会把没事做的线程踢出去,所以线程2就会执行某段空代码来让自己忙起来(所以虽然线程2在等待,但cpu还是忙碌的)。
3.线程2的三种情况:
gets:去试试能不能获得latch锁;
misses:获取latch锁失败;
sleeps:去执行空代码让自己看起来忙了。
4.latch争用的现象:
1.latch争用会表现为cpu繁忙;
2.latch争用没有排队。
原因:
1.内存访问频繁(链在内存中);
2.list 太长了。
5.Latch争用的监控指标:
Mysql>show engine innodb status \G
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 2, signal count 2
Mutex spin waits 0, rounds 0, OS waits 0
RW-shared spins 2, rounds 60, OS waits 2
RW-excl spins 0, rounds 0, OS waits 0
Spin rounds per wait: 0.00 mutex, 30.00 RW-shared, 0.00 RW-excl
--------6.解读监控指标:
innodb在获得mutex时是两阶段的。如果Mutex被人锁住了,先做一个循环,不断去获得mutex锁,称之为spin-wait,然后才sleep。因为sleep等待被唤醒的代价还是比较高的。通过spin-wait,可以明显降低这个开销。
- mutex spin waits:这个代表的是线程获得的锁,但是被别人锁住了,所以它得首先spin-wait;
- rounds:是线程在spin-wait循环检查mutex是否已经释放的探测次数,旋转一周就是1round;
- OS waits:是spin-wait完成以后,还是没有获得mutex,不得不sleep的次数。这个主要是评估mutex获取不到的比例。比如:
- 请求mutex不到的情况是 mutex spin waits的数(比如8000),但是经过spin-wait,实际上只有OS waits的次数(比如2000),也就是说,中间的差值(75%),就是稍微等一下就能拿到mutex。
- 第二行RW-shared是:以共享的形式访问的时候的统计;
- 第三行RW-excl 是:以排他的形式访问的时候的统计。
7.如何降低latch争用
- 优化SQL,降低对内存读的数量;
- 增加innodb_buffer_pool_instances的数量。
- 对访问不是很频繁,同时相对较短的链,我们使用mutex(mutex可以理解为排他的latch。) 就可以来保护这些链。 但是,对于访问频繁的链(会有大量的读和写),还是要用latch来进行保护。
十一、如何调整内存参数innodb_old_blocks_pct和innodb_old_blocks_time,这个参数的意义是什么,用来避免什么问题?如何通过相关的指标来确认这几个参数是否需要调整。
答:
1.引入:
Innodb存储引擎对传统的LRU(Least Recently Used 最近最少使用)算法做了优化,LRU列表中加入了midpoint位置。新读取到的页,虽然是最新访问的页,但并不是直接放入到LRU列表的首部,而是放入到LRU列表的midpoint位置。
这个算法在InnoDB存储引擎下称为 midpoint inserttion strategy。在默认配置下,该位置在LRU列表长度的5/8处。
2.参数 innodb_old_blocks_pct
midpoint位置可由参数 innodb_old_blocks_pct 控制,eg:
mysql>show variables like 'innodb_old_blocks_pct'\G;
可以看到,参数innodb_old_blocks_pct 默认值是37,表示新读取的页插入到LRU列表尾端的37%的位置(差不多3/8的位置)。在innodb存储引擎中,把midpoint之后的列表称为old列表,之前的列表称为new列表。可以简单理解为new列表中的页都是最为活跃的热数据。
innodb的37%的空间是可以让人来刷的。(意思就是内存的37%拿出来让人刷,就是冷数据区的大小)
建议innodb_old_blocks_pct 调成20%
(内存的80%给DB,DB的80%给热数据(在一个时间段内被频繁的访问))
(即,一个64G的物理内存,80%给数据库,数据库的80%给热数据区,即40.96G给了热数据区。)
3.参数 innodb_old_blocks_time
这个参数用来表示 页读取到mid位置后,需要等待多久才会被加入到LRU列表的热端。
使LRU列表中的热点数据不被刷出:
mysql>set global innodb_old_blocks_time=1000;放在冷热数据交界处,默认1000ms,过了这1s,还能存活下去,就调到热数据区了。
如何修改?

所以,
mysql>set @@global.innodb_old_blocks_time=1000;
放在冷热数据交界处,默认1000ms,意思就是过了这1s,还能存活下去,就调到热数据区了。
4.看哪些指标来确定是否修改?
MariaDB [(none)]> show engine innodb status \G
Pages made young 0, not young 0
0.00 youngs/s, 0.00 non-youngs/s(1)non-youngs/s的值过大原因:
- 1.可能存在严重的全表扫描(频繁的被刷出来)
- 2.可能是pct设置的过小(冷数据区就很小,来一点数据就刷出去了)
- 3.可能是time设置的过大(没坚持到1万s,被刷出去了)
(2)youngs/s的值过大的原因:
- 1.pct过大
- 2.time过小
(pct过大,冷区大,热区小,time过小,就容易young进去。)
(正常不可能一直很高,因为热数据区就那么大)
十二、关于log buffer 调整成100M的理论依据和思路解析。
答:默认是8M,8M够用 的原因:
- 1.Master Thread线程每一秒将log_buffer写入到logfile;
- 2.每个事务提交时会将log_buffer写入到logfile;
- 3.当log_buffer剩余空间小于1/2时,将log_buffer写入到logfile
所以,8M在一般情况下是足够用的。
调整100M的原因:
- 1.我们的内存足够;
- 2.当系统IO忽然阻塞了,忽然读进程大量的上来了,就会忽然产生了大量的redo log,log_buffer就会瞬间满了,从而写进程就被阻塞了,数据库瞬间就被dang住。
所以,为了防止出现数据库忽然被dang这种情况,一般实际就设置为100M了。
十三、描述change buffer的作用,确认change buffer占用的大小,确认change buffer带来的效果,分析change buffer占用过大或者效果不明显的原因。
1.InnoDB存储引擎的关键特性包括:
- 插入缓冲(Insert Buffer)
- 两次写(Double Write)
- 自适应哈希索引(Adaptive Hash Index)
- 异步IO(Async IO)
- 刷新临接页(Flush Neighbor Page)
上述这些特性为InnoDB存储引擎带来更好地性能以及更高的可靠性。
2.引入:mysql里面的表,有个特点:
索引组织表:
这个表在存储的时候,按照主键排序进行存储。
同时在主键上建立一棵树,这样就形成了一个索引组织表。
(讲解 图.索引)
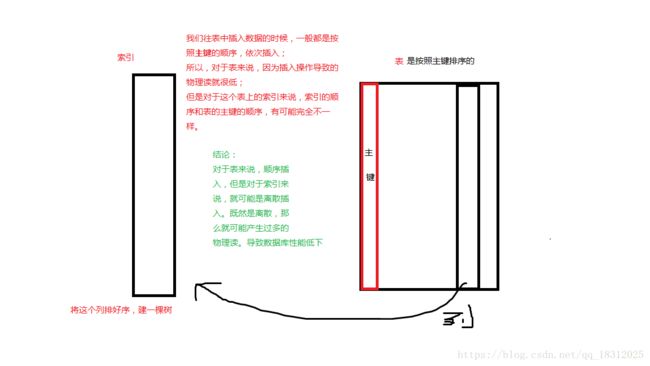
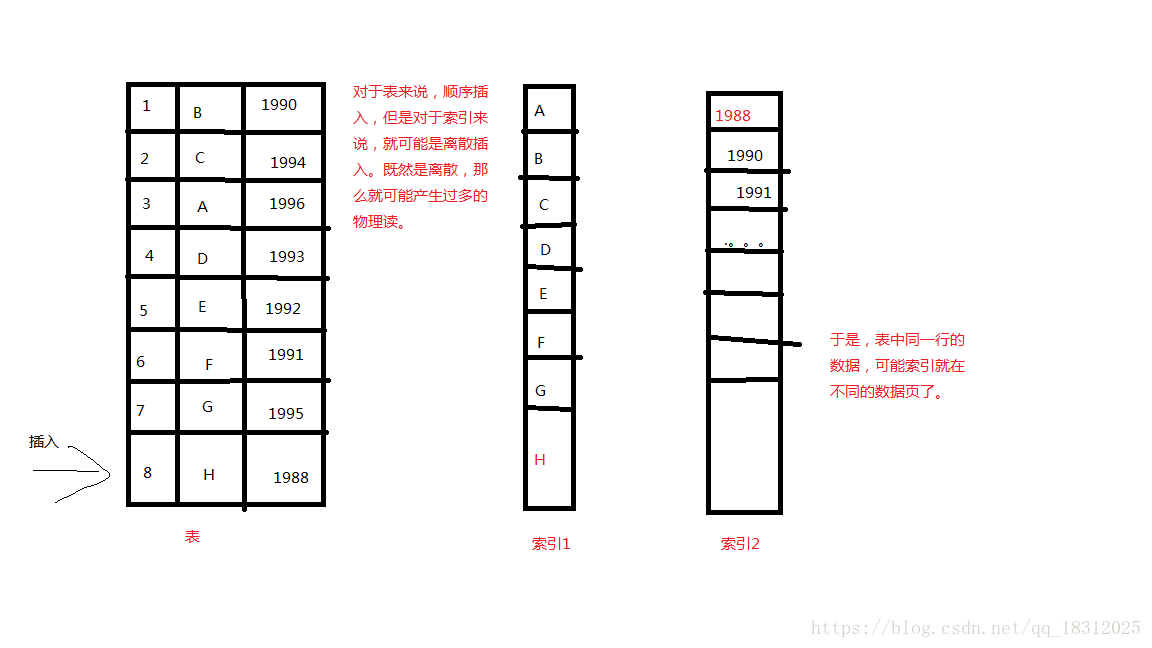
我们往表中插入数据的时候,一般都是按照主键的顺序,依次插入;
所以, 对于表来说,因为插入操作导致的物理读就很低; 但是对于这个表上的索引来说,索引的顺序和表的主键的顺序,有可能完全不一样。
结论:
对于表来说,顺序插入,但是对于索引来说,就可能是离散插入。既然是离散,那么就可能产生过多的物理读。
会出现问题:
我们在insert的时候,产生了过多的物理读,导致了性能低下。
怎么解决呢?
插入缓冲 insert buffer
【在内存中建一个插入缓冲,三个要插入的数据对应的数据链在内存中没有,就先在插入缓冲里存着。存的时候,按照地址存,发现有一些会放在同一个数据页里,攒的足够多了,这时,就把该数据页调到内存中(merge)(多次insert才对应一次merge)(减少了物理读),之后就可以删除该数据页了。 用到页的时候,才调到内存里。减少了物理读。】
(讲解 图 insert buffer的引用)
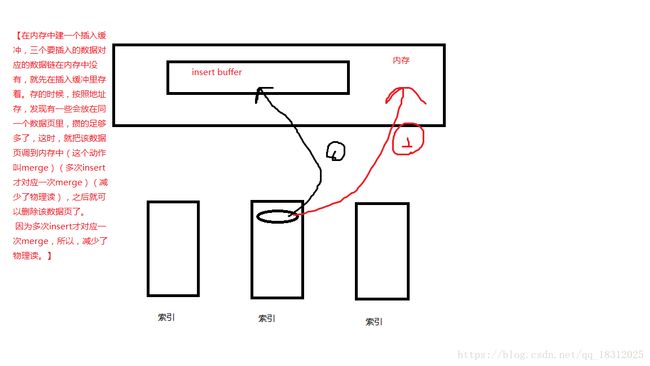
2.插入缓冲的作用:
- 表上的索引比较多;
- 很多索引的顺序和表的顺序(主键的顺序)非常不一致;
- 这个表的insert/update/delete很多,特别是insert很多;
- 如果因为DML导致的物理读很高,那就是insert buffer过小的问题。
insert或delete很多的情况下,就会出现索引的离散读的问题,
同时update索引列的时候,也会出现索引离散读的问题。
如何解决索引的离散读问题(因为DML造成的)? 答:设置足够高的change buffer(解决insert、delete、update的索引离散读问题)
(PS:一个表上的索引最好不要超过6个(经验值)!!!)
3.change buffer大小的修改:
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 0 merges
merged operations:
insert 0, delete mark 0, delete 0
discarded operations:
insert 0, delete mark 0, delete 0①change buffer 占用的内存大小:seg size:2*16K
②2个页,实际用了1个:size:1(已经合并记录页的数量);
free list len :空闲列表的长度
③insert:插入的记录数;merged recs:合并的插入记录数量;
Merges代表合并的次数,也就是实际读取页的次数。
如果change buffer过大, 而且增长迅猛:
- 1.数据库的insert、update、delete(索引列)频繁,或者出现批量操作
- 2.表的索引过多
- 3.很多索引压根没有被使用
被合并的条件:
- 1.索引数据页里面需要被合并的记录数足够多;
- 2.这个索引页被使用到,例如:这个索引页被读取到,对于这个索引页,我们顺便进行合并。
4.change buffer 实例解读:

(一次insert就是一次物理读!!!但是只有224万次,所以,因为合并,节省了物理读!!)

十四、调整change buffer占用空间的大小,以及调整依据,调整只是对insert进行合并。
答:
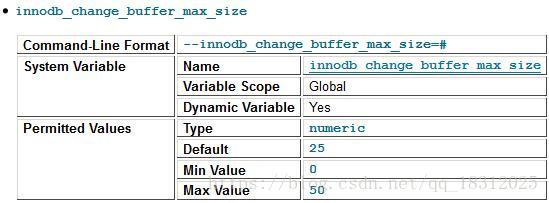
怎么修改change buffer参数
(1)show 一下看看当前是多少:
(指的是25%,意思是innodb buffer pool大小的25%)
- ①25%占满了
- ②效果不明显。
只想对insert进行合并怎么办?调整innodb_change_buffering的all改成insert!
(2)看官方手册:

附加题:怎么判断一个表上索引的数量,以及在哪些列上建立的索引。
答:
mysql里面有很多数据库,还有很多表。
ibdata:共享表空间:
1.undo数据放在里面
2.insert buffer
3.double write
insert buffer带来的问题:
- 1.磁盘上的索引在正常工作期间,索引数据和表数据是不一致的。也就是磁盘上的这些索引压根不能使用。
- 2.数据库崩溃以后(insert buffer里面的内容就没了),索引要能够使用,需要下面的一些内容进行组合:
1.磁盘上的索引数据+ibdata中的索引数据+内存中的insert buffer对应的redo log;
===补充:关于ibdata表空间:
MySQL增加了一个共享表空间和独立表空间的概念;
对于innodb的数据结构,首先要解决两个概念性的问题: 共享表空间以及独占表空间。
==什么是共享表空间和独占表空间?
共享表空间以及独占表空间都是针对数据的存储方式而言的。
共享表空间: 某一个数据库的所有的表数据,索引文件全部放在一个文件中,默认这个共享表空间的文件路径在data目录下。 默认的文件名为:ibdata1 初始化为10M。
独占表空间: 每一个表都将会生成以独立的文件方式来进行存储,每一个表都有一个.frm表描述文件,还有一个.ibd文件。 其中这个文件包括了单独一个表的数据内容以及索引内容,默认情况下它的存储位置也是在表的位置之中。
==两者之间的优缺点
共享表空间:
优点:
可以放表空间分成多个文件存放到各个磁盘上(表空间文件大小不受表大小的限制,如一个表可以分布在不同步的文件上)。数据和文件放在一起方便管理。
缺点:
所有的数据和索引存放到一个文件中以为着将有一个很常大的文件,虽然可以把一个大文件分成多个小文件,但是多个表及索引在表空间中混合存储,这样对于一个表做了大量删除操作后表空间中将会有大量的空隙,特别是对于统计分析,日值系统这类应用最不适合用共享表空间。
独立表空间: 在配置文件(my.cnf)中设置: innodb_file_per_table
优点:
1.每个表都有自已独立的表空间。
2.每个表的数据和索引都会存在自已的表空间中。
3.可以实现单表在不同的数据库中移动。
4.空间可以回收(除drop table操作处,表空不能自已回收)
a) Drop table操作自动回收表空间,如果对于统计分析或是日值表,删除大量数据后可以通过:alter table TableName engine=innodb;回缩不用的空间。
b) 对于使innodb-plugin的Innodb使用turncate table也会使空间收缩。
c) 对于使用独立表空间的表,不管怎么删除,表空间的碎片不会太严重的影响性能,而且还有机会处理。
缺点:
单表增加过大,如超过100个G。
相比较之下,使用独占表空间的效率以及性能会更高一点。
==共享表空间和独立表空间之间的转换
mysql> show variables like "innodb_file_per_table";
ON代表独立表空间管理,OFF代表共享表空间管理;(查看单表的表空间管理方式,需要查看每个表是否有单独的数据文件)
如何修改?
修改innodb_file_per_table的参数值即可,但是修改不能影响之前已经使用过的共享表空间和独立表空间;
innodb_file_per_table=1:为使用独占表空间
innodb_file_per_table=0:为使用共享表空间=====判断一个表上索引的数量,以及在哪些列上建立的索引:
索引:
在数据库中,从表中取数据的方式:
- 1.全表扫描(从表的第一行开始,一直找到最后一行)
2.通过索引
(优化SQL的时候:走全表扫描如果性能差,就建立索引。一般,取少量数据的时候,适合按索引;取大量数据,适合全表扫描。)
eg:要找:select * from t where name=’james’;
如果走全表扫描的话,相当于对100万行数据全部扫描,对于每一行数据都使用where条件进行过滤。(99.9999%数据被过滤掉)
十五、描述一下索引的工作过程,适合使用的场合,结合insert buffer描述一下,索引如何结合insert buffer进行工作。如何建立索引,如何确认索引是否生效?
答:
索引是以表列为基础的数据库对象,索引中保存着表中排序的索引列,并且纪录了索引列在数据库表中的物理存储位置,实现了表中数据的逻辑排序。
通过索引,可以加快数据的查询速度和减少系统的响应时间;
可以使表和表之间的连接速度加快。
1.索引的工作过程:
用户抛出某个请求需要用到索引,就将索引从存储中读出来,然后将索引对应的数据页从磁盘中读出来,并将其中的符合需求的数据呈现给用户.
2.索引工作的场合:
对一个100万行表进行
select * from t where name=‘james’;
如果做全表扫描的话,相当于100万行数据全部扫描,对于每一行数据都使用where条件进行过滤,大多数数据都被过滤掉,这时候就会显得全表扫描效果很差,就需要通过索引来进sql 。
3.索引和insert buffer结合:
在内存中插入一个数据行内存会读取对应的数据块,并存放在内存里,而这些数据页对应的索引页也将被读取到内存中,但是读取索引页会造成大量物理读(一个数据块可能有很多索引页),所以就将索引页和数据行对应的索引行放入到 insert buffer中(而存放索引行的顺序是按将来索引行所在索引页的地址存)
4.如何进行数据访问如何建立索引:
一般的索引通过树高来进行数据访问,create insex + 索引的名字 + on +表的名字 + (指定表的列)
5.如何建立索引,如何确认索引是否生效?
(1)建立:
CREATE [UNIQUE] [CLUSER] INDEX <索引名> ON <表名>(<列名>);
UNIQUE:表明此索引的每一个索引值只对应唯一的数据记录
CLUSTER:表明要建立的是聚簇索引(指索引项的顺序与表中记录的物理顺序一致)
例:
CREATE CLUSER INDEX Stuname ON Student(Sname);
#在student表的sname列建立一个聚簇索引,student中记录按照sname值的升序排列.(2)看是否生效:
explain select * from t2 where name='x';
key不等于NULL,就是索引已经生效了。
十六、描述一下double write解决的场景,工作过程,如何打开和关闭这个功能跟,通过这个功能对应的指标(status),来确认系统写操作是否有压力,并作出解释。
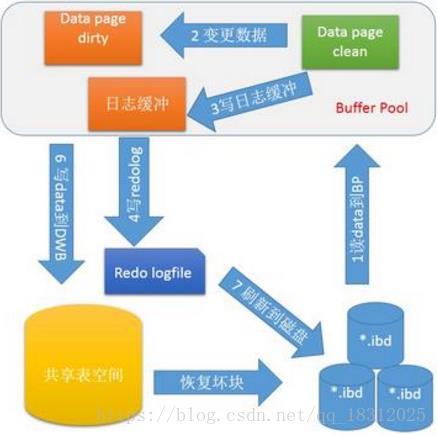
double write(两次写)
介绍double write之前我们有必要了解partial page write 问题 :
InnoDB 的Page Size(页面大小)一般是16KB,其数据校验也是针对这16KB来计算的,将数据写入到磁盘是以Page为单位进行操作的。而计算机硬件和操作系统,在极端情况下(比如断电)往往并不能保证这一操作的原子性,16K的数据,写入4K 时,发生了系统断电/os crash ,只有一部分写是成功的,这种情况下就是 partial(局部) page write 问题。
很多DBA 会想到系统恢复后,MySQL 可以根据redolog 进行恢复,而mysql在恢复的过程中是检查page的checksum,checksum就是page的最后事务号,发生partial page write 问题时,page已经损坏 ,找不到该page中的事务号,就无法恢复。
Double write 是InnoDB在 tablespace上的128个页(2个区)是2MB;
其原理:
为了解决 partial page write 问题 ,当mysql将脏数据flush到data file的时候, 先使用memcopy 将脏数据复制到内存中的double write buffer ,之后通过double write buffer再分2次,每次写入1MB到共享表空间,然后马上调用fsync函数,同步到磁盘上,避免缓冲带来的问题,在这个过程中,doublewrite是顺序写,开销并不大,在完成doublewrite写入后,在将double write buffer写入各表空间文件,这时是离散写入。
如果发生了极端情况(断电),InnoDB再次启动后,发现了一个Page数据已经损坏,那么此时就可以从doublewrite buffer中进行数据恢复了。
1.场景:
内存想向存储里写入一个脏页,假如这时候数据库系统崩溃了,这个脏数据页就会被损坏,如果有double write就可以防止这样事情的发生。
2.工作过程:
【 内存将原先写入磁盘的脏页先写到内存里的double write中,然后从内存里double write中将脏页写入到ibdata里的double write中和数据文件中。】
十七、通过索引来访问表,主要的资源消耗分析,尤其在什么情况下,资源消耗得特别厉害?(要详细解释!)
答:
1.如何判断数据库系统的繁忙度?
mysql> show global status like '%dbl%'; #判断数据库系统繁忙度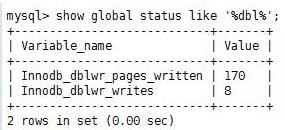
(共写了170个页,写了8次。)
(现在的比值是21:1,意思就是每次写,写21个页。)
注意比值:当written/writes比值为128:1时,就是写操作比较繁忙,压力比较大。 小于128时,就是不繁忙。
为什么是128:1就是繁忙的?(图解:)
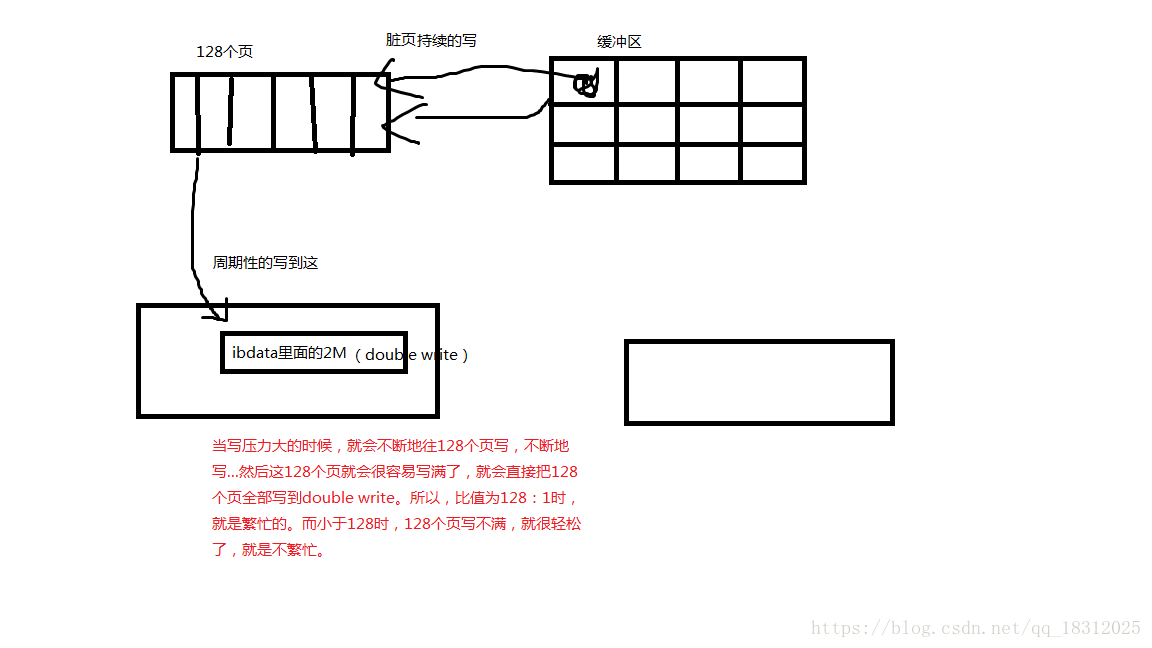
(图:Double Write架构:)

doublewrite 由两部分组成 :一部分是内存中的dou blewrite buffer ,大小为2MB;另一部分是物理磁盘上共享表空间中连续的 128个页 ,即两个区 (extent) ,大小同样为 2MB。
当缓冲地的脏页刷新时 ,并不直接写磁盘 ,而是会通过memcpy 函数将脏页先拷贝到内存中的doublewrite buffer ,之后通过doublewrite buffer再分两次 ,每次写入 1 MB到共享表空间的物理磁盘上,然后马上调用fsync 函数,同步磁盘,避免缓冲写带来的问题。在这个过程中 ,因为doublewrite页是连续的 ,因此这个过程是顺序写的,开销井不是很大 。在完成 doublewrite页的写入后 ,再将doublewrite buffer 中的页写入各个表空间文件中 ,此时的写入则是离散的。
==关于索引的资源消耗(图解:)

主要的资源消耗在:
- 索引的树高;
- 要访问的索引的数据;
- (主要消耗在)从索引往表上跳的时候,而跳的时候,又主要是取决于:表的主键列的有序度和索引列的有序度。
索引的物理布局的三大特点:
- 索引小(找起来就快了)
- 索引有序(快速定位终点)
- 索引上面有棵树(能快速定位起点)
十八、自适应哈希索引AHI(Adaptive Hash Index)要降低的是哪个资源消耗,描述其工作工程,理解hash运算,通过读取相关指标来确认这个功能的效果。学会打开和关闭这个功能。
答:(可以理解为就是为了处理上面的问题:通过索引访问表的时候的主要资源消耗问题)
(其实自适应hash索引解决的是:树高的问题)
1.工作过程:
假如你频繁的访问一个索引,就要频繁的访问索引对应的树高,假如这个索引是x,这时候针对x会做一个函数运算,得到一个地址,将这个地址存放到一个新建的索引中去。经过时间的推移,xyz。。都会被这样做,这个新建的索引列里的地址就会越来越多,以后再来找x的时候就可以通过函数得到和新建的索引区对应的数据块寻找。(就是不走树高了,直接去找新建的索引,就省去了时间咯)
2.自适应:只要打开功能,就自己去适应;
3.解决的是访问数的问题。
==自适应哈希索引的指标:
MariaDB [(none)]> show engine innodb status \G
Hash table size 276671, node heap has 0 buffer(s)
0.00 hash searches/s, 0.00 non-hash searches/s指标解读:
- Hash table size:以字节为单位。
- hash searches/s:使用的数。
- non-hash searches/s:没有使用hash的数。
- 对频繁访问的列的值进行hash运算,得到值,存到哈希索引里。用的时候,没找到,则non-hash searches/s 加1, 找到了hash searches/s加1。
所以,当hash searches/s 占 Hash table size比例比较大时,就是自适应哈希索引AHI起作用了。
===打开或关闭AHI自适应哈希索引的功能
(自适应哈希索引可以关闭,起的作用并不是很大。)
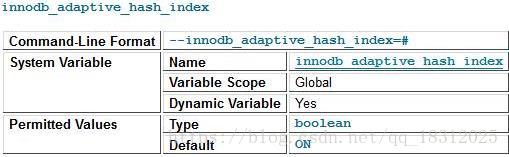
变量名:innodb_adaptive_hash_index
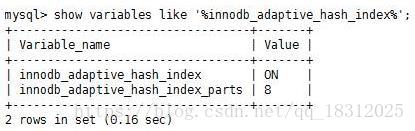
官方文档:
十九、描述异步IO的好处;描述如何确认打开异步IO(操作系统层面确认异步io开启,linux默认开启;数据库层面也是开始)
答:启用Naive AIO,恢复速度可以提高75%!!
(一定要打开此功能!)
(在linux中,默认是打开的:)
mysql>show variables like '%aio%';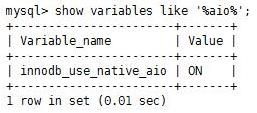
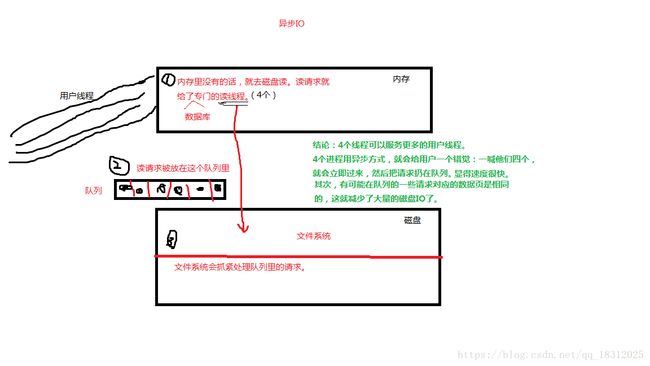
1.异步IO工作原理:
在数据库系统中,不管是用户线程还是读线程,他们发出请求后是,不会等待请求回应的,直接就去干别的去了,而它们的请求被放到队列里,后台的文件系统会抓紧处理队列里请求,所以用户会觉得读线程处理请求熟读特别快(用户线程抛出的请求,读线程立马抛入到队列里,接着响应接下来的请求);有可能在队列的一些请求对应的数据页是相同的,这时候就会大量减少磁盘io。(图解:)
异步IO:
操作系统层面默认是开启的。
Linux默认是开启的。 ldconfig -p | grep libaio(ldconfig看加载了哪些库)
数据库层面默认也是开启的。innodb_use_naive_aio
二十、描述innodb_flush_neighbors 临接页的具体功能、弊端、好处。如何开启和关闭。

刷新邻接页(Flush Neighbor Page)
参数:innodb_flush_neighbors
此功能建议关闭。(这功能可以打开,影响不大。)
1.工作原理
假如将innodb_flush_neighboors功能打开,在写冷脏页的时候如果发现冷脏页周围的页在物理地址上挨着,就会将周围的脏页也顺手写入磁盘,(磁盘不害怕一次写多个而害怕写多次)。坏处,还是增加了物理io(虽然不多)而且如果这个顺便被写入的脏页是个热脏页(总是被修改),那么在内存里一会又被写入了 。
2.如何打开和关闭
官方文档:

默认值为 1
在SSD存储(固态硬盘)(有着超高IOPS性能)上应设置为0(禁用) ,因为使用顺序IO没有任何性能收益。
在使用RAID的某些硬件上也应该禁用此设置,因为逻辑上连续的块在物理磁盘上并不能保证也是连续的。
【IOPS:Input/Output Operations Per Second,即每秒进行读写(I/O)操作的次数,多用于数据库等场合,衡量随机访问的性能。】
【PS:在大量写的时候,一般设置为0;在主库上,一般设置为1;在从库上,一般设为2;】
Create By LPeng