和我一起学Hadoop(五):MapReduce的单词统计,wordcount
使用MapReduce开发一个单词统计的Demo,算是一个入门级别的demo
代码托管github
假设我们的数据样本
apple banner iphone
test class private
poublic string int
char byte changeMaper与Reducer
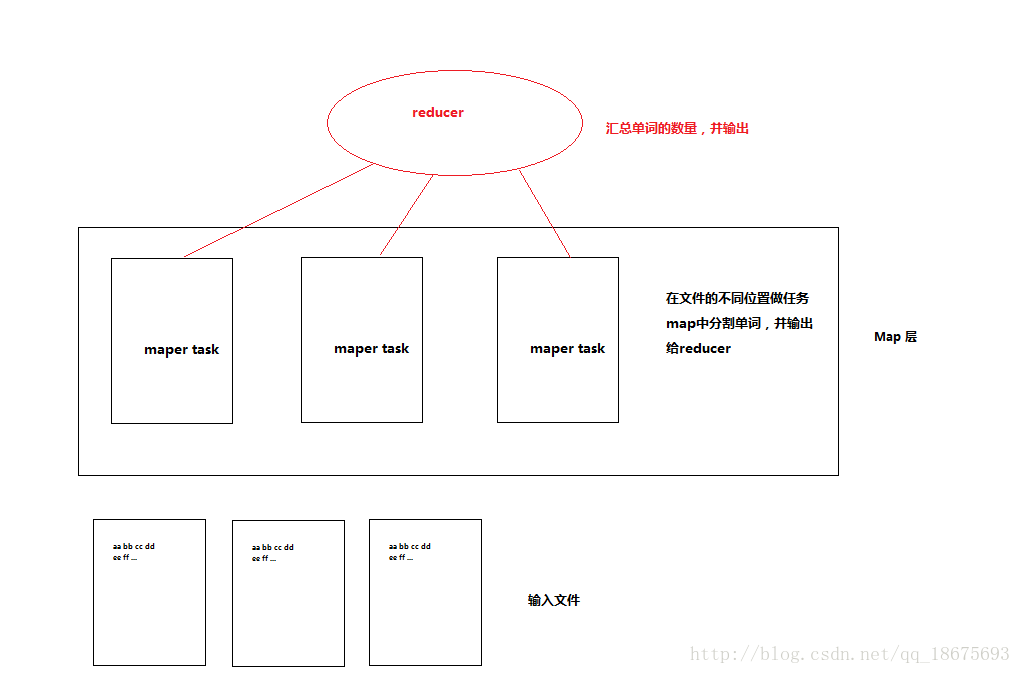
假设我们这里的样本数据是非常大的T级别,Mapper做了什么事儿?
这么大的文件在HDFS上是分块存储的,Mapper会把整个大文件分片,搞成N个Mapper Tasks分别计算,最终将他们输出到
Reduce Tasks。默认情况下Reduce Task只有一个。Maper的输出作为Reducer的输入。Reducer在不指定Partitioner的情况下,将文件输出到指定的目录下。
如:
[root@hadoop01 myjobs]# hadoop fs -ls /test/wordcount/out
Found 2 items
-rw-r--r-- 3 root supergroup 0 2017-01-16 21:46 /test/wordcount/out/_SUCCESS
-rw-r--r-- 3 root supergroup 111 2017-01-16 21:46 /test/wordcount/out/part-r-00000_SUCCESS:是执行成功的标识
part-r-0000:存放输出的结果
代码实现
Mapper类,继承org.apache.hadoop.mapreduce.Mapper
输入参数KEY:该文本在在整个文件中的偏移量
输入参数VALUE:一行文本
输出参数KEY:单词
输出参数VALUE:1
每见到一个单词就输出一个 : [key:单词,value:1]
/**
* 统计单词数量的Map Task
* KEYIN:mapreduce每读入一行数据的起始偏移量
* VALUEIN:mapreduce读入的一行数据
* KEYOUT:用户自定义输出Key
* VALUEOUT:用户自定义输出Value
* 以上参数均需要实现 org.apache.hadoop.io.Writable
* @author 许宝众
*/
public class WordCountMaper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value,Context context)throws IOException, InterruptedException {
//读入一行数据
String oneLine=value.toString().replaceAll("\\s+", " ");
String[] words=oneLine.split(" ");
for (String word : words) {
context.write(new Text(word), new IntWritable(1));
}
}
}Reducer类:继承org.apache.hadoop.mapreduce.Reducer
输入参数KEY:单词
输入参数VALUE:计数1
输出参数KEY:单词
输出参数VALUE:总出现次数
最终输出: [key:单词,value:总次数]
/**
* 统计单词数量的Reduce Task
* KEYIN:Map Task的输出参数Key
* VALUEIN:Map Task的输出参数Value
* KEYOUT:Reducer自定义输出Key
* VALUEOUT:Reducer自定义输出Value
* 以上参数均需要实现 org.apache.hadoop.io.Writable
* @author 许宝众
*/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text word, Iterable valuesIterator,Context context)throws IOException, InterruptedException {
int count=0;
//统计单词数量
Iterator iterator = valuesIterator.iterator();
while(iterator.hasNext()){
iterator.next();
count++;
}
// for (IntWritable valueInterator : valuesIterator) {
// count++;
// }
context.write(word, new IntWritable(count));
}
} Job类:定义如何在hadoop集群工作
/**
* 在hadoop上跑mapreduce的准备工作
*
*/
public class WordCountJob {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// 创建一个Job实例
Job job=Job.getInstance(conf,"wordcount");
/*
* 设置所在jar
* 因为我们会将其打包为jar,所以指定自己的Class类
*/
job.setJarByClass(WordCountJob.class);
// 设置Maper类
job.setMapperClass(WordCountMaper.class);
// 设置Maper输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 设置Reducer类
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 设置输入格式|输出格式
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
/*
* 指定输入路径|输出路径
* API似乎有变化
* 原始为:
* job.setInputPath(new Path(args[0])));
* job.setOutputPath(new Path(args[1]));
* 当前版本
*/
TextInputFormat.setInputPaths(job, new Path(args[0]));
TextOutputFormat.setOutputPath(job, new Path(args[1]));
// 提交任务,等待任务处理完成退出
// 执行成功返回0,失败返回1。可用于检查运行状态
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}部署
打包工程
放入hadoop集群
运行如下指令:
hadoop jar [jar包路径] [主类的全类名] [输入文件路径] [输出文件路径]
hadoop不允许指定的输出路径已存在,防止文件覆盖
eg.
hadoop jar wordcount.jar com.xbz.bigdata.mapreduce.demo.wordcount.WordCountJob /test/wordcount/in /test/wordcount/out