暑期 tensorflow+word2vec 笔记
暑期 tensorflow+word2vec 笔记
一、需要提前装的库
#``` bs4 将爬下来的数据去掉无关的特殊字符```
#``` nltk NLP中重要的处理库```
#``` gensim 构建模型的需要```
from bs4 import BeautifulSoup
#``` sklearn 机器学习库 特征提取 算法集成 模型评估标准```
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
from sklearn.linear_model import LogisticRegression
import nltk
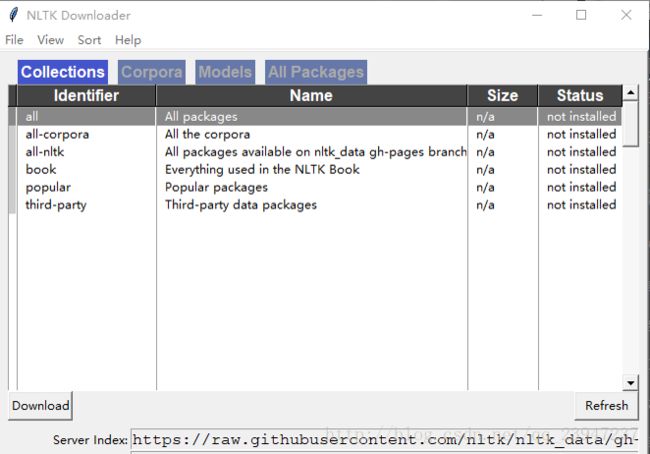
from nltk.corpus import stopwords(1) 第一次使用 nltk 时,需要注意在第一次装好 nltk 库后,执行一下
nltk.download()
执行完后弹出对话框如下图,选择即将用到的包进行download。
(2) 这个库的模块,数据集,语料库,操作在使用时需要进行安装。
(3) 分词任务采用 jieba 分词器。
二、影评情感分析准备工作
1. pandas工具读入训练集
df = pd.read_csv('labeledTrainData.tsv', sep='\t', escapechar='\\')
print('Number of reviews: {}'.format(len(df)))
df.head()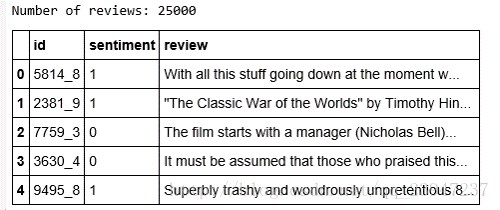
len = 25000条影评数据;在pandas中数据的组织形式是DataFrame(类似于矩阵的行列形式);
id是样本标号;sentiment是情感(好坏)标签;review是评论描述的字符。
2. 训练数据预处理
- 处理数据转化为向量让计算机能够理解。
- 去掉html标签 (
等)- 移除标点
- 切分成词/token (英文数据不用分词步骤,中文需要 jieba)
- 去掉停用词 (比如‘this’、’we’、’and’、’of’等等无信息)
- 重组为新的句子
- 处理数据的代码模板,以后可方便套用:
# ```去掉HTML标签的数据```
example=BeautifulSoup(df['review'[1000],'html.parser').get_text()# 去掉标点符号 `re`正则表达式
example_letters = re.sub(r'[^a-zA-Z]', ' ', example)# 转化为小写字母,并分离成单个单个词
words = example_letters.lower().split()附:正则表达式
正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。
参考网址:http://www.cnblogs.com/chuxiuhong/p/5885073.html
举例如下说明概念:
import re
key = r"hello world"
#这段是将要匹配的原文本
p1 = r"(?<=).+?(?=)"
#这是写好的正则表达式规则
pattern1 = re.compile(p1)#编译这段正则表达式
matcher1 = re.search(pattern1,key)#在源文本中搜索符合正则表达式的部分
print (key)#打印源文本
print (matcher1.group(0))#打印正则化后的文本3. 英文停用词表
在停用词中的词会被去掉。
#去停用词
stopwords = {}.fromkeys([ line.rstrip() for line in open('../stopwords.txt')])
words_nostop = [w for w in words if w not in stopwords]- 整合以上处理数据的功能,重写 清洗数据的函数:
eng_stopwords = set(stopwords)
def clean_text(text):
text = BeautifulSoup(text, 'html.parser').get_text()
text = re.sub(r'[^a-zA-Z]', ' ', text)
words = text.lower().split()
words = [w for w in words if w not in eng_stopwords]
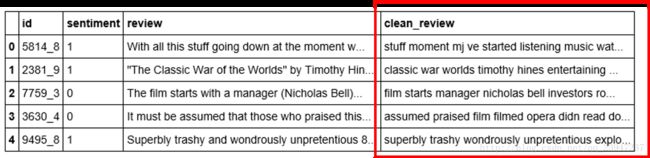
return ' '.join(words)```将清洗后的数据存放到dataframe```
df['clean_review'] = df.review.apply(clean_text)- 执行后的结果就是多了一列文本字符数据,是清洗后的:
4. bag of words模型
建模使用,将清洗后的数据转化为特征数据。
何为词袋模型(bag of words模型)?
一个文本(或文档)可以看做是一个袋子里的单词,不考虑其词序、语法关系,每个词都是独立的。
将文本中所有单词不重复地编号放进袋子里,组成一个对应编号序列,然后用序列里对应位置的词出现的次数来表示一句话。
- 例如以下有两句话构成的文本:
- John likes to watch movies. Mary likes too.
- John also likes to watch football games.
制定vector表示规则———两句话中的单词构成一个序列编号:
{
“John”: 1,
“likes”: 2,
“to”: 3,
“watch”: 4,
“movies”: 5,
“also”: 6,
“football”: 7,
“games”: 8,
“Mary”: 9,
“too”: 10
}
- 两句话共出现10个不重复的单词,依次编号(不按照原句词序)。
上面的编号规则制定好了,那么文本中第一句话:“ John likes to watch movies. Mary likes too. ”如何表示:
首先因为编号序列规则给定,故每句话都用10个数字组成的vector表示(词袋模型只有10个不同编号)
第一句话来统计单词出现的频次,如:
(编号的对应规则请看上述———制定vector表示规则)
编号 1 词为 John 出现过1次,故vector[1] = 1;
编号 2 词为 likes 出现过2次,故vector[2] = 2;
……
编号 6 词为 also 出现过0次,故vector[6] = 0;
……
综上可得第一句话表示为:[1, 2, 1, 1, 1, 0, 0, 0, 1, 1] ;
同理,第二句话表示为:[1, 1, 1, 1, 0, 1, 1, 1, 0, 0]。
参考网址:http://blog.csdn.net/deropty/article/details/50263147
三、 影评情感分析模型
1. sklearn 构建词袋模型
提取词袋的特征
用 sklearn 的 CountVectorizer
CountVectorizer是基于词频大小来筛选。
- 将清洗后的数据转化为词袋特征向量。代码如下:
# 指定前5000个次数最多的词 进行向量建模
# 类对象实例化
vectorizer = CountVectorizer(max_features = 5000)
# clean_review这一列数据的文本转化为向量
train_data_features = vectorizer.fit_transform(df.clean_review).toarray()
train_data_features.shape
# shape ==>
# (25000, 5000)
# 25000个样本 每个样本对应的是5000维的一个向量2. 数据集切分、训练
- 数据集切分
from sklearn.cross_validation import train_test_split
# 验证集划分到20% random_state = 0代表切分数据集固定不变
X_train, X_test, y_train, y_test = train_test_split(train_data_features,df.sentiment,test_size = 0.2, random_state = 0)- 训练分类器(逻辑回归,sigmoid),能用简单的LR模型不用其他复杂模型。
# 实例化 LR 传入数据和label
LR_model = LogisticRegression()
LR_model = LR_model.fit(X_train, y_train)
# 测试数据上的预测值
y_pred = LR_model.predict(X_test)
cnf_matrix = confusion_matrix(y_test,y_pred)
# 召回率
print("Recall metric in the testing dataset: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# 精度
print("accuracy metric in the testing dataset: ", (cnf_matrix[1,1]+cnf_matrix[0,0])/(cnf_matrix[0,0]+cnf_matrix[1,1]+cnf_matrix[1,0]+cnf_matrix[0,1]))
附:预测精度 vs 预测召回率
- 精度 acc:条件 y_real;y_predict 下:假设验证预测了总共 sum 次,其中 y_predict 恰好等于 y_real 的个数(即预测正确的个数)为 right 次。
acc=right/sum
召回率 recall:假设医院给了一批数据:1000个人,其中990人为健康;10人为生病。
预测结果是1000个人全是健康状态,则此时acc = 990 / 1000 = 0.99;这个结果对于我们查找病人毫无作用,因为10个病人都没有预测到。
因此需要查全,召回率指的是查全。令10个病人的样本为正样本数=(TP+FN),10人的正样本预测为正样本即预测正确的个数为 TP 个,正样本中剩下的预测错误的即 FN 个。此时recall = 0 /10 = 0。
recall=TP/(TP+FN)
附:一个有用的模板———混淆矩阵
- 绘制混淆矩阵图表的定义函数
import matplotlib.pyplot as plt
import itertools
def plot_confusion_matrix(cm, classes,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=0)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')- 执行绘制混淆矩阵图表的函数
# 该模板只需要改y_test,y_pred为传入自己定义的数据
cnf_matrix = confusion_matrix(y_test,y_pred)
# Plot non-normalized confusion matrix
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
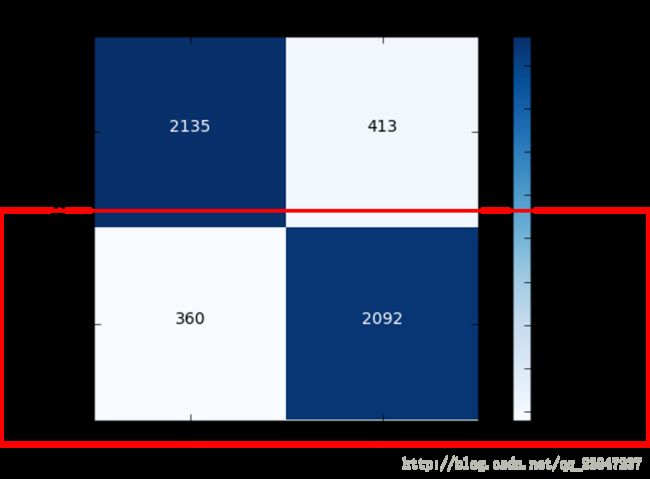
plt.show()- 精确度:两块蓝色的数量 / 四块总的数量
- 召回率:只关注 true label = 1 的两块数量
- Recall : 0.853181076672 = 2092 /(2092+360)
- accuracy : 0.8454 = (2135+2092)/(2135+2092+413+360)
3. 建立新的特征——word2vec
此时传入的文本数据为未标记情感的文本。先经历过【二】中的清理数据步骤得到新的数据。
英文分词器
import warnings
warnings.filterwarnings("ignore")
# import nltk
# nltk.download()
# 安装窗口中选择'Models'项,然后找punkt,点击下载安装该数据包
tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
# 分词+清洗函数
def split_sentences(review):
raw_sentences = tokenizer.tokenize(review.strip())
sentences = [clean_text(s) for s in raw_sentences if s]
return sentences
sentences = sum(review_part.apply(split_sentences), [])
print('{} reviews -> {} sentences'.format(len(review_part), len(sentences)))数据的 string 的格式转为 list:
sentences_list = []
for line in sentences:
sentences_list.append(nltk.word_tokenize(line))4. word2vec 的相关参数
- sentences:可以是一个 list
- sg: 用于设置训练算法,默认为0,对应CBOW算法;sg=1则采用skip-gram算法。
- size:是指特征向量的维度,默认为100。大的size需要更多的训练数据,但是效果会更好. 推荐值为几十到几百。
- window:表示当前词与预测词在一个句子中的最大距离是多少
- alpha: 是学习速率
- seed:用于随机数发生器。与初始化词向量有关
- min_count: 可以对字典做截断。词频少于min_count次数的单词会被丢弃掉,默认值为5
- max_vocab_size: 设置词向量构建期间的RAM限制。如果所有独立单词个数超过这个,则就消除掉其中最不频繁的一个。每一千万个单词需要大约1GB的RAM。设置成None则没有限制。
- workers:workers参数控制训练的并行数。
- hs: 如果为1则会采用hierarchica softmax技巧。如果设置为0(defaut),则negative sampling会被使用。
- negative:如果>0,则会采用negative samping,用于设置多少个noise words
- iter: 迭代次数,默认为5
- 1、设定训练参数
# ```设定词向量训练的参数```
num_features = 300 # Word vector dimensionality
min_word_count = 40 # Minimum word count
num_workers = 4 # Number of threads to run in parallel
context = 10 # Context window size
model_name = '{}features_{}minwords_{}context.model'.format(num_features, min_word_count, context)- 2、训练模板(gensim的word2vec)
- 下载gensim模块:
—— 如果在pip install gensim后出现“系统无法将文件移到不同的磁盘驱动器”问题时;
—— 切记一定要关掉 pycharm 以及 jupyter notebook。
from gensim.models.word2vec import Word2Vec
# ```实例化model```
model = Word2Vec(sentences_list, workers=num_workers, \
size=num_features, min_count = min_word_count, \
window = context)
# If you don't plan to train the model any further, calling
# init_sims will make the model much more memory-efficient.
model.init_sims(replace=True)
# It can be helpful to create a meaningful model name and
# save model for use. u can load it using Word2Vec.load()
model.save(os.path.join('..', 'models', model_name))
#存到上级目录的models文件夹下
- 上述建模过程稍微长一点,大概要经历几分钟。
5. 模型转化向量
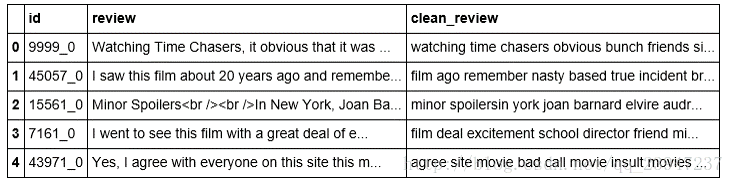
- 传入csv文本数据;
- 清洗数据;
- 如下图转为向量(具体步骤:文本中每个词去检查是否在训练好的model字典里,如果是,转化为字典里对应的向量数值,并对应维度相叠加,再求均值);
def to_review_vector(review):
global word_vec
review = clean_text(review, remove_stopwords=True)
#print (review)
#words = nltk.word_tokenize(review)
word_vec = np.zeros((1,300))
for word in review:
#word_vec = np.zeros((1,300))
if word in model:
word_vec += np.array([model[word]])
#print (word_vec.mean(axis = 0))
return pd.Series(word_vec.mean(axis = 0))
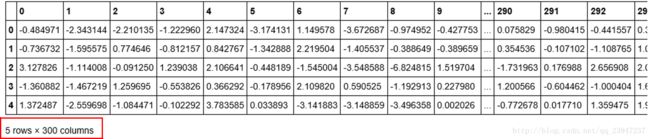
train_data_features = df.review.apply(to_review_vector)
train_data_features.head()- 数据样本(5个标签的字符组)

- 生成的向量(5个标签的字符组,每组转化为300维向量)
6. 利用向量测模型
之前基于词袋模型(词频)得出向量进行逻辑回归模型;
现在基于word2vec模型的出新的向量进行建模评估。
词袋模型测试效果如下:
* Recall metric in the testing dataset: 0.853181076672
* accuracy metric in the testing dataset: 0.8454word2vec模型测试效果如下:
** Recall metric in the testing dataset: 0.87969004894
** accuracy metric in the testing dataset: 0.8658
附:机器学习透彻的理解
机器学习(ML),说白了就是让计算机去找到一个抽象的函数 f(x) 来很好的拟合手上收集好的数据。
怎么去找:计算机首先要在 y=f(x) 里面先找到对应的变量 y 、 x ;假设 y 是标签, x 是数据。计算机的任务就是拟合 y 、 x 的函数。
建模有什么用:经常听说机器学习要训练模型,为什么要训练模型?
假设我们的标签(即数字)有了,对应的数据是一组中文字符,计算机去拟合的话就会发现不能解决中文字符和数字标签之间的关系,因为计算机只能处理数字和数字之间的关系。- 因此,建模的任务就是寻找很好的数字能够准确表示中文字符,则训练模型的目的,说白了也就是不同的训练材料通过模型转化为与之对应的更好表示该材料的数值,这样才方便与训练标签产生函数关联。
- 机器学习要解决的问题是:

- 机器学习的工作步骤:(训练模型提取特征表示)

感悟
就在今天上午处理完上面的代码,突然产生了思考和疑问,机器学习建模干啥啊,提取来的特征用到哪了?代码里的目的也没看见啊!
然后翻到前面的笔记,恍然大悟!学到现在,才明白了机器学习在干什么。大有金庸的《侠客行》里 大悲老人 在临死前听到 狗杂种 说“是伤就得包,不包还是伤”后的感叹此意,嗟乎嗟乎,不枉我暑假学习一场!