JVM执行分析
jvm详解概述
对于java程序而言,现在应用的范围越来越广泛,那么对于从业者就不再只是单单能够实现项目需求就够了,除了这些之外,还需要对程序的调优具有一定的能力。
类加载器(ClassLoader),用户可以实现自定义的类加载器的处理操作,那么对于类加载器本身就属于JVM的重要组成范畴。
java程序的执行流程:

每当使用了类加载器进行类加载之后实际上都表示启动了一个JVM的进程,那么在这一个进程之中实际上就有该进程自己的运行处理方式。当一个程序执行之后会将此程序所需要的内容加载到运行时数据区之中,那么所谓的内存的分配实际上就在此组成部分之中。
在java程序定义之中会包含有一个native的关键字,这个关键字定义好的方法实际上和抽象方法的形式类似,都是没有方法体的,也就是说这些方法体最终都是需要通过JVM调用本地的操作系统函数来实现。
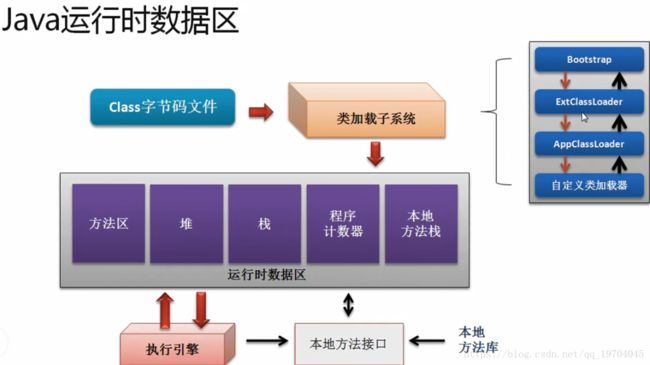
运行时数据区:
在实际的开发之中,手工编写类加载器的情况并不多,因为大部分的操作都是通过ClassPath进行类加载的,而且所有的类基本上都会放在*.jar文件里面。
在运行时数据区之中,内存的分配主要分为五块:
1)堆内存(Heap):保存真正的程序的数据部分;
2)栈(Stack):保存堆内存的地址,数据(本身存放地址数据、基本数据)、方法的执行
3)方法区:保存所有的方法的具体操作,该区域属于共享,线程共享
4)本地方法栈:该栈之中所保存的都是操作系统的原生函数。
5)程序计数器:这是一块很小的内存,小到可以忽略不计,只是做一个程序执行顺序的记录,(比如java程序报错,会指定哪一行报错,但是代码本身没有行数),只是为了标记下一步要执行代码的顺序号。
在开发中,程序计数器和本地方法栈都无需关心,其它的都是可以关系的
在整个JVM内存组成过程之中,栈内存是一个非常重要的概念,因为在该内存之中,它需要保存的数据是一组内容

堆和方法区是所有线程对象共享的,而其java虚拟栈和本地方法栈以及程序计数器是每个线程对象独享的
java虚拟机栈(JVM Stacks)
栈内存是线程私有的,其生命周期和线程相同

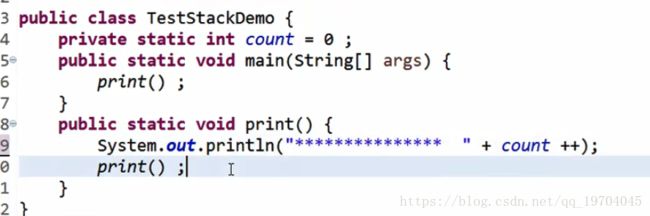
范例:观察递归调用的情况
执行后:
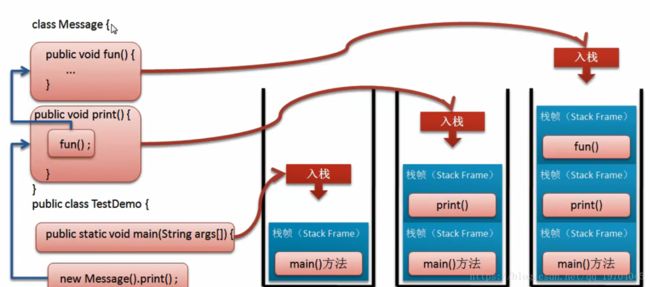
因为所有方法在进行递归调用的时候都会采用栈的模式,
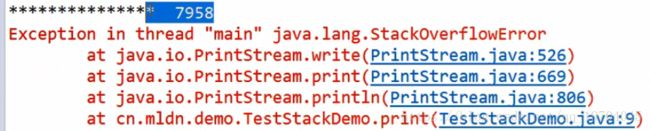
main方法入栈,之后继续调用print()方法,由于循环,入栈的print()越来愈多,之后满栈(栈的大小不是无限大的,取决于计算机的内存情况)
导致栈溢出StackOverflowError异常
范例:
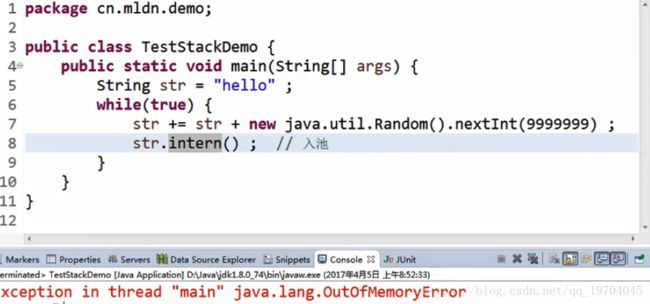
如果虚拟机的实现允许、虚拟机栈动态扩展,当内存不足以扩展栈的时候,会抛出OutOfMemoryError异常
以上为栈溢出和内存溢出
实际上上面只是观察到了两类可能出现的错误代码,但是并不意味着栈中只能够保存一些基本的信息,实际上栈里面保存的同样是一组的数据。这组数据包含了栈帧(栈帧中又包含了局部变量表、操作数栈,指向运行时常量池的引用,方法返回地址、动态链接)

java虚拟机栈中存放的是多个栈帧
程序执行:
1.造成StackOverFlowError和OutOfMemoryError(OOM)的原因
2.在JVM的栈内存中保存有栈帧,所有的栈内存采用先进后出的数据结构来进行存储。
java对象访问模式
在很多面向对象语言里面会存在有一个句柄的概念,而Java是没有提供句柄的概念的,这个概念的产生主要是在引用数据类型上,假设现在有如下一段代码:
Object obj = new Object();
按照最初所学,此代码实际分为两个环节考虑:
Object obj :声明对象,实际上此处表示的是一个本地的引用,那么这个本地的引用本身一定会保留有一个堆内存的地址,遗憾的是,在这之中,实际上还会包含有一个本地变量表的概念,也就是说,引用类型通过本地变量表才能够找到一个具体的堆内存的地址。
obj = new Object() :实例化对象,实例化对象就会开辟堆内存空间,开辟对象过大会产生OOM错误
本地变量表:(在java栈内存之中)
栈内存和堆内存保存在不同的内存区域中

在进行引用设计的过程之中有两种做法:
通过句柄进行访问:(C++)

直接指针访问:
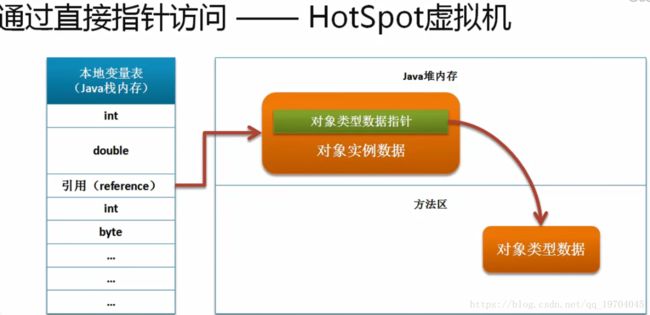
以上所见到的是HotSpot虚拟机本身实现的引用类型的访问机制,但是对于java虚拟机,实际上存在有三种规范的。
JVM规范标准:

现在搞JVM虚拟机最具有权威性的只有Oracle公司,因为其拥有了两个虚拟机的版权。如果要想知道当前自己使用的虚拟机是什么版本,可以直接在命令行输入java -version
查看:
C:\Users\Administrator>java -version
java version “1.7.0_80”
Java(TM) SE Runtime Environment (build 1.7.0_80-b15)
Java HotSpot(TM) 64-Bit Server VM (build 24.80-b11, mixed mode)
默认使用的虚拟机标准 都是HotSpot
当前虚拟机采用的是混合模式(mixed mode),即解释与编译,此时的编译明确的描述的是在JVM运行的时候的编译处理,不是简单的讲.java文件变为.class文件那么简单。这里面包含了一个JIT(Just is Time、即时编译),也就是说当JVM启动的时候只是对类文件做了一个加载,真正编译执行的时候是在JVM执行的过程动态完成的。
当然也可以改变这种处理模式,只需要追加一些参数即可:
范例:将java程序以纯解释的模式进行执行
java -Xint -version
C:\Users\Administrator>java -Xint -version
java version “1.7.0_80”
Java(TM) SE Runtime Environment (build 1.7.0_80-b15)
Java HotSpot(TM) 64-Bit Server VM (build 24.80-b11, interpreted mode)
表示java程序将按照解释的模式来执行
范例:变为纯编译模式:
java -Xcomp - version
C:\Users\Administrator>java -Xcomp -version
java version “1.7.0_80”
Java(TM) SE Runtime Environment (build 1.7.0_80-b15)
Java HotSpot(TM) 64-Bit Server VM (build 24.80-b11, compiled mode)
模式切换对于我们意义不大。
以上只是针对于HotSpot虚拟机的操作进行了一个简单的扩展,但是真正的一个核心问题不在于此,而在于JVM是要以什么样的方式执行?
(java本身具备图形化的界面)
现在从事于java是不会去考虑图形化界面的,实际上这一原则在虚拟机上也是有所体现的。
JVM的运行有两种启动模式:
client:本地的客户端程序,单机版程序,这种程序占用内存小,启动速度快,(已经不用)
server:服务器模式,启动速度慢,该程序占用的内存较大。(针对所有用户进行高性能处理)
如果想要确定当前JVM所采用的运行模式可以直接打开一个配置文件:
D:\jdk-7-7u80\jre-1.7\lib\amd64\jvm.cfg
里边内容很简单:
-server KNOWN
-client IGNORE
默认情况下就这两种
默认启动的是server模式完成的JVM运行,两个互换不可以,必须有对应的文件,比如server模式会有一个匹配的文件夹:
D:\jdk-7-7u80\jre-1.7\bin\server
如果有人问:JVM默认的运行模式?
HotSpot虚拟机采用了混合模式的模式来运行;
运行的形式使用的是server模式,该模式占用的内存大,启动的速度慢,但是处理的效率最高
JAVA从整体而言,要求在服务端发展,而非客户端发展。