tensorflow-综合学习系列实例之神经网络minst
在深度学习过程中有一个非常经典的例子,就是识别手写字体,本文就通过tf完成这个例子,让大家对tf有个更加直观的认识.
在讲实例之前,先和大家说一下one_hot,因为在解析来的代码中会用到,看下面的例子
# 使用One-Hot Encoding 有效的编码技术 举个列子 # 例如,考虑一下的三个特征: # ["male", "female"] # ["from Europe", "from US", "from Asia"] # ["uses Firefox", "uses Chrome", "uses Safari", "uses Internet Explorer"] # 如果将上述特征用数字表示,效率会高很多。例如: # ["male", "from US", "uses Internet Explorer"] 表示为[0, 1, 3] # ["female", "from Asia", "uses Chrome"]表示为[1, 2, 1],在任意时刻,其中只有一位有效
记住起始位置是从0开始,但这个技术是要分场景的,比如在后面词向量也可以使用这个技术,但是它的准确度就需要考虑了,因为
它本身就忽略了词与词之间的关系,只是单纯的表示词,这个肯定是欠准确度,后面在讲词向量这块会阐述的。
要完成这个功能,需要哪些核心步骤呢
1 下载数据集
2 处理数据集
3 定义参数
4 初始化各种类型的变量
5 计算损失函数
6 更新损失函数的梯度
7 分批训练
8 执行运行
9 计算accury
具体看代码实现和解释
# author jiahp # 通过神经网络来训练手写字体 import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data #使用mlp网络来识别手写数字 # 下载手写数据集 mnist = input_data.read_data_sets('MNIST_data', one_hot=True) # 定义参数 tf.flags.DEFINE_integer('hidden_div_size',256,'hidden div layer size') tf.flags.DEFINE_integer('input_div_data',784,'input div layer size') tf.flags.DEFINE_integer('out_input_class',10,'soft multi class') tf.flags.DEFINE_integer('train_epochs',100,'summary iterator epoch') tf.flags.DEFINE_integer('train_batch_size',100,'every time train size') tf.flags.DEFINE_integer('train_display_step',5,'every time step show display loss base') tf.flags.DEFINE_float('lr',0.01,'learning rate') FLAGS = tf.flags.FLAGS #创建输入变量 hidden_div_size =FLAGS.hidden_div_size # 隐藏层数量为256 input_div_data = FLAGS.input_div_data # 输出层数量为784 out_input_class = FLAGS.out_input_class# 输出结果分类为10 ,0-9 learning_rate = FLAGS.lr # 学习速率 #创建训练变量 train_epochs = FLAGS.train_epochs # 训练迭代次数为100 train_batch_size = FLAGS.train_batch_size # 每次迭代训练数据的数量为100 train_display_step = FLAGS.train_display_step # 每训练5次 就显示一下训练信息 # 创建图的上下文管理器 with tf.Graph().as_default(): sess = tf.Session()
#创建会话的上下文 with sess.as_default(): #创建输入和输出数据 x = tf.placeholder(tf.float32,[None,input_div_data]) #创建隐藏层的权重和biases y = tf.placeholder(tf.float32,[None,out_input_class]) hidden_weight = tf.Variable(tf.random_normal([input_div_data,hidden_div_size], stddev=0.1)) hidden_biases = tf.Variable(tf.zeros([hidden_div_size])) #创建输出层的权重和biases out_weight = tf.Variable(tf.zeros([hidden_div_size, out_input_class])) out_biases = tf.Variable(tf.zeros([out_input_class])) #定义一个层 def add_layer(x_input): hidden_layer_data = tf.nn.relu(tf.add(tf.matmul(x_input,hidden_weight),hidden_biases)) return (tf.matmul(hidden_layer_data,out_weight) + out_biases) #前向传播的预测值 pred_div_data = add_layer(x) #计算损失函数 loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred_div_data,labels=y)) #创建优化器 optimizer = tf.train.GradientDescentOptimizer(learning_rate) #计算梯度下降 train = optimizer.minimize(loss) #计算最大值 1 代表按行 0 代表按列 corr = tf.equal(tf.argmax(pred_div_data,1),tf.argmax(y,1)) #计算准确度 accuracy = tf.reduce_mean(tf.cast(corr,tf.float32)) #创建变量 init = tf.global_variables_initializer() #运行 sess.run(init) #网络训练 for epoch in range(train_epochs): avg_cost = 0 train_total_batch = int(mnist.train.num_examples/train_batch_size) for i in range(train_total_batch): batch_xs, batch_ys = mnist.train.next_batch(train_batch_size) # 逐个batch的去取数据 #批量训练模型 sess.run(train,feed_dict={x:batch_xs,y:batch_ys}) #批量计算损失函数 avg_cost+= sess.run(loss,feed_dict={x:batch_xs,y:batch_ys})/train_total_batch # 打印loss信息 if epoch % train_display_step == 0: #计算训练准确度 train_acc = sess.run(accuracy, feed_dict={x: batch_xs, y: batch_ys}) #计算测试准确度 test_acc = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels}) print("Epoch: %03d/%03d cost: %.9f TRAIN ACCURACY: %.3f TEST ACCURACY: %.3f" % (epoch, train_epochs, avg_cost, train_acc, test_acc)) print('training data done')
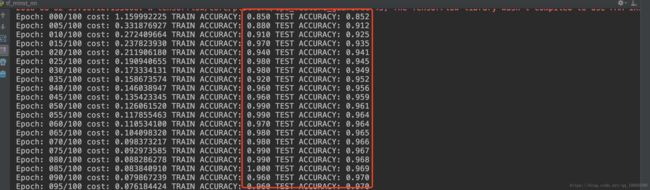
至此代码就写完了,在训练过程中大家适当提升训练的epoch会发现精度是有所提升的,但是到后面会发现变化越来越小,甚至会下降,
这个就是神经网络的不足,在后面我们会用cnn进行优化,会发现精度会变得更高,实际环境中在做和图片相关的识别我们都是会使用cnn作为基本网络,当然更加复杂的情况会使用cnn的各种变种和组合,这个在后面会涉及到的,好了 最后截图是训练的部分显示信息