数据转换工具Sqoop学习笔记

(导入导出是相对于HDFS)
1. 大数据Hadoop2.x协作.框架的功能




2. Sqoop 使用要点(核心)及企业版本讲解

所以我们就使用CDH的发行版本,而不使用apache的。

下载地址:http://archive.cloudera.com/cdh5/cdh/5/
所有框架的cdh版本要相同。
3. 使用CDH 5.13.0版本快速搭建Hadoop 2.x和Hive伪分布式环境(和apache相同)
① 配置hadoop-env.sh、yarn-env.sh、mapred-env.sh的JAVA_HOME
② 配置core-site.xml
fs.defaultFS
hdfs://hadoop-senior:8020
hadoop.tmp.dir
/opt/cdh5.13.0/hadoop-2.6.0-cdh5.13.0/data/tmp
③ 配置hdfs-site.xml
dfs.namenode.secondary.http-address
hadoop-senior:50090
dfs.namenode.http-address
hadoop-senior:50070
dfs.replication
1
dfs.permissions
false
④ slavers
hadoop-senior
hadoop-senior02
hadoop-senior03⑤ 格式化namenode
bin/hdfs namenode –format
⑥ 配置yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop-senior
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
640800
yarn.log.server.url
hadoop-senior:19888/jobhistory/logs
yarn.nodemanager.resource.memory-mb
4096
yarn.nodemanager.resource.cpu-vcores
4
⑦ 配置mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
hadoop-senior:10020
mapreduce.jobhistory.webapp.address
hadoop-senior:19888
⑧ 重启并删掉/tmp下的数据
rm -rf /tmp/*
⑨ 配置hive-env.sh
修改=HADOOP_HOME和HIVE_CONF_DIR
⑩ 配置hive-log4j.properties
修改hive日志的存放目录hive.log.dir
⑪ 配置hive-site.xml
javax.jdo.option.ConnectionURL
jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
123456
hive.cli.print.header
true
hive.cli.print.current.db
true
⑫ 将mysql驱动放在hive的lib目录下
⑬ 创建hive在hdfs上的存储目录
bin/hadoop dfs -mkdir /tmp
bin/hadoop dfs -mkdir -p/user/hive/warehouse
bin/hadoop dfs -chmod g+w /tmp
bin/hadoop dfs -chmod g+w/user/hive/warehouse⑭ 测试
创建表、导入数据……
4. Sqoop安装及基本使用讲解
安装:

使用:

cdh文档如何查看:

以mysql为例:


① 将mysql驱动拷贝到sqoop安装目录的lib目录下
cp /opt/cdh5.13.0/hive-1.1.0-cdh5.13.0/lib/mysql-connector-java-5.1.6.jar /opt/cdh5.13.0/sqoop-1.4.6-cdh5.13.0/lib/
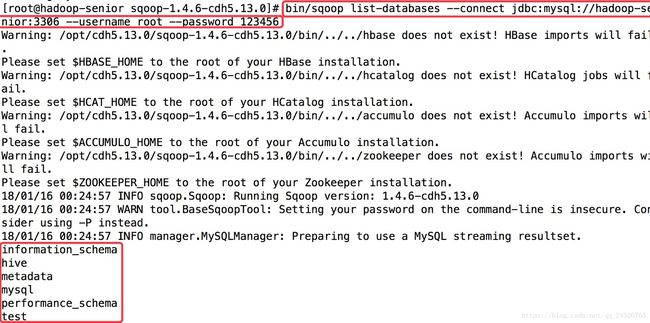
② 查看mysql下所有数据库
bin/sqoop list-databases \
--connect jdbc:mysql://hadoop-senior:3306\
--username root \
--password 123456 \
结果:
如果报以下异常

将mysql的user表中多余的root信息删除。
5. 使用Sqoop导入数据到HDFS及本质分析




mysql数据导入到hdfs:
① 准备数据
create table `my_user`(
`id` tinyint(4) not null auto_increment,
`acount` varchar(255) default null,
`password` varchar(255) default null,
primary key(`id`)
);
insert into `my_user` values('1','admin','admin');
insert into `my_user` values('2','pu','pu');
insert into `my_user` values('3','system','system');
insert into `my_user` values('4','zxh','zxh');
insert into `my_user` values('5','test','test');
insert into `my_user` values('6','pudong','pudong');bin/sqoop import \
--connect jdbc:mysql://hadoop-senior:3306/test \
--username root \
--password 123456 \
--table my_user \
--target-dir /user/zhuyu/sqoop/imp_my_user 不指定hdfs目录的话,数据默认放在/user/用户名/下
--num-mappers 1 当数据量较小时,可调整map的数量,以提高速度(不需要reduce时), 如下图没改map数量之前:
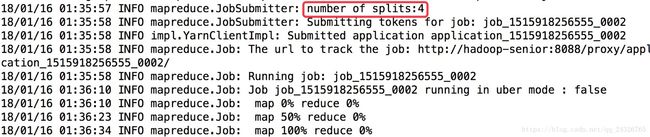
数据量那么小,却用了4个map。

![]()
改之后:


sqoop的执行过程:
把语句变成java类

在命令执行目录下

然后编译打成jar包

然后运行mapreduce
异常1:

更换java驱动包。
异常2:
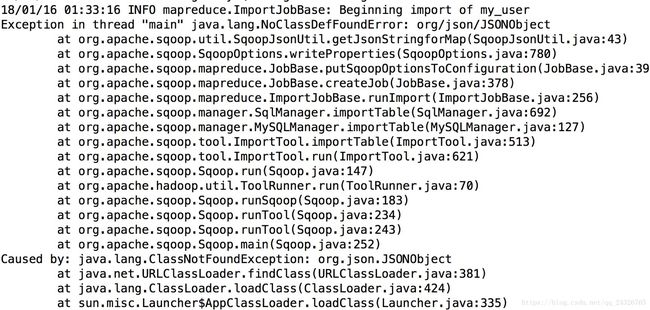
添加java-json.jar包。
sqoop指定将mysql中的某几列数据导入到hdfs:
bin/sqoop import \
--connect jdbc:mysql://hadoop-senior:3306/test \
--username root \
--password 123456 \
--table my_user \
--target-dir /user/zhuyu/sqoop/imp_my_user_colume \
--num-mappers 1 \
--columns id,account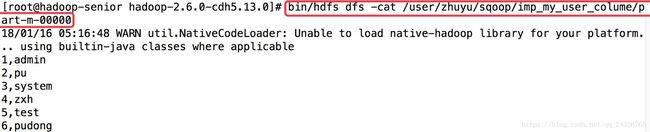
将mysql的查询结果导入到hdfs(用的最多):

bin/sqoop import \
--connect jdbc:mysql://hadoop-senior:3306/test \
--username root \
--password 123456 \
--query 'select id,account from my_user' \
--target-dir /user/zhuyu/sqoop/imp_my_user_query \
--num-mappers 1 \出现异常:
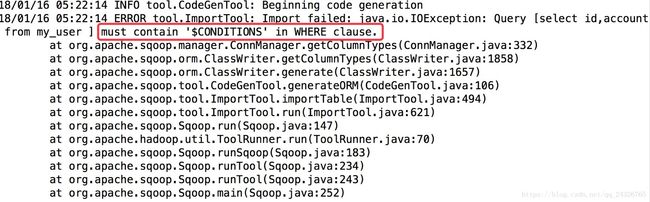
必须要在where后面加上$CONDITIONS,所以要将query后的查询改为select id,account from my_user where $CONDITIONS。
结果:
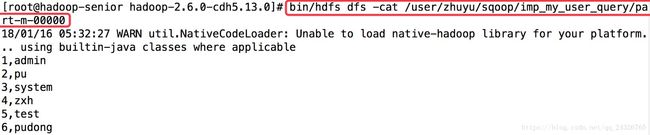
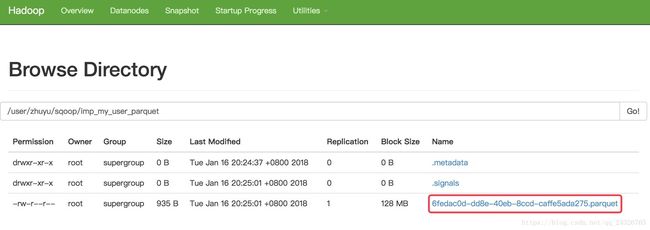
6. Sqoop导入数据设置数据存储格式parquet

bin/sqoop import \
--connect jdbc:mysql://hadoop-senior:3306/test \
--username root \
--password 123456 \
--table my_user \
--target-dir /user/zhuyu/sqoop/imp_my_user_parquet \
--num-mappers 1 \
--as-parquetfile
运行结果:

将从mysql导入到hdfs的parquet数据导入到hive表:
drop table if exists default.hive_user_parquet;
create table default.hive_user_parquet(
id int,
username string,
password string
)
row format delimited fields terminated by ','
stored as parquet;
load data inpath '/user/zhuyu/sqoop/imp_my_user_parquet/6fedac0d-dd8e-40eb-8ccd-caffe5ada275.parquet' into table default.hive_user_parquet;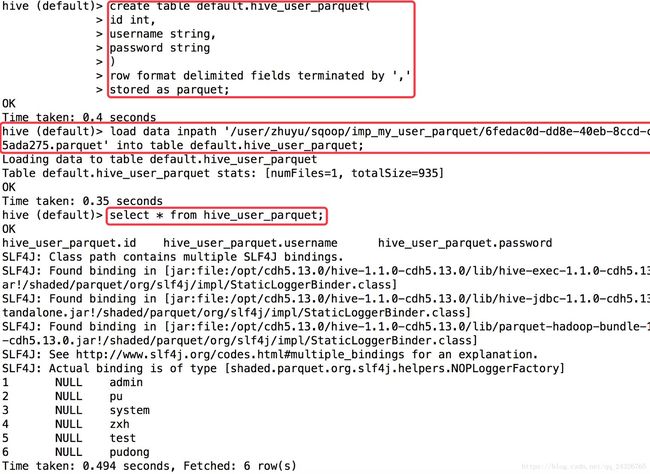
(导入的数据为什么为null?这是1.4.5的bug,1.4.6以后就修复了。)

7. 导入数据设置数据压缩为sanppy
bin/sqoop import \
--connect jdbc:mysql://hadoop-senior:3306/test \
--username root \
--password 123456 \
--table my_user \
--target-dir /user/zhuyu/sqoop/imp_my_user_snappy \
--delete-target-dir \
--num-mappers 1 \
--compress \
--compression-codecorg.apache.hadoop.io.compress.SnappyCodec \
--fields-terminated-by '\t'fields-terminated-by :设置字段之间的分割方式。
此时抛异常:
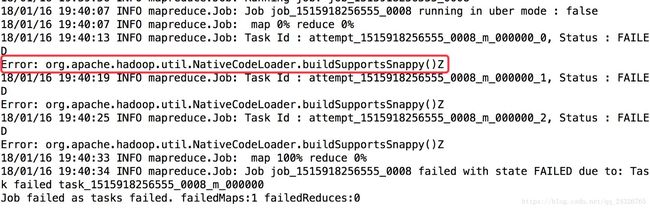
(说明本地库中没有snappy编码格式)
查看本地编码库:

所以要编译本地类库:
此过程待补充。
这时候再创建一个hive表,将数据加载到hive表中,查询不会出现null:
drop table if exists default.hive_user_snappy;
create table default.hive_user_snappy(
id int,
username string,
password string
)
row format delimited fields terminated by ','
//stored as parquet;(删掉)
load data inpath '/user/zhuyu/sqoop/imp_my_user_snappy' into table default.hive_user_snappy;
回顾流程:

8. Sqoop导入数据时两种增量方式导入

① 根据时间戳query
② sqoop提供的参数

bin/sqoop import \
--connect jdbc:mysql://hadoop-senior:3306/test \
--username root \
--password 123456 \
--table my_user \
--target-dir /user/zhuyu/sqoop/imp_my_user_increment \
--num-mappers 1 \
--incremental append \
--check-column id \
--last-value 4last-value:从上一次的值开始。
查看:


(last-value为4,所以从5开始)
第二种方式的缺点是:无法设置结束的值。如果想查5号到10号的数据,只能设置从5号开始(last-value)。
由下图引出direct的使用:

bin/sqoop import \
--connect jdbc:mysql://hadoop-senior:3306/test \
--username root \
--password 123456 \
--table my_user \
--target-dir /user/zhuyu/sqoop/imp_my_user_increment \
--num-mappers 1 \
--incremental append \
--check-column id \
--last-value 4 \
--direct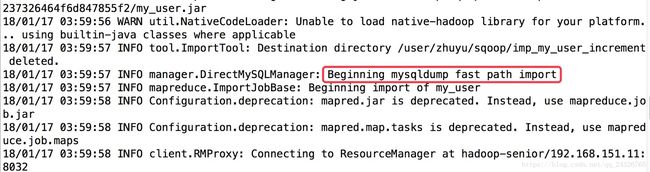
(经过mapreduce,但是速度比之前要快很多)
9. Sqoop导出数据Export使用讲解
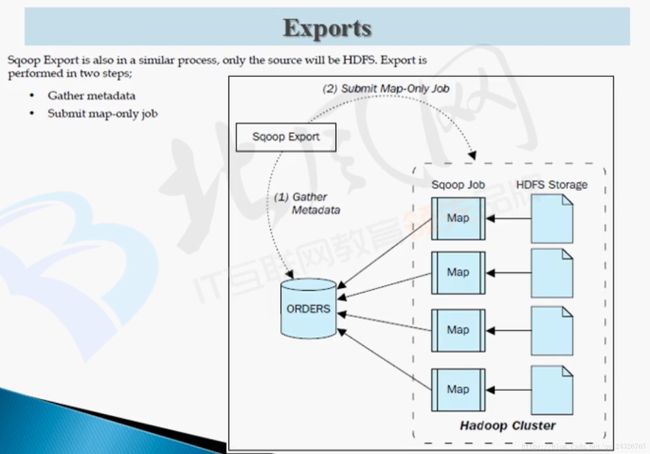
(也是只有map没有reduce)
数据的准备:
vim /opt/datas/user.txt
10,hadoop,hadoop
11,zhuyu,zhuyubin/hdfs dfs -mkdir -p /user/zhuyu/sqoop/exp
bin/hdfs dfs -mkdir -p /user/zhuyu/sqoop/exp/user
bin/hdfs dfs -put /opt/datas/user.txt /user/zhuyu/sqoop/exp/user
导出数据:
bin/sqoop export \
--connect jdbc:mysql://hadoop-senior:3306/test \
--username root \
--password 123456 \
--table my_user \
--export-dir /user/zhuyu/sqoop/exp/user \
--num-mappers 1 \

10. Sqoop如何将RDBMS表中的数据导入到Hive表中

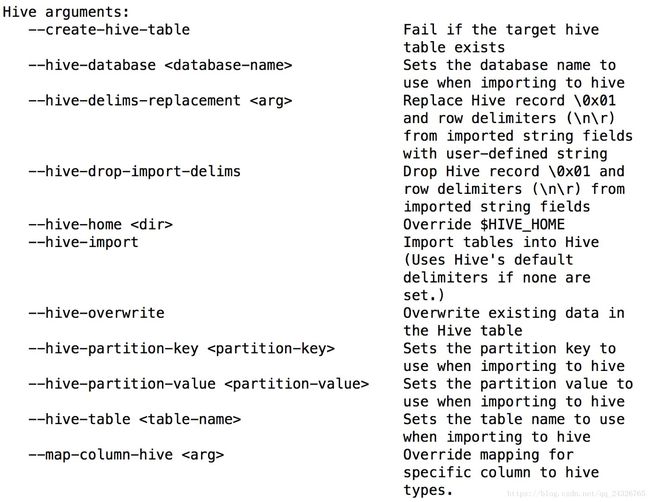
在hive中创建一个user_hive表:
drop table if exists default.user_hive;
create table default.user_hive(
`id` int,
`account` string,
`password` string
)
row format delimited fields terminated by '\t';(可使用脚本,符合企业规范)
mysql-->hive导入数据:
bin/sqoop import \
--connect jdbc:mysql://hadoop-senior:3306/test \
--username root \
--password 123456 \
--table my_user \
--fields-terminated-by '\t' \
--delete-target-dir \
--num-mappers 1 \
--hive-import \
--hive-database default \
--hive-table user_hive
执行过程:
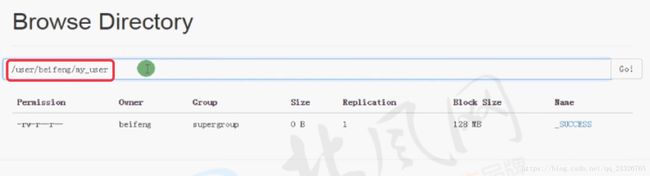
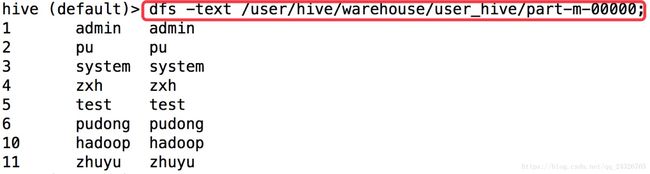
mapreduce将mysql中的数据先加载到hdfs上,即默认的/user/zhuyu/my_user下,然后--hive-import使得数据load到default.user_hive表中,即移动到
/user/hive/warehouse/user_hive下,如下图:


异常:
mapreduce运行成功,加载数据到hive表时出现异常:
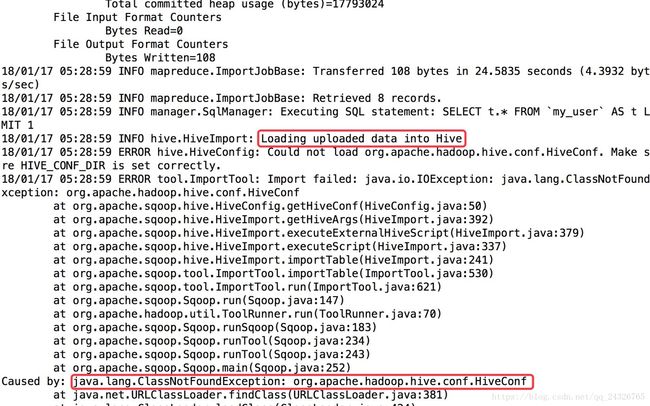
解决:在etc/profile中添加
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HIVE_HOME/lib/*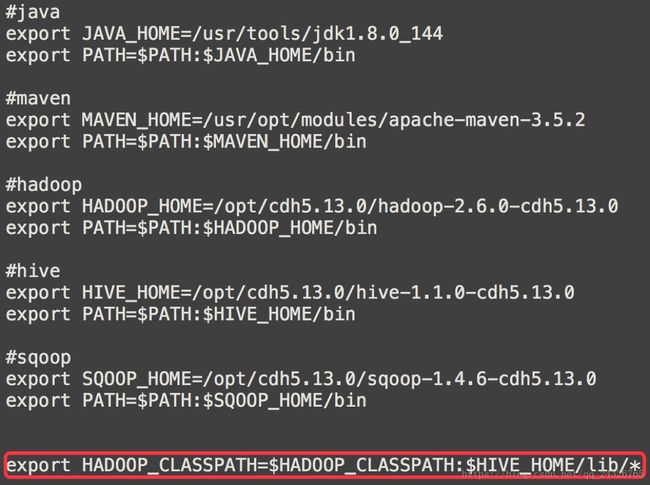
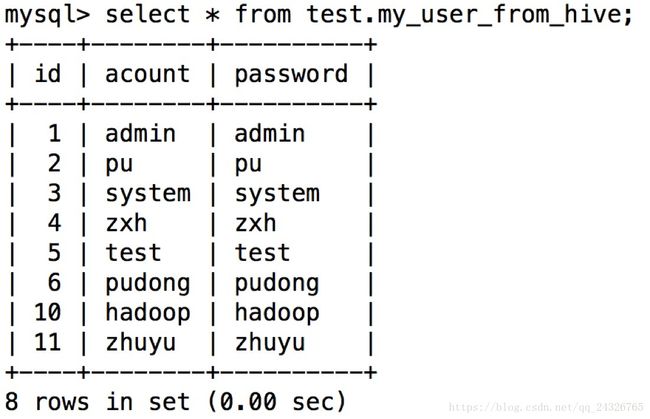
11. Sqoop如何导出Hive表中数据到RDBMS中
创建一个mysql表用来存储hive的数据:
create table `my_user_from_hive`(
`id` tinyint(4) not null auto_increment,
`acount` varchar(255) default null,
`password` varchar(255) default null,
primary key(`id`)
);
导出Hive表中数据到mysql:
bin/sqoop export \
--connect jdbc:mysql://hadoop-senior:3306/test \
--username root \
--password 123456 \
--table my_user_from_hive \
--export-dir /user/hive/warehouse/user_hive \
--num-mappers 1 \
--input-fields-terminated-by '\t'
--input前缀的使用于读文件的分割符号,便于解析文件,所以用于从HDFS文件导出到某个数据库的场景。要设置该属性,否则会报以下异常:
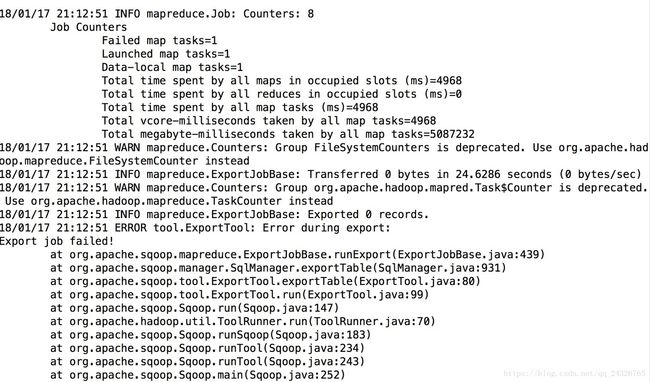
结果:
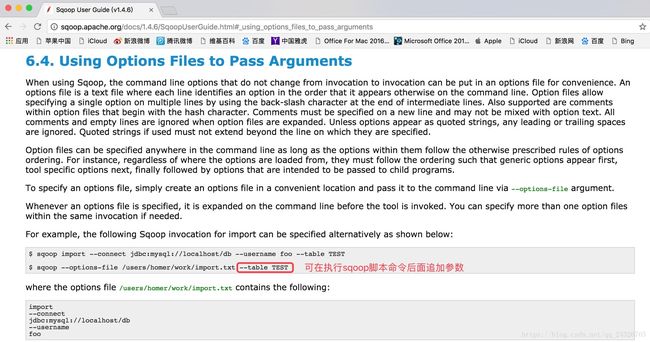
12. Sqoop使用--options-file进行运行任务讲解

① 编写sqoop脚本
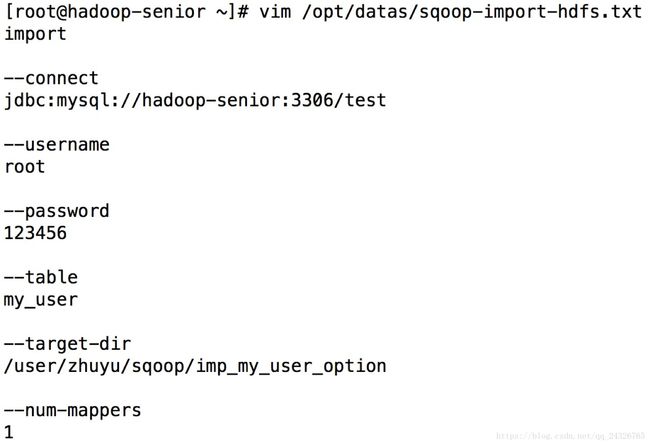
import
--connect
jdbc:mysql://hadoop-senior:3306/test
--username
root
--password
123456
--table
my_user
--target-dir
/user/zhuyu/sqoop/imp_my_user_option
--num-mappers
1
② 执行sqoop脚本


也可在执行命令后追加参数,例如:
![]()
③ 查看


企业中一般都将其写在脚本中:
