spring-data-jpa 入门
什么是jpa
系列文章:
spring-data-jpa 入门二:常用技术使用之关联关系查询配置
spring-data-jpa 入门三:常用技术使用之复杂查询
偶然情况下看了一篇讨论的帖子内容大概是在说jpa与mybatis的技术选型这是地址,哈哈不怕出丑,其实当时我对jpa的印象,还只停留在jpa只是一套orm规范,除了这个就一无所知了!阅读这个技术选型的帖子时候还处于看热闹的心态,越看越惊艳到我,原来jpa还可以这么玩!然后掉坑里了,自己搭了一套环境实验,后面的所有内容也是本人血泪总结,如有问题欢迎指正,毕竟我也是刚刚接触!
话不多说上目录:
- 为什么使用jpa
- spring data jpa 环境搭建
- 简单使用 增删改查
- 常用技术使用
- 多表关联关系查询
- 原生sql查询
- 动态sql(两种方式:Criteria、继承JpaSpecificationExecutor)
- 多表多条件复杂查询
- 动态查询(复杂条件 in、join 等)
- 常用技术使用
- 批量操作、EntityManager状态分析
- 常用注解总结
- json解析时延迟加载问题
1. 为什么使用jpa
这个问题是我研究spring-data-jpa 之前反复问自己的一个问题,具体分析了一下:
1. mybatis最大优点就是便利的 SQL 操作,自由度高,封装性好,很多复杂的sql,在Navicat上写出来直接复制到xml中就搞定了。
2. 对于jpa来说最大的优点就是对于dao层使用非常方便快捷,甚至可以不需要dao层实现,直接定义接口。
3. 如果只是简单业务仅仅只单表查询对于mybatis来说臃肿程度太高,虽然有代码生成工具还是感觉不是太满意。
4. 如果是复杂的sql查询,特别是无关联关系两张表做复杂查询(例如数据字典表与其他业务表关联),jpa使用起来特别复杂。但是现在主流的分布式架构,貌似越来越淡化多表复杂关联业务查询在一个节点上完成。
最后不得不说mybatis与jpa各有千秋,要因地适宜选择。
2. spring data jpa 环境搭建
搭建环境之前还是想说下:
1. 什么是spring-data-jpa:简单来说就是spring 自己做的orm框架spring-data,其中有很多版本,包括,Spring-data-jpa,Spring-data-template,Spring-data-mongodb,Spring-data-redis等。
2. 我们在使用持久化工具时候一般会有个对象来操作数据库,hibernate中是session,在hibernate与spring集成中我们就是集成进sessionFactory,mybatis中是sqlSession,与spring集成时候就是添加一个sqlSessionFactoryg工厂,那么在spring-data-jpa中我们其实就是集成entityManagerFactory。
下面开始搭建环境:
1. maven 引入相关jar包,这三个是最核心的包,其中spring-data-jpa这个jar包与其他包冲突的非常多,需要自己去排除,lombok是自动生成get/set 等方法的jar包。
<dependency>
<groupId>org.springframework.datagroupId>
<artifactId>spring-data-jpaartifactId>
<version>1.11.5.RELEASEversion>
dependency>
<dependency>
<groupId>org.hibernategroupId>
<artifactId>hibernate-coreartifactId>
<version>5.0.7.Finalversion>
dependency>
<dependency>
<groupId>org.hibernategroupId>
<artifactId>hibernate-entitymanagerartifactId>
<version>5.0.7.Finalversion>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.16.20version>
<scope>providedscope>
dependency>
2. spring的配置文件中关于spring-data-jpa相关配置了
<aop:aspectj-autoproxy proxy-target-class="true"/>
<bean id="entityManagerFactory"
class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="packagesToScan" value="com.herman.di.entity"/>
<property name="persistenceProvider">
<bean class="org.hibernate.ejb.HibernatePersistence"/>
property>
<property name="jpaVendorAdapter">
<bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter">
<property name="generateDdl" value="true"/>
<property name="database" value="MYSQL"/>
<property name="databasePlatform" value="org.hibernate.dialect.MySQL5InnoDBDialect"/>
<property name="showSql" value="true"/>
bean>
property>
<property name="jpaDialect">
<bean class="org.springframework.orm.jpa.vendor.HibernateJpaDialect"/>
property>
<property name="jpaPropertyMap">
<map>
<entry key="hibernate.query.substitutions" value="true 1, false 0"/>
<entry key="hibernate.default_batch_fetch_size" value="16"/>
<entry key="hibernate.max_fetch_depth" value="2"/>
<entry key="hibernate.generate_statistics" value="true"/>
<entry key="hibernate.bytecode.use_reflection_optimizer" value="true"/>
<entry key="hibernate.cache.use_second_level_cache" value="false"/>
<entry key="hibernate.cache.use_query_cache" value="false"/>
map>
property>
bean>
<bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager">
<property name="entityManagerFactory" ref="entityManagerFactory"/>
bean>
<jpa:repositories base-package="com.herman.di.dao" repository-impl-postfix="Impl"
entity-manager-factory-ref="entityManagerFactory" transaction-manager-ref="transactionManager"/>
beans>
在这里简单说明下配置文件的含义:
1. 原生jpa中需要将jpa的配置信息放在META-INF目录下面的,并且名字必须叫做persistence.xml,但是spring-data-jpa在这基础之上进行了封装
org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean
能让我们将这个配置文件放在任意位置,甚至可以直接配置出来,直接通过packagesToScan属性配置我们的bean存放的位置,以加载entity。
<property name="packagesToScan" value="com.herman.di.entity"/>
前面提到过jpa是不需要写dao层实现的,当然如果想写spring-data-jpa是支持的,下面这段的配置就是说明你的dao层实现位置,在jpa中dao层是叫Repository(容器;仓库),repository-impl-postfix属性代表接口的实现类的后缀结尾字符,spring-data-jpa的习惯是接口和实现类都需要放在同一个包里面,再次的,这里我们的实现类定义的时候我们不需要去指定实现接口,spring-data-jpa自动就能判断二者的关系(自定义实现可以参考)
<jpa:repositories base-package="com.herman.di.dao" repository-impl-postfix="Impl"
entity-manager-factory-ref="entityManagerFactory"
transaction-manager-ref="transactionManager"/>到这里spring-data-jpa就已经与spring集成完毕,是不是很简单,我本人搭建的时候也就是在jar包冲突的时候花费了点时间。
3. 简单使用 增删改查
dao层的简单增删改查才是jpa的威力提现,也是它吸引人的地方,通过一个完整的项目来演示一下:
Entity层
package com.herman.di.entity;
import lombok.Data;
import javax.persistence.*;
import java.io.Serializable;
/**
* 用户实体
*
* @author hsh
* @create 2018-08-30 11:49
**/
@Data
@Entity
@Table(name = "user_info")
public class UserInfo implements Serializable {
private static final long serialVersionUID = -12285021873923699L;
@Id
@Column(name = "id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
@Column(name = "uname")
private String uName;
@Column(name = "unumber")
private String uNumber;
@Column(name = "password")
private String password;
}解释下:
1. @Data 是 lombok 的注解,作用是自动生成object类中的get、set方法,这样的话代码更加简洁,具体的可以百度下lombok。
2. @Entity 表示这个类是和数据库中某个表对应的实体
3. @Table(name = “user_info”) 该实体所对应的具体表名,与@Entity 配合使用。
4. @Id 主键
5. @Column(name = “id”) 对应的列明
6. @GeneratedValue(strategy = GenerationType.IDENTITY) 主键生成策略,strategy:表示主键生成策略,有AUTO,INDENTITY,SEQUENCE 和 TABLE 4种,分别表示让ORM框架自动选择,根据数据库的 Identity 字段生成,根据数据库表的 Sequence 字段生成,以有根据一个额外的表生成主键,默认为 AUTO。
当然对应的注解还有一些,后面会详细说明,这里就不多拓展了。
**Dao层**
package com.herman.di.dao;
import com.herman.di.entity.UserInfo;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
/**
* 用户信息dao
* Created by hsh on 18/08/30.
*/
public interface UserInfoRepository
extends JpaRepository, JpaSpecificationExecutor {
UserInfo findById(Integer id);
/**
* 原生分页 查询条件不能为空
*/
Page findByUNameContainingAndUNumberEqualsAndIdEquals(String uName,
String uNumber, Integer id, Pageable pageable);
}
dao层就结束了,是不是很简单,不用写实现类jpa自动代理搞定。
dao层我们基本什么都没干,就是继承了JpaRepository这个接口和JpaSpecificationExecutor这个接口,其实如果不是复杂的查询,JpaSpecificationExecutor是可以不用继承的。
然后我们定义了一个 findById ,见名知意就是根据id查询用户信息,如果在mybatis中我们是不是要写实现大致应该是这样的:
select * from user_info t where t.id=#{id} 现在jpa实现不用写了jpa会自动实现根据方法名组装sql查询,打印出的sql信息为:
select * from user_info t where t.id=?是不是和我们自己写的实现差不多,而且我们只定义两个方法(甚至可以一个方法都不写)就满足了基本的增删改查的业务需求。那么spring-data-jpa具体是怎么实现的呢?
首先我们一切的秘密都在我们继承了 JpaRepository 接口,这个接口只是定义了我们常用的dao层操作
public interface JpaRepository<T, ID extends Serializable>
extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
List findAll();
List findAll(Sort var1);
List findAll(Iterable var1);
List save(Iterable var1);
void flush();
S saveAndFlush(S var1);
void deleteInBatch(Iterable var1);
void deleteAllInBatch();
T getOne(ID var1);
List findAll(Example var1);
List findAll(Example var1, Sort var2);
} 是不是大部分都满足你的需求,得益于cglib 代理,spring-data-jpa 默认所有继承JpaRepository接口的实现为SimpleJpaRepository,
public class SimpleJpaRepository<T, ID extends Serializable> implements JpaRepository<T, ID>,
JpaSpecificationExecutor<T>也就是说无论你写不写实现最后都会是SimpleJpaRepository来实现的你接口。这也就是我们dao层可以不写方法的原因。
至于为什么定义一个方法名就可以,不用写实现,spring-data-jpa 默认会解析以 findby开头的方法名,并生成sql,我们只需要遵循官方文档给的规则就行。
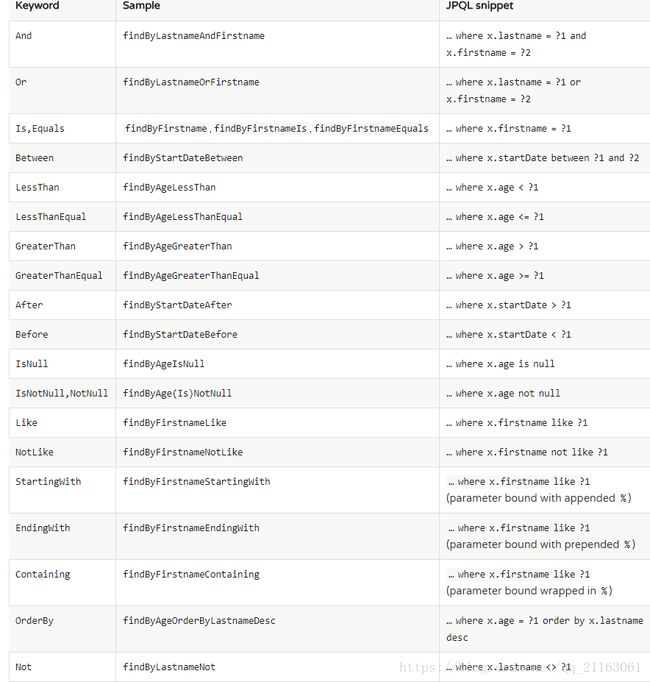
这里我只贴了一部分,具体地址可以去官方瞅瞅。
同样的 下面这个方法就是根据含有分页的返回结果,spring-data-jpa会自动封装,Pageable 是 分页信息 在org.springframework.data.domain.Pageable包下,通常我们会用它的子类 PageRequest来封装分页信息。
Page findByUNameContainingAndUNumberEqualsAndIdEquals(String uName,
String uNumber, Integer id, Pageable pageable); dao层差不多解释到这复杂情况下文在继续探讨。
Service层
service层简写直接调用dao层了
package com.herman.di.service.impl;
import com.herman.di.dao.UserInfoRepository;
import com.herman.di.entity.UserInfo;
import com.herman.di.service.UserInfoService;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
/**
* 用户接口实现
*
* @author hsh
* @create 2018-08-29 15:59
**/
@Service
public class UserInfoServiceImpl implements UserInfoService {
@Resource
private UserInfoRepository userInfoRepository;
public UserInfo getUserInfoById(String userId) throws Exception {
UserInfo one = userInfoRepository.findById(Integer.valueOf(userId));
return one;
}
public boolean addUserInfo(UserInfo userInfo) throws Exception {
UserInfo save = userInfoRepository.save(userInfo);
if (save != null && save.getId() != null)
return true;
return false;
}
}这里我们直接代用了我们在dao层定义的方法就可以了。前面说过因为我们dao层继承了JpaRepository这个接口,因此常规的增删改查都已经写好,另外需要注意的是新增和修改是一个方法 save(S entity) ,它里面是这么写的:
@Transactional
public S save(S entity) {
if(this.entityInformation.isNew(entity)) {
this.em.persist(entity);
return entity;
} else {
return this.em.merge(entity);
}
}代码还是比较简单,就是判断是否存在,不存在就新增,否者修改。
查找时候排序的话,我们可以看下JpaRepository为我们提供的
List<T> findAll(Sort var1);
<S extends T> List<S> findAll(Example<S> var1);
<S extends T> List<S> findAll(Example<S> var1, Sort var2);Sort 是个排序条件 构造参数:
Sort(Sort.Order... orders)
Sort(List<Sort.Order> orders)
Sort(String... properties)
Sort(Sort.Direction direction, String... properties)见名知意,第一个方法传入 order 参数,第二个方法传入多个orders,第三个传入需要排序的字段,第四个传入的是升序还是降序,和需要排序的字段。
Example< S> 可以理解为查询条件,下文我们在探讨。
到此,我们了解到spring-data-jpa是什么、简单的实现原理、简单的增删改查、以及简单的分页查找、排序。
下文我们将继续探讨更为复杂的情况
- 常用技术使用
- 多表关联关系查询
- 原生sql查询
- 动态sql(两种方式:Criteria、继承JpaSpecificationExecutor)
- 多表多条件复杂查询
- 动态查询(复杂条件 in、join 等)
- 批量操作、EntityManager状态分析
- 常用注解总结
- json解析时延迟加载问题
spring-data-jpa 入门二:常用技术使用之关联关系查询配置