Java实现Apriori算法进行关联规则挖掘
实验描述:
对指定数据集进行关联规则挖掘,选择适当的挖掘算法,编写程序实现,提交程序和结果报告。
数据集: retail.txt ,根据数据集中的数据利用合适的挖掘算法得到频繁项集,并计算置信度,求出满足置信度的所有的关联规则
retail.txt中每个数字表示一种商品的ID,一个{}内的表示一次交易
实验环境和编程语言:
本实验使用的编程语言为:Java
编程环境为:Intellij idea
实现频繁项集的挖掘算法为Apriori算法
用于挖掘的样本个数为:1000个(retail.txt的前1000条数据)
样本示例:
{ 38,39,47,48}
表示一个顾客购买了ID为38、39、47、48的四种商品。
算法分析:
Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法Apriori使用一种称作逐层搜索的迭代方法,“K-1项集”用于搜索“K项集”。
首先,找出频繁“1项集”的集合,该集合记作L1。L1用于找频繁“2项集”的集合L2,而L2用于找L3。如此下去,直到不能找到“K项集”。找每个Lk都需要一次数据库扫描。
核心思想是:连接步和剪枝步。连接步是自连接,原则是保证前k-2项相同,并按照字典顺序连接。剪枝步,是使任一频繁项集的所有非空子集也必须是频繁的。反之,如果某个候选的非空子集不是频繁的,那么该候选肯定不是频繁的,从而可以将其从CK中删除。
简单的讲,利用Apriori算法挖掘关联规则步骤如下:
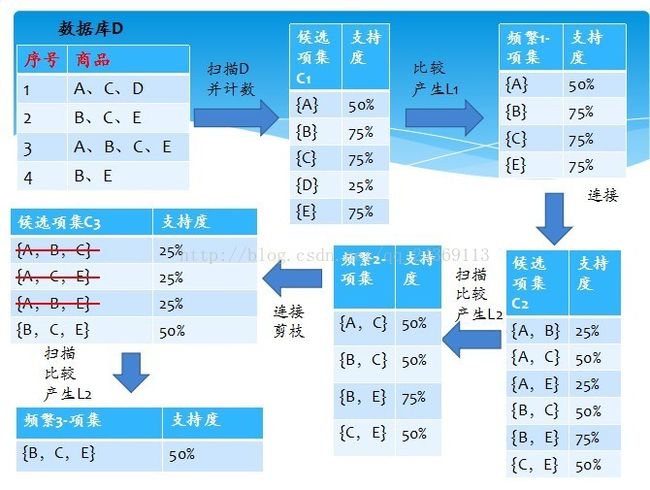
1、发现频繁项集,过程为(1)扫描(2)计数(3)比较(4)产生频繁项集(5)连接、剪枝,产生候选项集 重复步骤(1)~(5)直到不能发现更大的频集,示例如图1-1所示。
2、产生关联规则,过程为:根据前面提到的置信度的定义,关联规则的产生如下:
(1)对于每个频繁项集L,产生L的所有非空子集;
(2)对于L的每个非空子集S,如果
P(L)/P(S)≧min_conf
则输出关联规则“{ S } =>>{L-S}”
注:L-S表示在项集L中除去S子集的项集
实验结果分析:
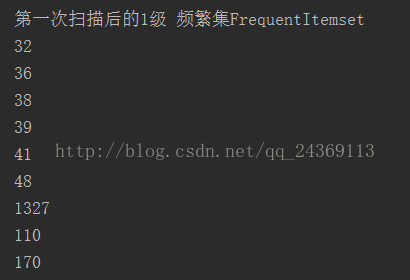
根据程序运行的结果,利用retail.txt的前1000条数据进行关联规则挖掘,在最小支持度为4%的时候(即支持度计数大于40时)其得到的频繁项集如图1-2所示,总共发现了9个一项集、10个二项集、4个三项集、1个四项集。


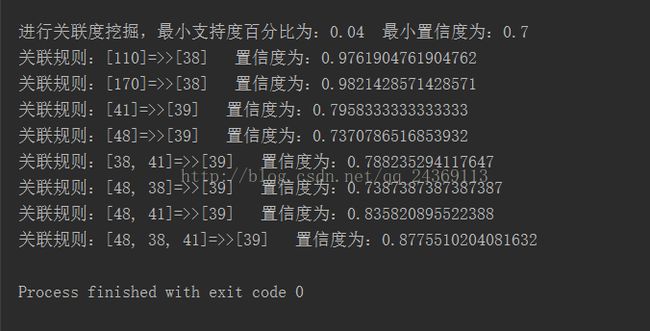
对频繁项集进行置信度计算,在最小置信度为70%的时候,挖掘出8项关联规则,其结果如图1-3所示。
思考与改进:
1. 本次实验使用Apriori算法对数据集进行关联规则的挖掘,虽然算法实现起来相对简单,但是由于其在计算支持度的时候需要每次都要扫描整个数据集,所以其效率十分低下,同时也造成了很多不必要的重复计算,因此本次实验只能选取retail.txt总共80000多条数据中的前1000条进行关联规则挖掘,如果使用完整的数据集则连一项集都需要相当长的时间才能统计出来。因此在面对大数据量的时候,Apriori算法并不是最好的选择。对于大数据集,使用Fpgrowth算法可能效率更高,但由于其实现更加复杂,在这里就不做过多赘述。
2. 为了实现简单,本次实验中实现的是最简单的Apriori算法,其在每次的计算中是有很多无用的计算,所以其实我们可以利用一些技术来提高Apriori算法的执行效率例如使用基于散列的技术、事务压缩等方法,来提高计数的效率同时减少不必要的计数,从而实现算法效率的提高。
3. 同时在本次实验中发现一个现象,如果加大数据集,例如使用retail.txt中的前2000项数据进行挖掘,在相同的支持度和置信度下,频繁项集和关联规则甚至会减少。经过分析发现,由于本次实验是利用百分比来作为支持度的阈值,当总数据集增大时,相当于支持度计数的阈值也成倍的增长,满足支持度计数的项集反而会减少,由此可见根据不同的数据集规模,选择合适的支持度百分比对于能否得到有效的关联规则至关重要。
编程实现:
本实验的工程项目和数据集可访问以下网址下载:
http://download.csdn.net/detail/qq_24369113/9712408
https://github.com/muziyongshixin/Association-rule-mining-with-Apriori
函数设计与分析:
1. public staticList> getRecord(String url)
//加载数据文件并进行预处理
2. public static void Apriori()
//实现Apriori算法的迭代
3. public static voidAssociationRulesMining()
//根据频繁项集进行关联规则的挖掘
4. public static double isAssociationRules(List s1,Lists2,List tem)
//判断s1和tem-s1是否为一个关联规则
5. public static intgetCount(List in)
//得到输入频繁项集in的支持度计数
6. public static Listgets2set(List tem, List s1)
//得到集合{tem-s1},即为s2
7. public staticList> getSubSet(List set)
//得到一个集合是所有的非空真子集
8. private staticList> getNextCandidate(List>FrequentItemset)
//有当前频繁项集自连接求下一次候选集
9. private static booleanisnotHave(HashSet hsSet, List>nextCandidateItemset)
//判断新生成的候选集是不是在已经在候选集集合中
10. private staticList>getSupprotedItemset(List> CandidateItemset)
//对候选集进行支持度计数
11. private static intcountFrequent1(List list)
//进行支持度计数
12. private staticList> findFirstCandidate()
//找到一项集的候选集 源码实现:
/**
* Created by muziyongshixin on 2016/12/6.
*
*
* 本工程包含两个数据文件
* fulldata为老师给的原始数据文件,由于数据量过大程序跑不出来结果,没有选用进行测试
* top1000data是从fulldata中摘取的前1000条数据,本程序运行的结果是基于这前1000条数据进行的频繁项集挖掘和关联度分析
*
*/
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.util.*;
/**
* Apriori算法实现 最大模式挖掘,涉及到支持度,但没有置信度计算
*
* AssociationRulesMining()函数实现置信度计算和关联规则挖掘
*/
public class AprioriMyself {
public static int times=0;//迭代次数
private static double MIN_SUPPROT = 0.02;//最小支持度百分比
private static double MIN_CONFIDENCE=0.6;//最小置信度
private static boolean endTag = false;//循环状态,迭代标识
static List> record = new ArrayList>() ;//数据集
static List> frequentItemset=new ArrayList<>();//存储所有的频繁项集
static List map = new ArrayList();//存放频繁项集和对应的支持度技术
public static void main(String args[]){
System.out.println("请输入最小支持度(如0.05)和最小置信度(如0.6)");
Scanner in=new Scanner(System.in);
MIN_SUPPROT=in.nextDouble();
MIN_CONFIDENCE=in.nextDouble();
/*************读取数据集**************/
record = getRecord("top1000data");
//控制台输出记录
System.out.println("读取数据集record成功===================================");
ShowData(record);
Apriori();//调用Apriori算法获得频繁项集
System.out.println("频繁模式挖掘完毕。\n\n\n\n\n进行关联度挖掘,最小支持度百分比为:"+MIN_SUPPROT+" 最小置信度为:"+MIN_CONFIDENCE);
AssociationRulesMining();//挖掘关联规则
}
/**********************************************
* ****************读取数据********************/
public static List> getRecord(String url) {
List> record = new ArrayList>() ;
try {
String encoding = "UTF-8"; // 字符编码(可解决中文乱码问题 )
File file = new File(url);
if (file.isFile() && file.exists()) {
InputStreamReader read = new InputStreamReader(
new FileInputStream(file), encoding);
BufferedReader bufferedReader = new BufferedReader(read);
String lineTXT = null;
while ((lineTXT = bufferedReader.readLine()) != null) {//读一行文件
String[] lineString = lineTXT.split(",");
List lineList = new ArrayList() ;
for (int i = 0; i < lineString.length; i++) {
lineList.add(lineString[i]);
}
record.add(lineList);
}
read.close();
} else {
System.out.println("找不到指定的文件!");
}
} catch (Exception e) {
System.out.println("读取文件内容操作出错");
e.printStackTrace();
}
return record;
}
public static void Apriori() /**实现apriori算法**/
{
//************获取候选1项集**************
System.out.println("第一次扫描后的1级 备选集CandidateItemset");
List> CandidateItemset = findFirstCandidate() ;
ShowData(CandidateItemset);
//************获取频繁1项集***************
System.out.println("第一次扫描后的1级 频繁集FrequentItemset");
List> FrequentItemset = getSupprotedItemset(CandidateItemset) ;
AddToFrequenceItem(FrequentItemset);//添加到所有的频繁项集中
//控制台输出1项频繁集
ShowData(FrequentItemset);
//*****************************迭代过程**********************************
times=2;
while(endTag!=true){
System.out.println("*******************************第"+times+"次扫描后备选集");
//**********连接操作****获取候选times项集**************
List> nextCandidateItemset = getNextCandidate(FrequentItemset) ;
//输出所有的候选项集
ShowData(nextCandidateItemset);
/**************计数操作***由候选k项集选择出频繁k项集****************/
System.out.println("*******************************第"+times+"次扫描后频繁集");
List> nextFrequentItemset = getSupprotedItemset(nextCandidateItemset) ;
AddToFrequenceItem(nextFrequentItemset);//添加到所有的频繁项集中
//输出所有的频繁项集
ShowData(nextFrequentItemset);
//*********如果循环结束,输出最大模式**************
if(endTag == true){
System.out.println("\n\n\nApriori算法--->最大频繁集==================================");
ShowData(FrequentItemset);
}
//****************下一次循环初值********************
FrequentItemset = nextFrequentItemset;
times++;//迭代次数加一
}
}
public static void AssociationRulesMining()//关联规则挖掘
{
for(int i=0;i<frequentItemset.size();i++)
{
List tem= frequentItemset.get(i);
if(tem.size()>1) {
List temclone= new ArrayList<>(tem);
List> AllSubset = getSubSet(temclone) ;//得到频繁项集tem的所有子集
for (int j = 0; j < AllSubset.size(); j++) {
List s1 = AllSubset.get(j) ;
List s2 = gets2set(tem , s1);
double conf = isAssociationRules(s1, s2, tem);
if (conf > 0)
System.out.println("置信度为:" + conf);
}
}
}
}
public static double isAssociationRules(List s1 ,List s2 ,List tem) //判断是否为关联规则
{
double confidence=0;
int counts1;
int countTem;
if(s1.size()!=0&&s1!=null&&tem.size()!=0&&tem!=null)
{
counts1= getCount(s1);
countTem=getCount(tem);
confidence=countTem*1.0/counts1;
if(confidence>=MIN_CONFIDENCE)
{
System.out.print("关联规则:"+ s1.toString()+"=>>"+s2.toString()+" ");
return confidence;
}
else
return 0;
}
else
return 0;
}
public static int getCount(List in) //根据频繁项集得到其支持度计数
{
int rt=0;
for(int i=0;i<map.size();i++)
{
Mymap tem=map.get(i);
if(tem.isListEqual(in)) {
rt = tem.getcount();
return rt;
}
}
return rt;
}
public static List gets2set(List tem , List s1) //计算tem减去s1后的集合即为s2
{
List result= new ArrayList<>();
for(int i=0;i;i++)//去掉s1中的所有元素
{
String t=tem.get(i);
if(!s1.contains(t))
result.add(t);
}
return result;
}
public static List> getSubSet(List set){
List> result = new ArrayList<>(); //用来存放子集的集合,如{{},{1},{2},{1,2}}
int length = set.size();
int num = length==0 ? 0 : 1<<(length); //2的n次方,若集合set为空,num为0;若集合set有4个元素,那么num为16.
//从0到2^n-1([00...00]到[11...11])
for(int i = 1; i < num-1; i++){
List subSet = new ArrayList<>();
int index = i;
for(int j = 0; j < length; j++){
if((index & 1) == 1){ //每次判断index最低位是否为1,为1则把集合set的第j个元素放到子集中
subSet.add(set.get(j));
}
index >>= 1; //右移一位
}
result.add(subSet); //把子集存储起来
}
return result;
}
public static boolean AddToFrequenceItem(List> fre)
{
for(int i=0;i;i++)
{
frequentItemset.add(fre.get(i));
}
return true;
}
public static void ShowData(List> CandidateItemset) //显示出candidateitem中的所有的项集
{
for(int i=0;i;i++){
List list = new ArrayList(CandidateItemset.get(i)) ;
for(int j=0;j;j++){
System.out.print(list.get(j)+" ");
}
System.out.println();
}
}
/**
******************************************************* 有当前频繁项集自连接求下一次候选集
*/
private static List> getNextCandidate(List> FrequentItemset) {
List> nextCandidateItemset = new ArrayList>() ;
for (int i=0; i; i++){
HashSet hsSet = new HashSet() ;
HashSet hsSettemp = new HashSet() ;
for (int k=0; k< FrequentItemset.get(i).size(); k++)//获得频繁集第i行
hsSet.add(FrequentItemset.get(i).get(k));
int hsLength_before = hsSet.size();//添加前长度
hsSettemp=(HashSet) hsSet.clone() ;
for(int h=i+1; h; h++){//频繁集第i行与第j行(j>i)连接 每次添加且添加一个元素组成 新的频繁项集的某一行,
hsSet=(HashSet) hsSettemp.clone() ;//!!!做连接的hasSet保持不变
for(int j=0; j< FrequentItemset.get(h).size();j++)
hsSet.add(FrequentItemset.get(h).get(j));
int hsLength_after = hsSet.size();
if(hsLength_before+1 == hsLength_after && isnotHave(hsSet,nextCandidateItemset)){
//如果不相等,表示添加了1个新的元素 同时判断其不是候选集中已经存在的一项
Iterator itr = hsSet.iterator() ;
List tempList = new ArrayList() ;
while(itr.hasNext()){
String Item = (String) itr.next();
tempList.add(Item);
}
nextCandidateItemset.add(tempList);
}
}
}
return nextCandidateItemset;
}
/**
* 判断新添加元素形成的候选集是否在新的候选集中
*/
private static boolean isnotHave(HashSet hsSet , List> nextCandidateItemset) { //判断hsset是不是candidateitemset中的一项
List tempList = new ArrayList() ;
Iterator itr = hsSet.iterator() ;
while(itr.hasNext()){//将hsset转换为List
String Item = (String) itr.next();
tempList.add(Item);
}
for(int i=0; i;i++)//遍历candidateitemset,看其中是否有和templist相同的一项
if(tempList.equals(nextCandidateItemset.get(i)))
return false;
return true;
}
/**
* 由k项候选集剪枝得到k项频繁集
*/
private static List> getSupprotedItemset(List> CandidateItemset) { //对所有的商品进行支持度计数
// TODO Auto-generated method stub
boolean end = true;
List> supportedItemset = new ArrayList>() ;
for (int i = 0; i < CandidateItemset.size(); i++){
int count = countFrequent1(CandidateItemset.get(i));//统计记录数
if (count >= MIN_SUPPROT * (record.size()-1)){
supportedItemset.add(CandidateItemset.get(i));
map.add(new Mymap(CandidateItemset.get(i),count));//存储当前频繁项集以及它的支持度计数
end = false;
}
}
endTag = end;//存在频繁项集则不会结束
if(endTag==true)
System.out.println("*****************无满足支持度的"+times+"项集,结束连接");
return supportedItemset;
}
/**
* 统计record中出现list集合的个数
*/
private static int countFrequent1(List list) { //遍历所有数据集record,对单个候选集进行支持度计数
int count =0;
for(int i=0;i<record.size();i++)//从record的第一个开始遍历
{
boolean flag=true;
for (int j=0;j;j++)//如果record中的第一个数据集包含list中的所有元素
{
String t=list.get(j);
if(!record.get(i).contains(t)) {
flag = false;
break;
}
}
if(flag)
count++;//支持度加一
}
return count;//返回支持度计数
}
//获得一项候选集
private static List> findFirstCandidate() {
// TODO Auto-generated method stub
List> tableList = new ArrayList>() ;
HashSet hs = new HashSet() ;//新建一个hash表,存放所有的不同的一维数据
for (int i = 1; i<record.size(); i++){ //遍历所有的数据集,找出所有的不同的商品存放到hs中
for(int j=1;j<record.get(i).size();j++){
hs.add(record.get(i).get(j));
}
}
Iterator itr = hs.iterator() ;
while(itr.hasNext()){
List tempList = new ArrayList() ;
String Item = (String) itr.next();
tempList.add(Item); //将每一种商品存放到一个List li=new LinkedList<>();
public int count;
public Mymap(List l ,int c)//构造函数 新建一个对象
{
li=l;
count=c;
}
public int getcount()//返回得到当前频繁项集的支持度计数
{
return count;
}
public boolean isListEqual(List in) //判断传入的频繁项集是否和本频繁项集相同
{
if(in.size()!=li.size())//先判断大小是否相同
return false;
else {
for(int i=0;i;i++)//遍历输入的频繁项集,判断是否所有元素都包含在本频繁项集中
{
if(!li.contains(in.get(i)))
return false;
}
}
return true;//如果两个频繁项集大小相同,同时本频繁项集包含传入的频繁项集的所有元素,则表示两个频繁项集是相等的,返回为真
}
}