Hadoop学习笔记 (一)
一、 初识Hadoop 2.X
1. Hadoop发展和三大组件功能
GFS ---> HDFS
MapReduce ---> MapReduce
BigTable ---> HBase
四大组成部分:
工具,基础,为其他框架服务
*MapReduce
对海量数据的处理
分布式
分而治之
大数据集分为小的数据集
每个数据集,进行逻辑业务处理(map)
合并统计数据结果(reduce)
input –> map –> shuffle –> reduce –> output
*HDFS
存储海量数据
分布式
安全性
副本数据
数据时以block的方式进行存储的
128M
比如:
200 MB
blk_00001:128 MB
blk_00002:72 MB
*YARN
分布式资源管理框架
管理整个集群的资源(内存、CPU核数)
分配调度集群的资源
2. 分布式文件系统HDFS和分布式资源管理系统YARN
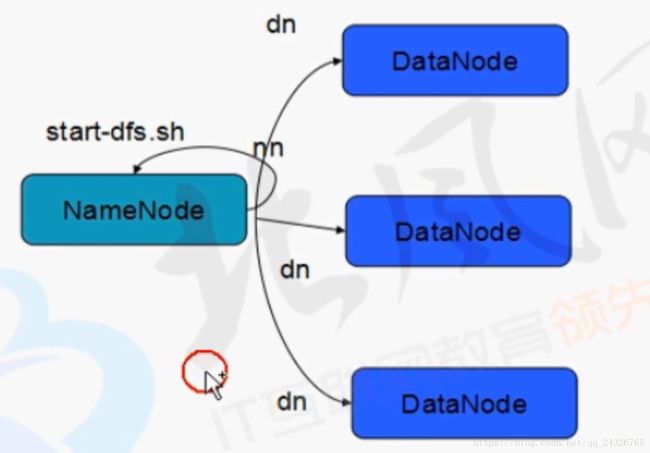
NameNode
*存储文件系统的元数据,命名空间namespace*内存
*本地磁盘
*fsimage:镜像文件
*edites:编辑日志
DataNode
*存储数据
*辅助NameNode工作,合并fsimage和edites文件(定时周期性)

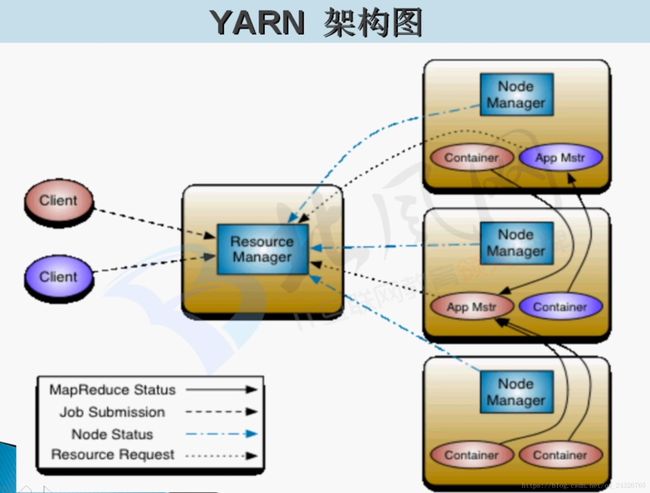

client提交任务给ResouceManager,ResouceManager会为每个应用生成一个应用的管理者:ApplicationMaster,应用的管理者到ResouceManager进行任务的划分、资源的申请,ResouceManager会分配多个NodeManager分配给ApplicationMaster,然后ApplicationMaster将任务发个多个NodeManager,NodeManager会为任务分配container,container包含了节点上的部分资源,进行任务隔离,只准用这么多资源。
3. 并行计算框架MapReduce思想及如何运行在YARN上

1:Client将任务提交给ResourceManager。
2:ResourceManager找到一个NodeManager节点,为应用创建应用的管理者MR App Mstr。
3:MR App Mstr向ResourceManager的ApplicationsManager进行注册。
4:MR App Mstr向ResourceManager的ResourceScheduler申请资源。
5:MR App Mstr找申请到的资源(多个NodeManager)并启动任务(Map任务或Reduce任务)。
6:①NodeManager在Container中启动任务。
②client可通过页面进行监控运行的任务。
7:MR App Mstr监控每个任务:每个任务都要给MR App Mstr进行反馈。
8:当程序运行结束,MR App Mstr要告诉ResourceManager的ApplicationsManager进行销毁。
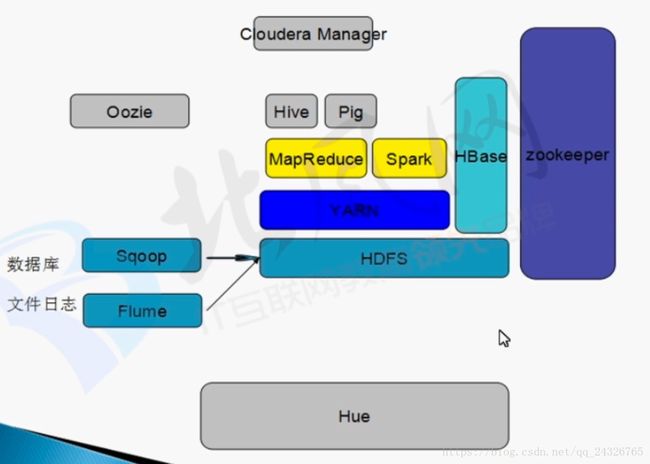
4. hadoop生态圈
5. Hadoop 2.x环境搭建准备
软件下载:
http://archive.apache.org
6. MapReduce在本地模式下运行(未配置hdfs)
查看官网文档:
http://hadoop.apache.org/docs/r2.7.5/hadoop-project-dist/hadoop-common/SingleCluster.html
执行命令:
hadoop jar 打的jar包 输入路径 输出路径
使用hadoop自带的例子进行测试:
准备工作:在hadoop-env.sh添加jdk路径

例1:grep
将etc/hadoop下的所有xml文件拷贝到input文件夹中
对dfs开头的单词进行计数。
注意:(1) 输出目录不能存在;(2) 如果在/etc/profile中配置了hadoop的环境变量可直接使用hadoop命令而不用进入hadoop的bin目录下再执行。
例2:wordcount

7. 本地模式运行MapReduce案例(使用HDFS上数据)
查看官方文档:
http://hadoop.apache.org/docs/r2.7.5/hadoop-project-dist/hadoop-common/SingleCluster.html
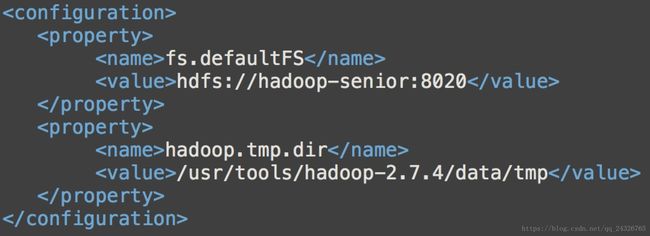
① 修改core-site.xml
添加hdfs路径和端口:
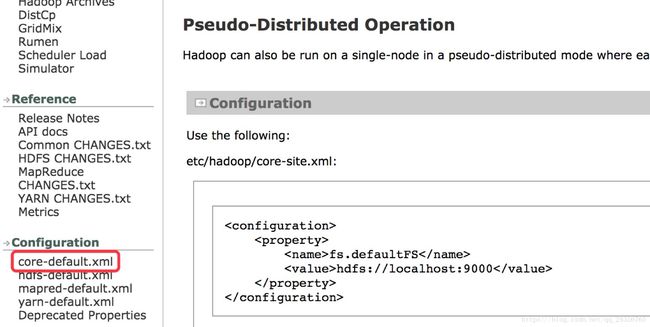
添加hdfs数据存放目录:
配置完成后如下:
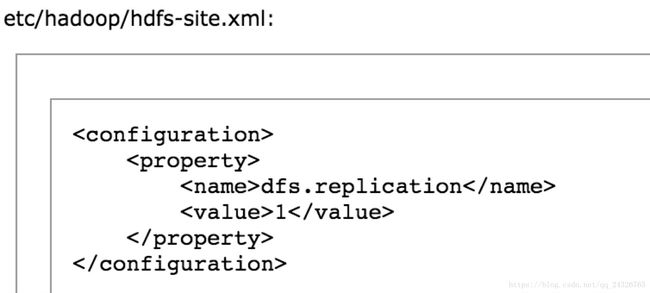
② 修改hdfs-site.xml
设置hdfs副本数(因为目前是伪分布式,所以1就可以)
③ 格式化namenode

④ 启动namenode和datanode的守护进程

⑤ 在hdfs上创建文件夹,并把本地文件上传到hdfs上

(-mkdir -p递归创建文件夹;-ls -R递归查看)
⑥ 执行mapreduce任务
![]()
使用bin/yarn也可以执行。因为配置了hdfs,所以默认是从hdfs读取文件。
8. 在YARN上运行MapReduce程序
查看官方文档:
http://hadoop.apache.org/docs/r2.7.5/hadoop-project-dist/hadoop-common/SingleCluster.html
① 配置yarn-env.sh(可改可不改)

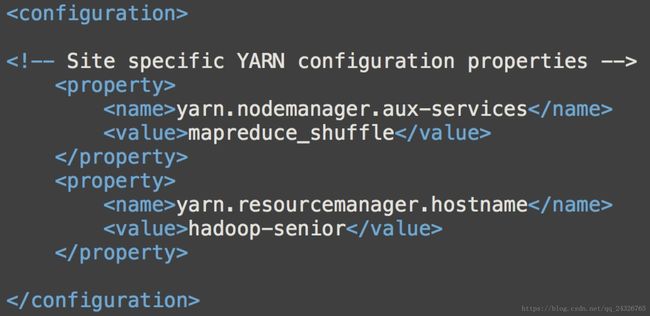
② 修改yarn-site.xml
添加yarn的shuffle设置:

添加资源管理节点的主机名:
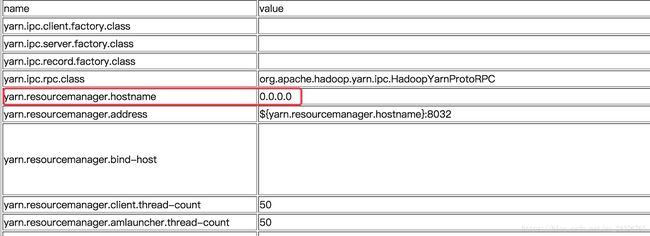
修改完成后如图:
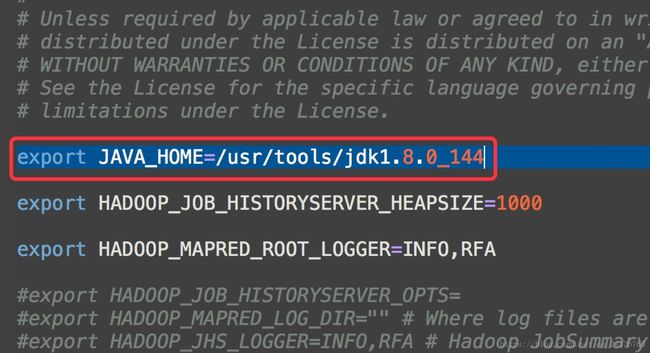
③ 修改mapred-env.sh,配置jdk路径(可改可不改)
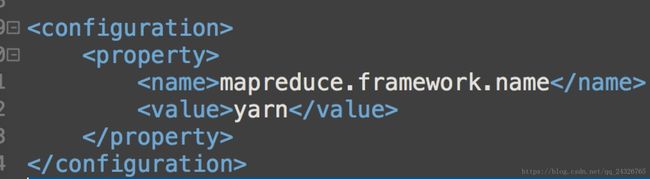
④ 复制mapred-site.xml.template命名为mapred-site.xml,并修改mapred-site.xml
![]()
设置mapreduce的执行框架为yarn:
⑤ 修改slaver,添加主机名
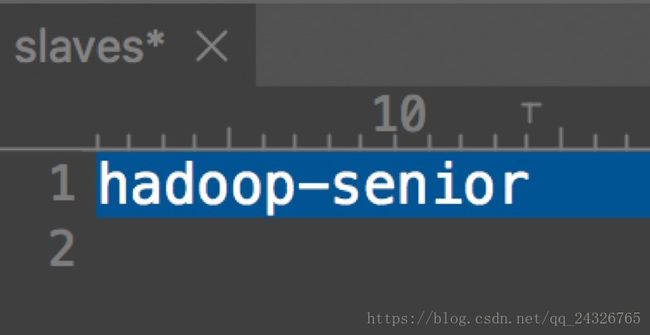
因为是单节点,所以只写一个。
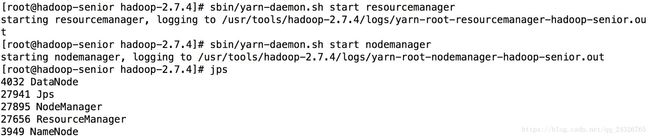
⑥ 启动yarn(resourcemanager、nodemanager)
⑦ 执行mapreduce任务
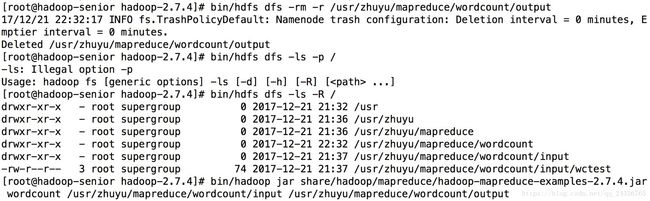
(修正:使用bin/yarn jar......)
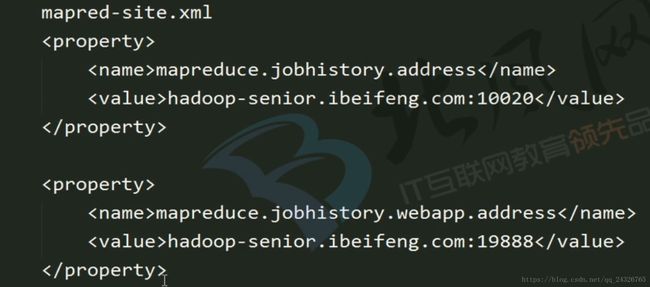
9. MapReduce历史服务配置启动查看
查看yarn的运行情况:
http://hadoop-senior:8088
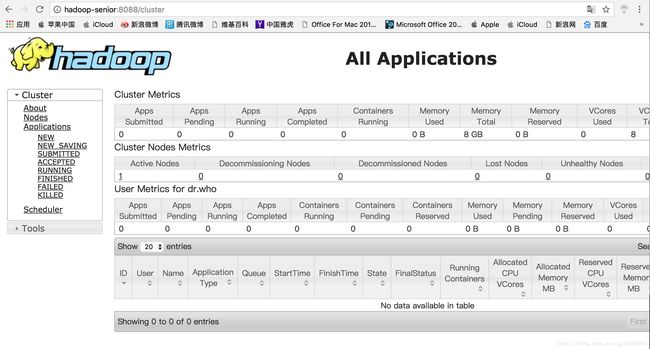
查看应用的history,需要开启JobHistoryServer:


10. YARN的日志聚集功能配置使用
Log Aggregation
聚集应用完成以后,将日志信息上传到hdfs系统上
① 在yarn-site.xml中添加配置

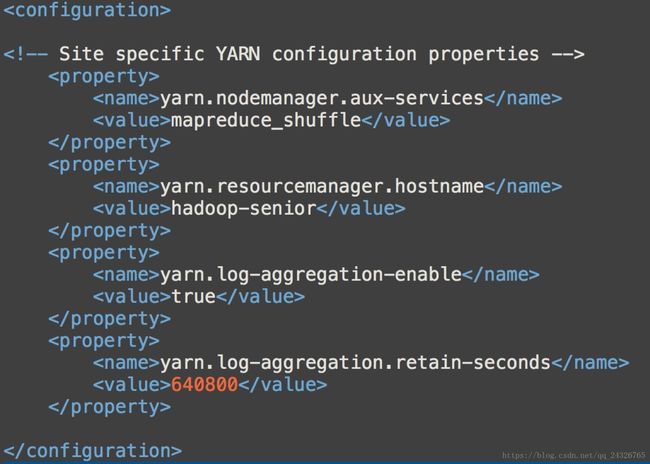
② 重启yarn(resourcemanager、nodemanager和jobhistory)

注意:在hdfs上创建目录时,必须一层一层创建,否则会报无法抓取的异常,导致无法查看日志信息。
11. hadoop配置文件讲解以及配置HDFS垃圾回收
* 默认配置文件:$HADOOP_HOME/share/hadoop/
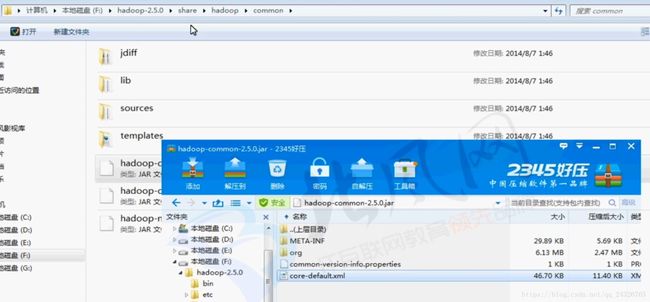
* hdfs- default.xml
* yarn- default.xml
* mapred- default.xml
* 自定义配置文件:$HADOOP_HOME/etc/hadoop/
* core-site.xml
* hdfs-site.xml
* yarn-site.xml
* mapred-site.xml
设置垃圾清理时间间隔:
在core-site.xml中添加配置
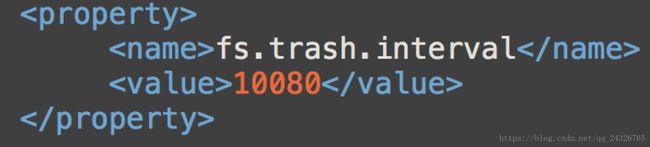
HDFS会为每一个用户创建一个回收站目录:/user/用户名/.Trash/
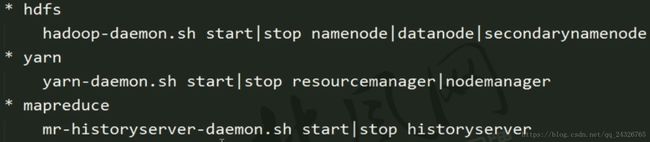
12. 服务启动方式
各个组件逐一启动 (推荐,一般使用脚本) :
各个模块分开启动(也可以):
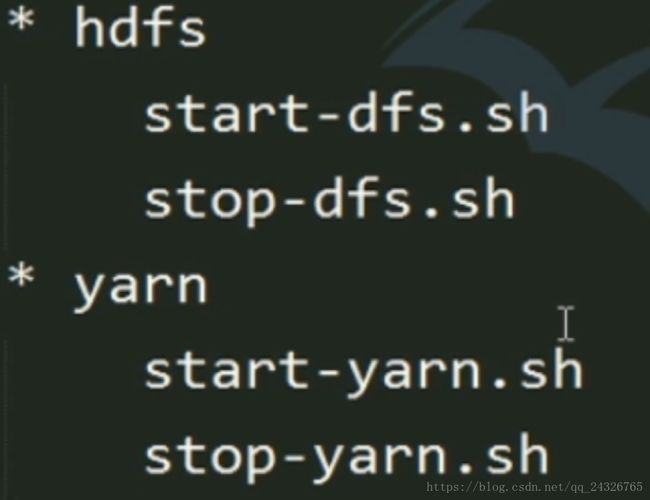
start-all.sh
(这种方式要求namenode和resourcemanager都在主节点上,而在实际的工作环境中,namenode和resourcemanager是分布式的,不在一个节点上,因为如果在一个节点上,万一挂了,整个集群都不能用了)
13. 配置SSH无密码登录
当你使用start-all.sh开启服务时,也会去开启子节点上的服务,这就需要一个一个输入密码,比较麻烦。
原理:

步骤:

[root@hadoop-senior ~]# ssh-keygen -t rsa
[root@hadoop-senior ~]# cd .ssh/
[root@hadoop-senior .ssh]# ls
id_rsa id_rsa.pub known_hosts
[root@hadoop-senior .ssh]# ssh-copy-id hadoop-senior
(自动将公钥拷入到authorized_keys中)
[root@hadoop-senior .ssh]# ls
authorized_keys id_rsa id_rsa.pub known_hosts
14. 各个服务的分布位置及如何配置
伪分布式:
所有进程都在一台机器上
在hdfs-site.xml中添加配置
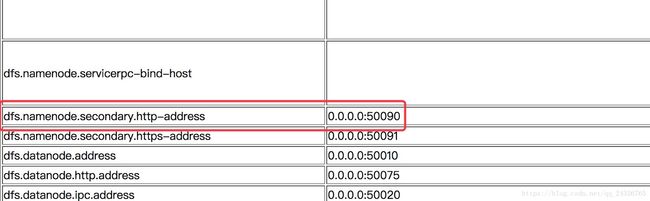
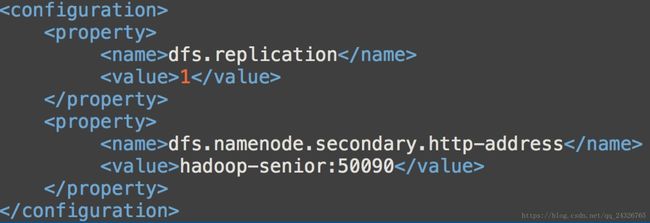
HDFS的三个守护进程都运行在哪台主机上:
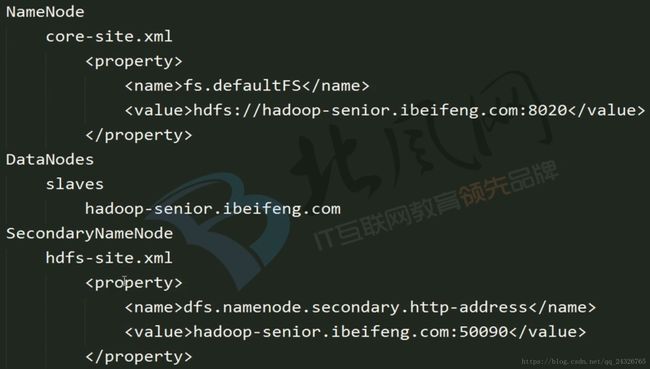
启动HDFS时就能看出来(前提是要配置SSH无密钥登录):

(三个服务启动和关闭的顺序一致)
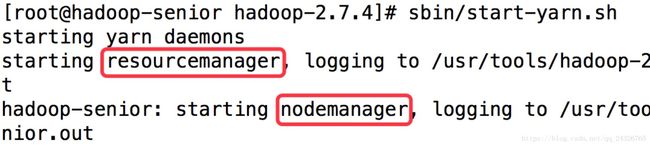
YARN的两个守护进程都运行在哪台主机上:

启动YARN时就能看出来(前提是要配置SSH无密钥登录):
MapReduce HistoryServer(jobhistory)运行在哪台主机上: