Automatic Pixelwise Object Labeling for Aerial Imagery Using Stacked U-Nets 翻译
Automatic Pixelwise Object Labeling for Aerial Imagery Using Stacked U-Nets
通过堆叠Unet网络对航空影像自动像素标记
原文链接:https://arxiv.org/pdf/1803.04953.pdf
摘要--航拍图像中物体标记的自动化是具有许多实际应用的计算机视觉任务。像能源勘探这样的领域需要一种自动化方法来每天处理连续的图像流。在本文中,我们提出了一个管道来解决这个问题,使用一堆卷积神经网络(U-Net架构)达到端对端。每个网络作为前一个网络的后处理器。我们的模型在两个数据集上优于现有模型:Inria航空影像标签数据集和Massachusetts建筑数据集,他们有不同的特征如空间分辨率,物体形状和尺寸。此外,我们通过对下采样图像和上采样像素标签图像的处理节省计算时间。这种节省造成的分割质量下降可以忽略不计。虽然本文进行的实验只包括航空影像,但是技术是通用的,可以处理其他类型的图像。
关键词:遥感;语义分割;U-Net;物体标签;深度卷积神经网络
- 引言
自从引入高空间和时间分辨率的遥感影像服务以来,遥感影像成为各行各野的重要组成部分之一。能源,采矿,民用,国防和更多行业都能够使用航拍图像来提高他们的生产力和工作质量。最昂贵也最耗时的需要使用航空影像的任务之一是标签任务。此外,对感兴趣物体进行标记需要领域专业知识才能完美标注。
最近在使用深度学习方法的图像理解技术方面的突破以及硬件技术的飞跃特别是GPU为更多的研究人员打开了大门,以尝试不同的方法和技术。深度学习方法现在可以以可承受的成本部署在工业中。
通常,可以通过两种方式来处理对象标记:localization和分割。 定位是围绕检测到的对象绘制边界框的位置。localization的问题是边界框实际上并不代表对象的边界,也无法描述其形状。相反,分割是标记表示对象的像素/超像素。这将导致对对象的形状,大小和轮廓进行非常详细的检测。由于感兴趣的物体通常不具有均匀或固定的形状,我们选择分割方法以获得更准确的结果。
本文有两个主要贡献:首先,我们介绍了一种基于堆叠U-net的新DCNN语义图像分割架构,其中每个网络都增强了前一个网络的结果。 在我们的航空影像实验中,两个U-Nets的级联足以胜过两个不同数据集的当前最新技术,每个数据集具有不同的特征。 其次,我们试验了图像空间分辨率对我们模型性能的影响。 我们发现原始分辨率的缩减可以显着减少计算时间,但代价是分割质量的损失可以忽略不计。
接下来的部分组织如下。 第2节说明了语义图像分割文献中的相关工作。 第3节详细介绍了我们处理高质量细分的方法。 第4节介绍了不同的实验和结果,以证明我们的方法的力量。 最后,论文的结论和未来工作的方向见第5节。
2.相关工作
语义图像分割是将图像划分为有意义的部分的过程,每个部分属于预先指定的类之一。 用于语义分割的方法可以分为:传统和深度学习方法。 传统方法通常依赖于领域知识来提取特征并将这些特征应用于以下技术:Texton 森林[1],随机森林[2][3],SVM [4],[5]和条件随机场(CRF)[6]。
语义分割可以帮助解决的挑战之一是从场景中提取感兴趣的对象。我们在本文中试图解决的问题是从先前使用不同方法尝试的航空图像中提取建筑物。 其中许多方法使用手工制作的特征,分类器和增强[7] - [9]或轮廓检测来找到矩形(类似建筑物)的物体[10]。

李[11]等人使用无监督高斯混合模型(GMM)将图像分割成均匀的超像素,然后使用高阶条件随机场(HCRF)进行精确的屋顶提取。 Jin和Davis [12]使用基于边缘的分割方法生成建立假设,并使用差分形态分析(DMP)对其进行验证。 使用结构,上下文和光谱信息提取建筑物。
近年来,深度学习方法在包括语义分割在内的许多领域中表现出了卓越的表现。龙[13]等人引入了全连接网络(FCN)作为产生密集输出映射的端到端架构。 Long还介绍了使用反卷积层进行上采样的概念。 由于对象位置在语义分割中非常重要 - 与分类不同 - 开发了新的架构来保留这些位置信息。
第一组体系结构受到编码器 - 解码器的思想的启发,其中输入图像使用池化层被编码成较小的中间形式,然后使用解码器中的上采样层通常借助于从编码器到解码器的跳过连接来恢复到原始大小。 这套最受欢迎的架构是:(1)Ronneberger等人介绍的U-Net。14]最初用于医学图像分割。U-Net以大幅度赢得了2015年ISBI细胞追踪挑战。(2)SegNet[15]不使用跳过连接并保存要在解码器中用于非线性上采样的池化索引。
一组不同的体系结构取决于空洞(也称为扩张)卷积[16]而不是池化层。 在空洞卷积滤波器中,“带孔”使得我们可以在不降低图像空间分辨率的情况下放大滤波器的感受野。
Volodymyr Mnih在他的博士论文[17]中使用卷积神经网络来训练道路和建筑物的航空图像标记系统。他尝试将神经网络和条件随机场作为CNN的后处理。他的模型在马萨诸塞州道路和建筑物数据集上表现良好[17]。
Saito和Aoki[18]使用CNN进行道路和建筑物检测。他们使用CNN的正常下采样架构,最后,添加了一个带Dropout[19]的完全连接层来推断输入图像的预测。他们的模型优于为每个类别道路和建筑物使用单一模型的Mnih模型[17]。
纽厄尔[20]等人提出了一种网络体系结构,该体系结构在人体姿态估计中达到了最先进的结果。由于其收缩和扩展路径的形状,他们将其架构称为沙漏。这种架构是与U-Net非常相似,它只是在连接张量的方式上有所不同。沙漏使用加法运算符将两个张量加在一起形成一个新的和张量。人体姿势估计问题可以被表达为来自输入图像的提取关节的任务。有了这个配方,我们可以针对语义图像分割任务调整相同的网络架构。
3.方法
我们的完整流水线概述如图1所示。我们的流水线首先将输入图像划分为224x224x3像素的像素块。这些像素块是我们模型的输入,输出是裁剪预测掩码。 通过连接这些小输出,我们可以获得全尺寸预测掩模。 更多级别的U-Nets用于增强结果。
- 网络结构
如图2所示,我们的大多数层由3x3卷积滤波器组成,因为它们具有计算效率。 当我们在收缩路径中更深入时,过滤器的计数加倍,而在通过扩展路径时它们减半。 每层还具有批量标准化[21]层,以实现更快的收敛。 大小为2x2的最大池化用于下采样,而对于上采样,原始张量中的元素被复制到输出上采样张量中的2x2窗口。 通过将两个张量附加到新的激活量来完成连接。 最后,He均匀方差缩放初始化器[22]用于所有卷积层。
将整个图像分割成较小的斑块将导致斑块边缘上的建筑物失去其结构的重要部分,这导致边缘处的不良性能。 这个问题可以通过两种方式解决:使用重叠的补丁或在我们的网络中使用裁剪层。 我们使用裁剪层,因为它证明是更有效的解决方案[23]。

(1)训练:Nadam优化器[24]用于训练模型。 对于第一级U-Net,学习速率1e-3用于50个时期,然后1e-4用于另外50个时期。 批量大小为128个补丁。 第二级U-Net使用1e-4的学习率并且训练50个时期。 由于联合交叉(IoU)成为语义图像分割中的标准度量[13]并且它是不可微分的,因此Iglovikov等人提出了联合损失函数L. [23]用于结合可微分形式的IoU和二元交叉熵

其中n是批次中的图像数量,y是地面实况值,y帽是预测值。
此外,通过从一组变换中随机选择,在训练时应用数据增强:水平翻转,垂直翻转和旋转。 数据增强有助于构建一个较少依赖于输入图像方向的强大模型。这对我们的模型非常有用,可以推广到训练集中不同区域以外的其他区域。
(2)预测:为了进行更自信的预测,应用测试时间增加,其中在训练时应用的同一组变换在预测之前应用于每个图像块。所有转换版本的预测均为平均值。该平均值是最终预测分数。然后,应用阈值处理将分数转换为掩码的二进制值。阈值是我们使用交叉验证集调整的超参数。
为了减少图像子区域对图块的不连续性影响,我们使用Ronneberger等人提出的图像镜像[14]。 这在瓦片边界处产生更好的结果。 我们的管道是使用Keras [25]库和Theano [26]作为后端构建的。
4.结果
在本节中,我们将介绍用于实验的数据集,并报告已进行的实验及其实验
结果。
- 数据集
为了说明所提模型的功效,我们使用两个数据集:Inria航空图像标记数据集[27]和马萨诸塞建筑数据集[17]。 我们选择了这两个数据集,因为它们涵盖了不同的图像特征,如空间分辨率,对象类型,形状和大小。
Inria的数据集专门用于解决航空影像的自动像素标注问题。 数据集由两个子集组成:训练集和测试集。 每个子集覆盖405平方公里的区域,空间分辨率为0.3米。 提供的数据是3波段彩色正射校正图像。训练数据标记为两类:建筑物而不是建筑物。 训练数据集涵盖奥斯汀,芝加哥,基茨普普县,西蒂罗尔和维也纳,而测试集涵盖了一系列不同的地区:贝灵厄姆,布卢明顿,因斯布鲁克,旧金山,东蒂罗尔。 对于两个子集中的每个区域,有36个大小为5000x5000像素的区块,覆盖1500x1500米区域。 数据集图像和标签中的样本如图4所示。


选择Inria数据集进行实验有两个重要方面。 首先,培训和测试集涵盖不同的区域,因此我们将能够判断我们的模型推广到新区域的能力。 其次,覆盖区域的城市密度差异很大。 图3显示了不同地区的各种城市密度。 芝加哥拥有非常密集的小型建筑。由于其大型绿地,Kitsap县的建筑物分布非常稀少。 维也纳有着截然不同的建筑风格:没有完整屋顶的大型建筑。 数据集中的这种可变性确保模型将学习标记不同区域并在更一般意义上理解建筑物的结构。
为了与其他研究人员的结果进行比较,我们使用每个数据集的相同性能度量。 Inria的数据集使用了两个主要的性能指标:联盟交叉(IoU)和准确性。 联合交叉,也称为Jaccard索引,定义为:

其中GT是地面真实掩模,P是预测掩模。 准确度定义为:

我们将实验集中在IoU上,因为它成为语义分割的标准[13]。 此外,由于大图像区域专用于背景(非建筑)类,因此精度不具有足够的辨别力。
对于马萨诸塞州建筑物数据集,使用松弛版本的精度和召回来计算精确召回盈亏平衡点[17]。松弛假设是如果正标签落在任何地面实况正像素的7x7区域内,则认为正标签是正确的。由于建筑物的面具通常与图像不完全对齐,因此这种放松将提供真实的性能测量。
- 最好的模型结果
在完成所有实验并选择第III部分中描述的最佳模型后,我们将结果与表I中所示的其他方法的结果进行比较。图6显示了来自测试集的因斯布鲁克图像的模型结果。 该图显示了具有不同形状(矩形和非矩形)和尺寸的建筑物的检测。

在某些情况下,我们的模型计算错误的分割结果。 例如,在图7中,我们可以看到模型检测停车场作为建筑物,因为其颜色与该区域中的建筑物颜色非常相似,并且由于其质地看起来像房屋的屋顶。

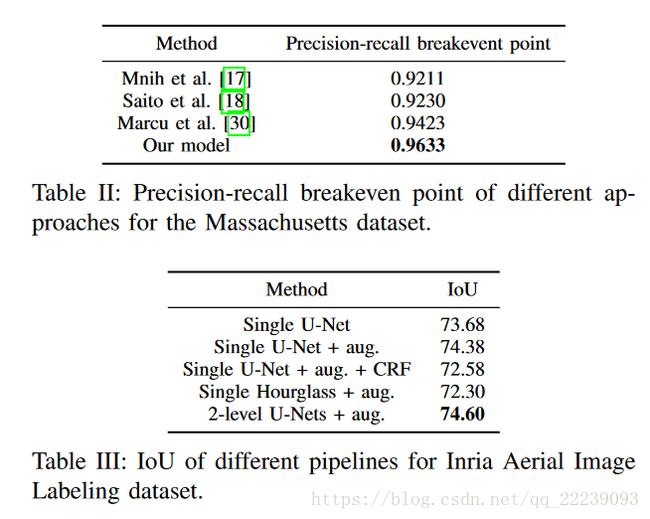
表II显示了我们在马萨诸塞州建筑数据集上的模型结果。 我们明显优于文献中的其他方法。 图8显示了我们的模型预测示例。 虽然这两个数据集的特征完全不同,但我们的模型在具有相同架构的两个数据集上都具有领先的结果。

Nvidia Tesla K80 GPU上第一架U-Net的培训时间为41小时,而第二架U-Net的培训时间为20.8小时。单个大小(5000x500像素)的预测需要3.48分钟,包括增强,连接小补丁和阈值。
- 不同的架构和管道
在展示我们的模型最佳结果后,我们在本节中介绍了我们已经尝试过的几种变体。 目标是突出导致我们模型卓越性能的关键因素。 表III显示了对Inria数据集进行的不同实验的结果。 使用单个U-Net架构直接预测图像是一个很好的起点。 由于数据增加对于生成对不同旋转和方向不变的鲁棒模型非常重要,我们通过运行具有相同配置的单个U-Net的相同模型以及两种训练的增强来测试其对结果的影响和测试时间。此更改会导致验证集的IoU增强,如结果中所示
将Hourglass[20]架构与数据扩充应用于我们的问题,得到的IoU得分为72.30。 尽管Hourglass没有产生更好的结果,但它引导我们了解网络堆叠的概念(我们的最终管道)。 堆叠Hourglass架构由多个连续排列的端对端沙漏组成。
d.下采样
如前所述,Inria数据集的空间分辨率为0.3米。 我们想研究较低分辨率对结果的影响。 为了尝试相同数据的不同分辨率,我们以较低的速率重新采样数据。 我们的实验分两个分辨率进行:原始分辨率为1/2和1/4。 为了确保不同分辨率之间的公平比较,我们在计算Jaccard索引之前使用简单线性插值将低分辨率掩模上采样到预测后的原始分辨率。 较低分辨率的结果非常接近原始分辨率的结果。 但是,预测时间大大节省。 此外,下采样和上采样的开销可以忽略不计(~0.06秒/图像)。 这些研究结果表明,可以用较低的分辨率代替非常高的分辨率,以获得相当大的计算时间增益。


e使用条件随机场(CRF)[31]作为后处理
事实证明,完全连接的CRF对于定位挑战非常有效[16],[32]。 它们能够找到细粒度的边缘和轮廓,从而提高对象分割质量。

使用单个U-Net的CRF在验证集上得分为72.58。 图9清楚地显示了CRF如何绘制检测到的建筑物的详细外边缘和内边缘,但这不是我们的数据集所必需的。 我们的数据集需要一个覆盖整个建筑物的实心多边形,没有任何屋顶细节和线条。 基于这些结果,我们没有将CRF作为后处理器整合到我们的管道中
5结论和未来工作
在本文中,我们提出了一堆基于U-Net [14]架构的深度卷积神经网络,用于对航空图像进行像素标记。 我们的方法优于Inria的航空图像标记数据集[27]和马萨诸塞州建筑数据集[17]上的所有其他模型。 此外,实验表明,通过处理较低分辨率的图像,我们可以在处理时间上获得相当大的增益。 这对于需要快速标记的交互式应用程序非常有用。
对于未来的工作,我们将研究合适的方法,这些方法可以在一个特定的空间分辨率下调整学习模型,以最小的变化处理不同的分辨率,因为这对于从在不同数据集上训练的模型开始学习数据集的模型非常有用。 另一个可能的未来方向是利用生成对抗网络(GAN)[33]通过生成器鉴别器网络对来改善模型分割质量。