大数据入门之开发环境搭建之hadoop篇
这篇教程我将会教大家如何一步步从零开始搭建好我们的大数据完全分布式实验平台
实验环境:1.由于实验环境是在linux系统中,所以我们需要用虚拟机摸拟linux操作系统,操作系统的版本我们选 centOS 7,需要建立的虚拟机的台数根据自己的电脑的配置来决定,一般为了较好的完成实验,我们需要3台或3台以上,一台master主机,其于为slave从机,虚拟机可以使用vmware或者oracl VirtualBox,这里不再讲解虚拟机的搭建
2.软件:本课程第一节将讲基础环境hadoop的搭建,只有把hadoop搭好了并且把hdfs(hadoop distributed file systemhadoop分布式文件存储系统)配置好,才可以使我们hadoop生态圈的其他的组件得以运行,比如我们的大数据环境下的数据库有hbase、mongodb等,包括hbase所依赖的zookeeper环境,以及不同于mapreduce计算框架的spark和storm计算框架的搭建都会在后续中讲解
java环境:jdk-8u151-linux-x64.tar.gz,
hadoop-2.7.4.tar.gz(hdfs,mapreduce计算框架,yarn架构等都是在hadoop进行配置)
软件我们使用官方版本而不是cdh5版本,下面给出cdh5版本地址:http://archive.cloudera.com/cdh5/cdh/5/
三台虚拟机配置,网卡配置使用NAT方式,这样主机会给虚拟机自动分配IP,打开虚拟机时,进入设置,点开“网络”,把有线连接打开就行了
master 192.168.1.103
slave1 192.168.1.105
slave2 192.168.1.106
slave3 192.168.1.107
用SecureCRT远程连接虚拟机,方便上传文件。

先修改四台主机的主机名并配置主机名和ip地址的映射,依次修改为master,slave1,slave2,slave3因为我们的hadoop集群是根据是主机名通信的

修改etc/hosts下的hosts的文件添加映射,centos下可以用gedit直接大开编辑

在每台机器的home目录下建一个softwares用于保存软件,tar用于保存安装包

在SecureCRT使用文件上传命令把tar包上传的虚拟机
先进入master机器的tar目录下
![]()
然后运行rz命令,选择文件上传(双击要选择的tar包)
上传完成之后,在虚拟机里就可以看到我们的tar包了

或者我们可以直接进入/home/tar目录用ls命令查看

配置主机与从机的ssh免密码连接,在主机根目录上(cd ~可以进入根目录)运行命令 ssh-keygen -t rsa

然后连续输入回车

生成的秘钥位于 ~/.ssh文件夹下。可进入查看

在master上,导入authorized_keys,进入~/.ssh目录,运行 cat id_rsa.pub >> authorized_keys命令
![]()
远程无密码登录(把master上的authorized_keys拷贝到其他主机的相应目录下)注意,你的从机上可能没有.ssh目录,所以在三个从机上cd ~,然后mkdir .ssh建立.ssh目录
![]()
把master上的authorized_keys拷贝到其他主机的相应目录下
scp authorized_keys root@slave1:~/.ssh/
主意以下几点:root为你的slave1机器 linux系统的用户名,slave1是从机1的主机名,同理其他两台从机也是类似的方似
第一次连接需要输入密码,但是在linux下密码不会显示出来,所以别以为你没敲上

所有机器的~/.ssh目录下,均执行命令:chmod 600 authorized_keys

验证ssh连接,在master上 输入ssh slave1,测试已连上slave1

解压软件
在master上,进入/home/tar 运行 tar -zxf jdk-8u151-linux-x64.tar.gz -C /home/softwares解压jdk
使用命令把master上的jdk发到其他三台机器,以slave1为例
scp -r /home/softwares/jdk1.8.0_151 root@slave1:/home/softawres
然后配置环境变量,可直接在虚拟机里用gedit打开/etc/profile添加如下 三个机器上都配置
#java
export JAVA_HOME=/home/softwares/jdk1.8.0_151
exprot PATH=$JAVA_HOME/bin:$PATH
在master上,进行/home/tar 运行 tar -zxf hadoop-2.7.4.tar.gz -C /home/softwares解压hadoop
然后配置环境变量,可直接在虚拟机里用gedit打开/etc/profile添加如下 master机器上配置
#hadoop
export HADOOP_HOME=/home/softwares/hadoop-2.7.4
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$HADOOP_HOME/bin
然后用source命令刷新一下/etc/profile文件使配置生效
![]()
修改hadoop的一些重要配置文件
修改/home/softwares/hadoop-2.7.4/etc/hadoop下的七个配置文件

3)配置文件:hadoop-env.sh
修改JAVA_HOME值(export JAVA_HOME=/home/softwares/jdk1.8.0_151)修改JAVA_HOME值(export JAVA_HOME=/home/softwares/jdk1.8.0_151)
3)配置文件:slaves 这就是配置从节点
slave1
slave2
slave3
core-site.xml
其中第三个属性需要我们创建一个文件夹,如果不创建它默认是在/tmp/hadoop-${user.name}
我们手动在/home/softwares/hadoop-2.7.4建一个tempdir
hdfs-site.xml
其中第二三个属性需要我们创建一个文件夹,如果不创建它默认是在/tmp/hadoop-${user.name}
我们手动在/home/softwares/hadoop-2.7.4建一个namenode和一个datanode
mapred-site.xml
先创建然后编辑
把mapred-site.xml.template复制一份改为mapred-site.xml
yarn-site.xml
到此配置完成,把master上的hadoop发送slave上,以slave1为例
scp -r /home/softwares/hadoop-2.7.4 root@slave1:/home/softwares
在master
source /etc/profile
进入/home/softwares.hadoop-2.7.4
执行
bin/hdfs namenode -format
sbin/start-all.sh
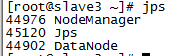
启动后分别在master, slave下输入jps查看进程,如下则启动正确
master

slave1

slave2

slave3