分布式数据库TiDB架构及资源调度隔离简介
以下内容均来自TiDB官网,这里只是做了聚合总结
TiDB 整体架构
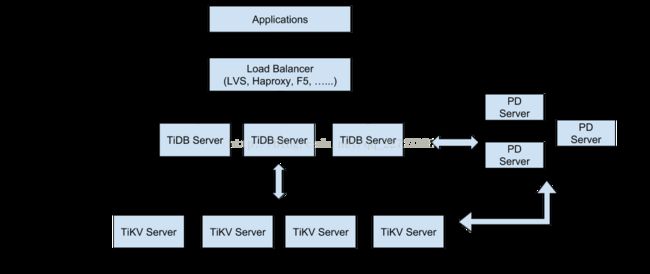
TiDB Server
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果。 TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如LVS、HAProxy 或 F5)对外提供统一的接入地址。
PD Server
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个: 一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);三是分配全局唯一且递增的事务 ID。
PD 是一个集群,需要部署奇数个节点,一般线上推荐至少部署 3 个节点。
TiKV Server
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range (从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region 。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。
集群的调度是通过PD进行的,PD 通过集成 etcd ,自动的支持 auto failover,无需担心单点故障问题。同时,PD 也通过 etcd 的 raft,保证了数据的强一致性,不用担心数据丢失的问题。在架构上PD 所有的数据都是通过 TiKV 主动上报获知的。同时,PD 对整个 TiKV 集群的调度等操作,也只会在 TiKV 发送 heartbeat 命令的结果里面返回相关的命令,让 TiKV 自行去处理,而不是主动去给 TiKV 发命令。
TiDB调度主要是为了满足以下需求:
第一类需求
副本数量不能多也不能少
副本需要分布在不同的机器上
新加节点后,可以将其他节点上的副本迁移过来
节点下线后,需要将该节点的数据迁移走
第二类需求
维持整个集群的 Leader 分布均匀
维持每个节点的储存容量均匀
维持访问热点分布均匀
控制 Balance 的速度,避免影响在线服务
管理节点状态,包括手动上线/下线节点,以及自动下线失效节点
完成调度的三个步骤:收集信息、设置调度策略、调度基本操作
一、收集信息
(1)每个 TiKV 节点会定期向 PD 汇报节点的整体信息
TiKV 节点(Store)与PD之间存在心跳包,心跳包中会携带这个 Store 的状态信息,主要包括:
总磁盘容量
可用磁盘容量
承载的 Region 数量
数据写入速度
发送/接受的 Snapshot 数量(Replica 之间可能会通过 Snapshot 同步数据)
是否过载
标签信息(标签是具备层级关系的一系列 Tag)
同时PD也是通过心跳包检测Store是否存活及是否有新的Store加入。
对于 store 的心跳,PD 在 handleStoreHeartbeat 函数里面处理,主要就是将心跳里面当前的 store 的一些状态缓存到 cache 里面。
(2)每个 Raft Group 的 Leader 会定期向 PD 汇报信息(follower不会上报)
每个 Raft Group 的 Leader 和 PD 之间存在心跳包,用于汇报这个 Region 的状态,主要包括下面几点信息:
Leader 的位置
Followers 的位置
掉线 Replica 的个数
数据写入/读取的速度
对于 region 的心跳,PD 在 handleRegionHeartbeat 里面处理。收到 region 的心跳之后,首先 PD 也会将其放入 cache 里面,如果 PD 发现 region 的 epoch(epoch里面有conf_ver和version,分别表示这个 region 不同的版本状态。如果一个 region 发生了 membership changes,也就是新增或者删除了 peer,conf_ver 会加 1,如果 region 发生了 split 或者 merge,则 version 加 1) 有变化,就会将这个 region 的信息也保存到 etcd 里面。然后,PD 会对这个 region 进行具体的调度
二、调度的策略
(1)一个Region的Replica数量正确
当 PD 通过某个 Region Leader 的心跳包发现这个 Region 的 Replica 数量不满足要求时,需要通过 Add/Remove Replica 操作调整 Replica 数量。出现这种情况的可能原因是:
某个节点掉线,上面的数据全部丢失,导致一些 Region 的 Replica 数量不足
某个掉线节点又恢复服务,自动接入集群,这样之前已经补足了 Replica 的 Region 的 Replica 数量多过,需要删除某个 Replica
管理员调整了副本策略,修改了 max-replicas 的配置
(2)一个 Raft Group 中的多个 Replica 不在同一个位置
注意第二点,『一个 Raft Group 中的多个 Replica 不在同一个位置』,这里用的是『同一个位置』而不是『同一个节点』。在一般情况下,PD 只会保证多个 Replica 不落在一个节点上,以避免单个节点失效导致多个 Replica 丢失。在实际部署中,还可能出现下面这些需求:
多个节点部署在同一台物理机器上
TiKV 节点分布在多个机架上,希望单个机架掉电时,也能保证系统可用性
TiKV 节点分布在多个 IDC 中,向单个机房掉电时,也能保证系统可用
这些需求本质上都是某一个节点具备共同的位置属性,构成一个最小的容错单元,我们希望这个单元内部不会存在一个 Region 的多个 Replica。这个时候,可以给节点配置 lables 并且通过在 PD 上配置 location-labels 来指名哪些 lable 是位置标识,需要在 Replica 分配的时候尽量保证不会有一个 Region 的多个 Replica 所在结点有相同的位置标识。
(3)副本在 Store 之间的分布均匀分配
前面说过,每个副本中存储的数据容量上限是固定的,所以我们维持每个节点上面,副本数量的均衡,会使得总体的负载更均衡。
(4)Leader 数量在 Store 之间均匀分配
Raft 协议要读取核写入都通过 Leader 进行,所以计算的负载主要在 Leader 上面,PD 会尽可能将 Leader 在节点间分散开。
(5)访问热点数量在 Store 之间均匀分配
每个 Store 以及 Region Leader 在上报信息时携带了当前访问负载的信息,比如 Key 的读取/写入速度。PD 会检测出访问热点,且将其在节点之间分散开。
(6)各个 Store 的存储空间占用大致相等
每个 Store 启动的时候都会指定一个 Capacity 参数,表明这个 Store 的存储空间上限,PD 在做调度的时候,会考虑节点的存储空间剩余量。
(7)控制调度速度,避免影响在线服务
调度操作需要耗费 CPU、内存、磁盘 IO 以及网络带宽,我们需要避免对线上服务造成太大影响。PD 会对当前正在进行的操作数量进行控制,默认的速度控制是比较保守的,如果希望加快调度(比如已经停服务升级,增加新节点,希望尽快调度),那么可以通过 pd-ctl 手动加快调度速度。
(8)支持手动下线节点
当通过 pd-ctl 手动下线节点后,PD 会在一定的速率控制下,将节点上的数据调度走。当调度完成后,就会将这个节点置为下线状态。
三、调度的基本操作
三个主要基本操作即可满足调度策略
增加一个 Replica
删除一个 Replica
将 Leader 角色在一个 Raft Group 的不同 Replica 之间 transfer
通过Raft协议的三个命令(AddReplica、RemoveReplica、TransferLeader)就可以支撑上述三种基本操作
调度的大致流程;
PD 不断的通过 Store 或者 Leader 的心跳包收集信息,获得整个集群的详细数据,并且根据这些信息以及调度策略生成调度操作序列,每次收到 Region Leader 发来的心跳包时,PD 都会检查是否有对这个 Region 待进行的操作,通过心跳包的回复消息,将需要进行的操作返回给 Region Leader,并在后面的心跳包中监测执行结果。注意这里的操作只是给 Region Leader 的建议,并不保证一定能得到执行,具体是否会执行以及什么时候执行,由 Region Leader 自己根据当前自身状态来定。
关键 Interface 和 Structure
为了满足不同的调度需求,PD 将调度相关的操作都抽象成了 interface,外面可以自由组合形成自己的调度方案。
Scheduler
Scheduler 是用来调度资源的接口,定义如下:
| type Scheduler interface { GetName() string GetResourceKind() ResourceKind GetResourceLimit() uint64 Prepare(cluster *clusterInfo) error Cleanup(cluster *clusterInfo) Schedule(cluster *clusterInfo) Operator } |
GetName 返回 Scheduler 名字,不同的 scheduler 不能重名。
GetResourceKind 则是返回这个 Scheduler 要处理的资源类型(通过源码发现资源类型现在应该有六种,分别是unknown、admin、leader、region、priority、other)
Scheduler 则是进行实际的调度,它需要的参数就是整个集群的信息 ,在里面会生成实际的调度操作 Operator
Operator
前面我们说了,PD 对于 TiKV 调度的基本单位就是 region,所以 Scheduler 生成的 Operator 就是对一个 Region 进行调度。Operator 定义如下:
| type Operator interface { GetRegionID() uint64 GetResourceKind() ResourceKind GetState() OperatorState SetState(OperatorState) GetName() string Do(region *RegionInfo) (*pdpb.RegionHeartbeatResponse, bool) } |
GetRegionID 得到需要调度的 Region ID
GetResourceKind 的含义跟 Scheduler 的一样。
Do 则是对这个 Region 执行实际的操作,返回一个 RegionHeartbeatResponse。PD 对于 TiKV 的调度操作,都是在 TiKV Region heartbeat 命令里面返回给 TiKV,然后 TiKV 再去执行的。
Selector / Filter
假设我们要进行 storage 的调度,选择了一个 region,那么我们就需要做的是将 region 里面的一个副本 peer,迁移到另外的一个新的 TiKV 上面。所以我们在调度的时候,就需要选择一个合适的需要调度的 TiKV,也就是 source,然后就是一个合适的将被调度到的 TiKV,也就是 target。这个就是通过 Selector 来完成的。
| // Selector is an interface to select source and target store to schedule. type Selector interface { SelectSource(stores []*storeInfo, filters ...Filter) *storeInfo SelectTarget(stores []*storeInfo, filters ...Filter) *storeInfo } |
Selector 的接口非常的简单,就是根据传入的 storeInfo 列表,以及一批 Filter,选择合适的 source 和 target,供 scheduler 实际去调度。
Filter 的定义如下:
| // Filter is an interface to filter source and target store. type Filter interface { // Return true if the store should not be used as a source store. FilterSource(store *storeInfo) bool // Return true if the store should not be used as a target store. FilterTarget(store *storeInfo) bool } |
如果 Filter 的函数返回 true,就表明我们不能选择这个 store。
Controller
Controller 主要用来负责控制整个调度的速度
| // Controller is an interface to control the speed of different schedulers. type Controller interface { Ctx() context.Context Stop() GetInterval() time.Duration AllowSchedule() bool } |
GetInterval 返回调度的间隔时间,当上一次调度之后,需要等待多久开始下一次的调度。AllowSchedule 则是表明是否允许调度。
Coordinator
PD 使用 Coodinator 来管理所有的 Scheduler 以及 Controlller。
| type ScheduleController struct { Scheduler Controller } |
通常,对于调度,Scheduler 和 Controller 是同时存在的,所以在 Coordinator 里面会使用 ScheduleController 来统一进行管理。
Coordinator 在 region heartbeat 的时候,会看这个 region 是否需要调度,如果需要,则进行调度。
另外,在 Coordinator 里面,我们还有一个 replicaCheckController 定期检查 region 是否需要调度。因为 PD 知道整个集群的情况,所以 PD 就知道什么时候该进行调度。譬如,假设 PD 发现一个 TiKV 已经当掉,那么就会对在这个 TiKV 有副本的 region 生成调度 Operator,移除这个坏掉的副本,添加另一个好的副本,当 region heartbeat 上来的时候,直接接返回这个调度策略让 TiKV 去执行。
其他
Region的split
Region默认大小为64m(可调),如果超过64m则会进行split,类似于细胞分裂。
步骤:
1. 在 TiKV 里面,leader peer 会定期检查 region 所占用的空间是否超过某一个阀值,假设我们设置 region 的 size 为 64MB,如果一个 region 超过了 96MB, 就需要分裂。
2. Leader peer 会首先向 PD 发送一个请求分裂的命令,PD 在 handleAskSplit 里面处理,因为我们是一个 region 分裂成两个,对于这两个新分裂的 region,一个会继承之前 region 的所有的元信息,而另一个相关的信息,譬如 region ID,新的 peer ID,则需要 PD 生成,并将其返回给 leader。
3. Leader peer 写入一个 split raft log,在 apply 的时候执行,这样 region 就分裂成了两个。
4. 分裂成功之后,TiKV 告诉 PD,PD 就在 handleReportSplit 里面处理,更新 cache 相关的信息,并持久化到 etcd。
查询的执行
TiDB中的SQL Layer解析SQL,制定查询计划以及生成执行器。然后通过DistSQL API调用一个TiKV的Client,client先从PD获取相关信息,然后访问TiKV,通过 Rpc 发送请求。
例如client要对key写入一个值
1. client 先从 PD 获取 key 属于哪一个 region,PD 将这个 region 相关的元信息返回。
2. client 自己 cache,这样就不需要每次都从 PD 获取。然后直接给 region 的 leader peer 发送命令。
3. 有可能 region 的 leader 已经漂移到其他 peer,TiKV 会返回 NotLeader 错误,并带上新的 leader 的地址,client 在 cache 里面更新,并重新向新的 leader 发送请求。
4. 也有可能 region 的 version 已经变化,譬如 split 了,这时候,key 可能已经落入了新的 region 上面,client 会收到 StaleCommand 的错误,于是重新从 PD 获取,进入状态 1。
TiKV隔离
TiKV采用了Google的一套分布式事务方案 Percolator 的模型,依赖一个单点的授时服务 TSO 来实现单调递增的事务编号生成,提供Repeatable Read(SI)的隔离级别。
全局时间戳 TSO 的生成由Placement Driver负责。
TSO 是一个int64的整形,它由physical time + logical time两个部分组成。Physical time是当前unix time的毫秒时间,而 logical time 则是一个最大1 << 18的计数器。也就是说 1ms,PD最多可以分配262144个TSO,这个能满足绝大多数情况了。
对于 TSO 的保存于分配,PD 会做如下处理:
1.当PD集群中某台机器成为leader之后,会从etcd上面获取上一次保存的时间,如果发现本地的时间比这个小,则会继续等待直到当前的时间大于这个值:
| last, err := s.loadTimestamp() if err != nil { return errors.Trace(err) }
var now time.Time
for { now = time.Now() if wait := last.Sub(now) + updateTimestampGuard; wait > 0 { log.Warnf("wait %v to guarantee valid generated timestamp", wait) time.Sleep(wait) continue } break } |
2.当 PD 能分配 TSO 之后,首先会向 etcd 申请一个最大的时间,譬如,假设当前时间是 t1,每次最多能申请 3s 的时间窗口,PD 会向 etcd 保存 t1 + 3s 的时间值,然后 PD 就能在内存里面直接使用这一段时间窗口.当当前的时间 t2 大于 t1 + 3s 之后,PD 就会在向 etcd 继续更新为 t2 + 3s:
| if now.Sub(s.lastSavedTime) >= 0 { last := s.lastSavedTime save := now.Add(s.cfg.TsoSaveInterval.Duration) if err := s.saveTimestamp(save); err != nil { return errors.Trace(err) } } |
这么处理的好处在于,即使 PD 当掉,新启动的 PD 也会从上一次保存的最大的时间之后开始分配 TSO,也就是 1 处理的情况。
3.因为 PD 在内存里面保存了一个可分配的时间窗口,所以外面请求 TSO 的时候,PD 能直接在内存里面计算 TSO 并返回。
| resp := pdpb.Timestamp{} for i := 0; i < maxRetryCount; i++ { current, ok := s.ts.Load().(*atomicObject) if !ok { log.Errorf("we haven't synced timestamp ok, wait and retry, retry count %d", i) time.Sleep(200 * time.Millisecond) continue }
resp.Physical = current.physical.UnixNano() / int64(time.Millisecond) resp.Logical = atomic.AddInt64(¤t.logical, int64(count)) if resp.Logical >= maxLogical {
time.Sleep(updateTimestampStep) continue } return resp, nil } |
4.如果 client 每次事务都向 PD 来请求一次 TSO,每次 RPC 的开销也是非常大的,所以 client 会批量的向 PD 获取 TSO。client 会首先收集一批事务的 TSO 请求,譬如 n 个,然后直接向 PD 发送命令,参数就是 n,PD 收到命令之后,会生成 n 个 TSO 返回给客户端。
TiKV 的MVCC与两阶段提交
TiKV使用MVCC(Multi-Version Concurrency Control,多版本并发控制)来解决传统两段锁(2PL)读锁和写锁相互阻滞(block)以及读操作阻塞问题。
MVCC只是一个思想,并不是某个特定实现,它表示每条记录都有多个版本,互相不影响,以一个kv数据库为例,从逻辑上的一行表示为
| Record := {key, value, version} |
而不是
| Record := {key, value} |
在TiKV中整个事务模型是构建在一个分布式 MVCC 的基础之上:
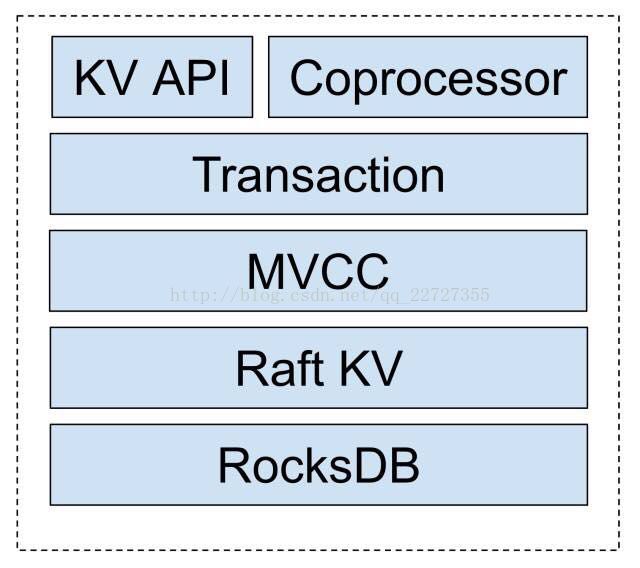
对于 MVCC 层,每一个 Key,在底层的 RocksDB 上都会存储同一个 Key 的多个版本,在底层存储上看来,形式如:
| MateKey --> key 的所有版本信息 DataKey(key+version_1)-->Value_v1 DataKey(key+version_2)-->Value_v2 |
暴露给上层的接口行为定义:
> * MVCCGet(key, version),返回某key小于等于version的最大版本的值
> * MVCCScan(startKey, endKey, limit, version), 返回[startKey, endKey)区间内的key小于等于 version的最大版本的键和值,上限limit个
> * MVCCPut(key, value, version)插入某个键值对,如果version已经存在,则覆盖它。上层事物系统有责任维护自version来避免[read-modify-write]
> * MVCCDelete(key, version) 删除某个特定版本的键值对, 这个需要与上层的事务删除接口区分,只有 GC 模块可以调用这个接口
给出一个 MVCCGet 的伪代码实现:
| MVCCGet(key, version) { versions = kv.Get(key) // read meta targetVer = nil for ver in versions { if ver <= version { targetVer = ver break } } return kv.Get(mvccEncode(key, targetVer)), targetVer } |
核心思想是,先读取 meta key 然后通过 meta key 中找到相应的可见版本,然后再读取 data key,由于这些 key 都拥有相同的前缀,所以在实际的访问中,读放大的程度是可以接受的。
两段提交(2-Phase Commit,2PC)是在 MVCC 中实现的,整个 TiKV 事务模型的核心。
总体来说,TiKV 的读写事务分为两个阶段:1、Prewrite 阶段;2、Commit 阶段。
客户端会缓存本地的写操作,在客户端调用 client.Commit() 时,开始进入分布式事务 prewrite 和 commit 流程。
Prewrite 对应传统 2PC 的第一阶段:
1) 首先在所有行的写操作中选出一个作为 primary row,其他的为 secondary rows
2) PrewritePrimary: 对 primaryRow 写入锁(修改 meta key 加入一个标记),锁中记录本次事务的开始时间戳。上锁前会检查: i.该行是否已经有别的客户端已经上锁 (Locking) ii.是否在本次事务开始时间之后,检查versions ,是否有更新 [startTs, +Inf) 的写操作已经提交 (Conflict) 在这两种种情况下会返回事务冲突。否则,就成功上锁。将行的内容写入 row 中,版本设置为 startTs
3) 将 primaryRow 的锁上好了以后,进行 secondaries 的 prewrite 流程: i.类似 primaryRow 的上锁流程,只不过锁的内容为事务开始时间 startTs 及 primaryRow 的信息 ii.检查的事项同 primaryRow 的一致 iii.当锁成功写入后,写入 row,时间戳设置为 startTs
以上 Prewrite 流程任何一步发生错误,都会进行回滚:删除 meta 中的 Lock 标记 , 删除版本为 startTs 的数据。
当 Prewrite 阶段完成以后,进入 Commit 阶段,当前时间戳为 commitTs,TSO 会保证 commitTs > startTs
Commit 的流程是,对应 2PC 的第二阶段:
1) commit primary: 写入 meta 添加一个新版本,时间戳为 commitTs,内容为 startTs, 表明数据的最新版本是 startTs 对应的数据
2) 删除 Lock 标记
值得注意的是,如果 primary row 提交失败的话,全事务回滚,回滚逻辑同 prewrite 失败的回滚逻辑。
如果 commit primary 成功,则可以异步的 commit secondaries,流程和 commit primary 一致, 失败了也无所谓。Primary row 提交的成功与否标志着整个事务是否提交成功。
事务中的读操作:
a) 检查该行是否有 Lock 标记,如果有,表示目前有其他事务正占用此行,如果这个锁已经超时则尝试清除,否则等待超时或者其他事务主动解锁。注意此时不能直接返回老版本的数据,否则会发生幻读的问题。
b) 读取至 startTs 时该行最新的数据,方法是:读取 meta ,找出时间戳为 [0, startTs], 获取最大的时间戳 t,然后读取为于 t 版本的数据内容。
由于锁是分两级的,Primary 和 Seconary row,只要 Primary row 的锁去掉,就表示该事务已经成功提交,这样的好处是 Secondary 的 commit 是可以异步进行的,只是在异步提交进行的过程中,如果此时有读请求,可能会需要做一下锁的清理工作。因为即使 Secondary row 提交失败,也可以通过 Secondary row 中的锁,找到 Primary row,根据检查 Primary row 的 meta,确定这个事务到底是被客户端回滚还是已经成功提交。
事务冲突的情况
TiKV在存储节点本地添加了一个简单的scheduler层,在2pc的读写遇到锁的时候并不是粗暴的直接回滚返回,而是尝试在本地排队等待一下,如果超时或者其他异常,再返回客户端重试,减少了网络的开销。