中文情感分类(基于CNN)
中文情感分类(基于CNN)
先来看看基于CNN的文本分类的原理
好多地方都用这个图,所以也用这个来絮叨絮叨。深度学习的长处就是善于处理“密集”, “相关”的数据,无论是图像数据还是文本数据,都存在很强的依赖性,但是也存在较强的冗余,我们“扣掉”图像中的一小块或者文字中某个文字,对我们理解图像和文本并没有太大的影响。所以我们可以通过CNN中的卷积来提取,压缩图像的特征,通过RNN来抽取时序数据的特征。在这个方面来说,其实CNN和RNN是相似的,所以当使用RNN抽取完文本的特征之后,我们自然而然的就会思考,能否直接使用CNN来进行文本特征的抽取。答案是确定一定以及肯定的。
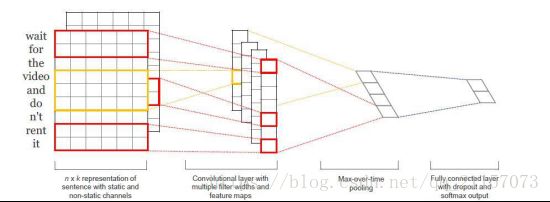
上面就是使用CNN抽取文本信息的原理,“wait for the video and do not rent it” 是我们需要处理的数据。我们将其处理为图像格式的数据,如图中所示,每一行就表示一个词的词向量,完成“图像”的构造后,就需要对其进行卷积。这里使用的卷积核比较特别,其大小是(step, Embedding_Size)在完成卷积后可得到对应的特征图,这里需要注意的是,并不是一次卷积,比如对这个“图像”进行卷积的时候(假设文本长度都为50),我们采用(2,100),(3, 100), (4,100)的卷积和进行卷积后分别得到(49, 1, 126), (48, 1, 126), (47, 1, 126)的特征图。然后采用max_pool采样,依次采样为(1,1,126), (1, 1, 126), (1, 1, 126),然后进行拼接最后添加分类层。其实也是挺简单的,直接撸代码:
import pandas as pd
from tensorflow.contrib import learn
from keras.layers.embeddings import Embedding
from keras.layers.recurrent import LSTM
from keras.models import Sequential, load_model, Model
from keras.layers import Dense, Input, Reshape, MaxPooling2D, Concatenate, Flatten, Dropout
from keras.layers.convolutional import Conv2D
import numpy as np
import os
MAX_DOCUMENT_LEN = 30
EMBEDDING_SIZE = 100
def train():
train = pd.read_csv("all.csv", encoding="utf-8")
# fit generate
def get_generate(batch_size):
while True:
sample_data = train.sample(batch_size)
labels = sample_data.label.values
contents = sample_data.content.values
contents = [list(seq) for seq in contents]
x = []
for seq in contents:
item_str = ""
for word in seq:
item_str += " " + str(word)
x.append(item_str)
x = np.array(list(processor.transform(x)))
y = np.array([[1, 0] if int(item) == 0 else [0, 1] for item in labels])
yield x, y
all_word = set([word for seq in train.content.values for word in list(seq)])
if os.path.exists("processor"):
processor = learn.preprocessing.VocabularyProcessor.restore("processor")
else:
processor = learn.preprocessing.VocabularyProcessor(max_document_length=MAX_DOCUMENT_LEN)
processor.fit(all_word)
processor.save("processor")
# fit generate
def get_generate(batch_size):
while True:
sample_data = train.sample(batch_size)
labels = sample_data.label.values
contents = sample_data.content.values
contents = [list(seq) for seq in contents]
x = []
for seq in contents:
item_str = ""
for word in seq:
item_str += " " + str(word)
x.append(item_str)
x = np.array(list(processor.transform(x)))
y = np.array([[1, 0] if int(item) == 0 else [0, 1] for item in labels])
yield x, y
# create embedding
inputs = Input(shape=(MAX_DOCUMENT_LEN,), dtype="int32")
embedding = Embedding(input_dim=len(all_word), output_dim=EMBEDDING_SIZE)(inputs)
reshape = Reshape((MAX_DOCUMENT_LEN, EMBEDDING_SIZE, 1))(embedding)
conv_1 = Conv2D(filters=126, kernel_size=(2, EMBEDDING_SIZE), activation="relu")(reshape)
conv_2 = Conv2D(filters=126, kernel_size=(3, EMBEDDING_SIZE), activation="relu")(reshape)
conv_3 = Conv2D(filters=126, kernel_size=(4, EMBEDDING_SIZE), activation="relu")(reshape)
max_1 = MaxPooling2D(pool_size=(MAX_DOCUMENT_LEN - 2 + 1, 1), strides=1)(conv_1)
max_2 = MaxPooling2D(pool_size=(MAX_DOCUMENT_LEN - 3 + 1, 1), strides=1)(conv_2)
max_3 = MaxPooling2D(pool_size=(MAX_DOCUMENT_LEN - 4 + 1, 1), strides=1)(conv_3)
concat = Concatenate(axis=1)([max_1, max_2, max_3])
flatten = Flatten()(concat)
droup_out = Dropout(0.5)(flatten)
output = Dense(units=2, activation='softmax')(droup_out)
model = Model(inputs=inputs, outputs=output)
model.compile(loss='categorical_crossentropy', optimizer='sgd')
model.fit_generator(get_generate(50), samples_per_epoch=1000, epochs=10)
model.save("text_cnn.model")