Linux上安装hadoop集群
1.下载hadoop
本博文使用的hadoop是2.9.0
打开下载地址选择页面:http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.9.0/hadoop-2.9.0.tar.gz

2.修改hosts并实现ssh免密码 登录
我这里已经提前安装好了三台虚拟机,hostname分别为had01,had02,had03
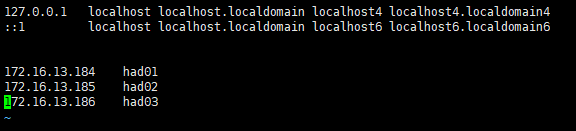
(1)修改这3台机器的/etc/hosts文件,在文件中添加以下内容:
172.16.13.184 had01
172.16.13.185 had02
172.16.13.186 had03 如下图所示:
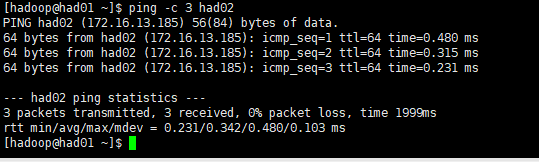
(2)配置完成后使用ping命令检查这3个机器是否相互ping得通,以had01为例,命令如下:
ping -c 3 had02如下图所示:
(3)配置ssh免密码登陆
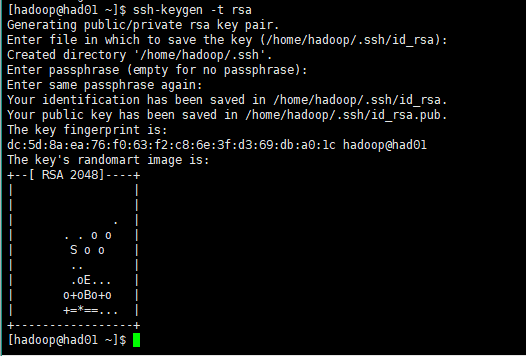
首先在had01上输入(had02,had03类似)
ssh-keygen -t rsa然后一路回车下去,如下图所示:
然后可以在/home/hadoop/.ssh/目录下可以看到:
在这里我用下图所示命令将原来had02上id_rsa.pub改为2id_rsa.pub,had03上的id_rsa.pub改为3id_rsa.pub
![]()


三个节点上的id_rsa.pub内容分别为下图所示:



然后将had02和had03上的id_rsa.pub复制到had01上的/home/hadoop/.ssh/目录下
scp 2id_rsa.pub hadoop@had01:/home/hadoop/.ssh/
scp 3id_rsa.pub hadoop@had01:/home/hadoop/.ssh/ 如下图所示:


在had01的.ssh/目录下可以看到:

将id_rsa.pub,2id_rsa.pub,3id_rsa.pub文件内容复制到这个authorized_keys文件中
cat id_rsa.pub >> authorized_keys
cat 2id_rsa.pub >> authorized_keys
cat 3id_rsa.pub >> authorized_keys如下图所示:


查看authorized_keys的内容:
vim authorized_keys
再把authorized_keys复制到had02和had03的.ssh目录下:
scp authorized_keys hadoop@had02:/home/hadoop/.ssh/
scp authorized_keys hadoop@had03:/home/hadoop/.ssh/如下图所示:


再查看had02和had03的.ssh目录:


(4) 在测试之前先对.ssh文件夹和里面的内容设置权限
sudo chmod -R 700 /home/hadoop/.ssh/
sudo chmod -R 600 authorized_keys如下图所示:



(5)最后测试一下使用ssh进行无密码登录(每次ssh完成后,都要执行exit,否则你的后续命令是在另外一台机器上执行的)
先在had01上测试(其他类似)
ssh had02
exit
ssh had03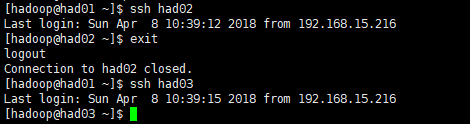
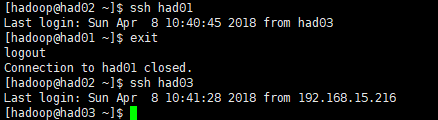

至此ssh免密码登陆配置完成!
3.安装jdk和hadoop
3.1 安装jdk
安装jdk可以参考我的另一篇文章“Tomcat服务器的搭建和Web应用的部署”,上面有详细的jdk安装过程
网址:http://blog.51cto.com/12348890/2093732
3.2 安装hadoop
三个节点都需要重复以下的步骤
首先上传hadoop的解压包到服务器

在/home/hadoop目录下新建几个目录:
sudo mkdir /opt/hadoop
mkdir /home/hadoop/hadoop
mkdir /home/hadoop/hadoop/tmp
mkdir /home/hadoop/hadoop/var
mkdir /home/hadoop/hadoop/dfs
mkdir /home/hadoop/hadoop/dfs/name
mkdir /home/hadoop/hadoop/dfs/data 如下图所示:
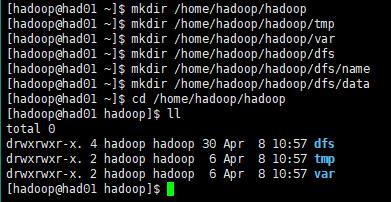
对/opt目录设置权限:
sudo chown -R hadoop:hadoop /opt

解压hadoop-2.9.0.tar.gz压缩包
tar -zxvf /home/hadoop/hadoop-2.9.0.tar.gz -C /opt/hadoop/
修改/opt/hadoop/hadoop-2.9.0/etc/hadoop目录内的一系列文件
(1)修改core-site.xml
在
hadoop.tmp.dir
/home/hadoop/hadoop/tmp
Abase for other temporary directories.
fs.default.name
hdfs://had01:9000
(2)修改hadoop-env.sh
将export JAVA_HOME=${JAVA_HOME} 修改为: export JAVA_HOME=/usr/java/jdk1.8.0_161
说明:修改为自己的JDK路径
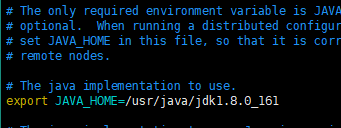
(3)修改hdfs-site.xml
在
dfs.replication
2
dfs.namenode.name.dir
/home/hadoop/hadoop/dfs/name
dfs.datanode.data.dir
/home/hadoop/hadoop/dfs/data
dfs.namenode.secondary.http-address
had01:9001
dfs.permissions
false
need not permissions
说明:dfs.permissions配置为false后,可以允许不要检查权限就生成dfs上的文件,方便倒是方便了,但是你需要防止误删除,请将它设置为true,或者直接将该property节点删除,因为默认就是true。
(4)新建并且修改mapred-site.xml
在该版本中,有一个名为mapred-site.xml.template的文件,复制该文件,然后改名为mapred-site.xml,命令是:
cp mapred-site.xml.template mapred-site.xml
修改这个新建的mapred-site.xml文件,在
mapreduce.framework.name
yarn
(5)修改slaves文件
将里面的localhost删除,添加如下内容:
had02
had03
(6)修改yarn-site.xml文件
在
yarn.resourcemanager.hostname
had01
The address of the applications manager interface in the RM.
yarn.resourcemanager.address
${yarn.resourcemanager.hostname}:8032
The address of the scheduler interface.
yarn.resourcemanager.scheduler.address
${yarn.resourcemanager.hostname}:8030
The http address of the RM web application.
yarn.resourcemanager.webapp.address
${yarn.resourcemanager.hostname}:8088
The https adddress of the RM web application.
yarn.resourcemanager.webapp.https.address
${yarn.resourcemanager.hostname}:8090
yarn.resourcemanager.resource-tracker.address
${yarn.resourcemanager.hostname}:8031
The address of the RM admin interface.
yarn.resourcemanager.admin.address
${yarn.resourcemanager.hostname}:8033
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.scheduler.maximum-allocation-mb
2048
每个节点可用内存,单位MB,默认8182MB
yarn.nodemanager.vmem-pmem-ratio
2.1
任务每使用1MB物理内存,最多可使用虚拟内存量,默认是2.1
yarn.nodemanager.resource.memory-mb
2048
yarn.nodemanager.vmem-check-enabled
false
说明:yarn.nodemanager.vmem-check-enabled这个的意思是忽略虚拟内存的检查,如果你是安装在虚拟机上,这个配置很有用,配上去之后后续操作不容易出问题。如果是实体机上,并且内存够多,可以将这个配置去掉。
3.3启动hadoop
(1)在namenode节点上执行初始化
因为had01是namenode,had02和had03都是datanode,所以只需要对had01进行初始化操作,也就是对hdfs进行格式化。
进入到hserver1这台机器的/opt/hadoop/hadoop-2.9.0/bin目录,也就是执行命令:
./hadoop namenode -format如下图所示:
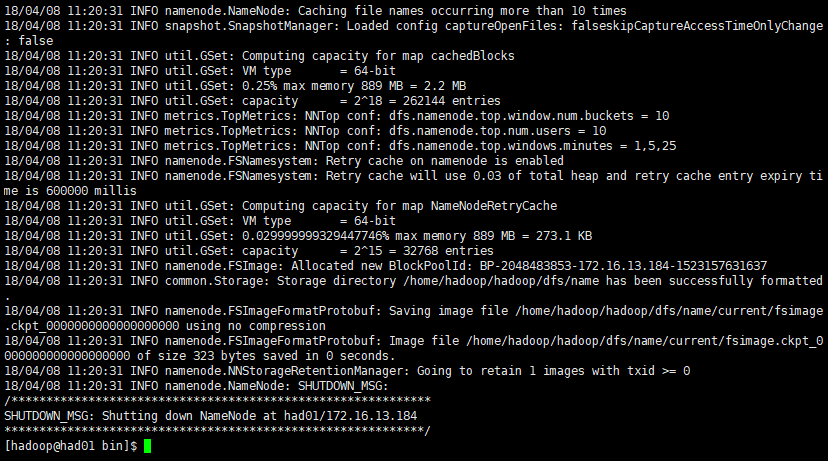
格式化成功后,可以在看到在/root/hadoop/dfs/name/目录多了一个current目录,而且该目录内有一系列文件
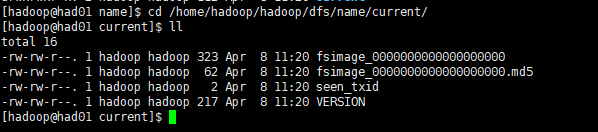
(2)在namenode上执行启动命令
因为had01是namenode,had02和had03都是datanode,所以只需要在had01上执行启动命令即可。
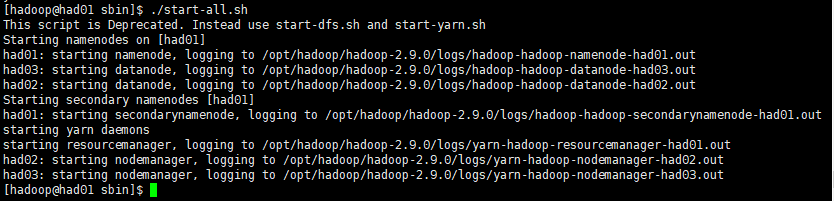
进入到hserver1这台机器的/opt/hadoop/hadoop-2.8.0/sbin目录,也就是执行命令:
cd /opt/hadoop/hadoop-2.9.0/sbin执行初始化脚本,也就是执行命令:
./start-all.sh如下图所示:
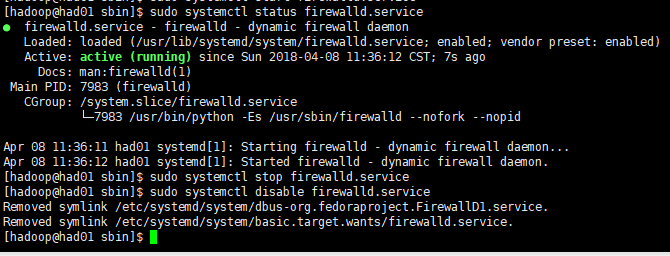
sudo systemctl status firewalld.service #查看防火墙状态
sudo systemctl stop firewalld.service #停止防火墙
sudo systemctl disable firewalld.service #禁止防火墙启动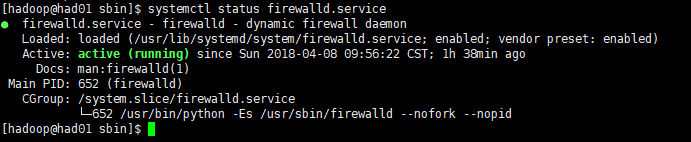
(4)测试hadoop
使用jps命令查看各个节点的进程,如下图所示:
had01
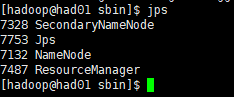
had02

had03

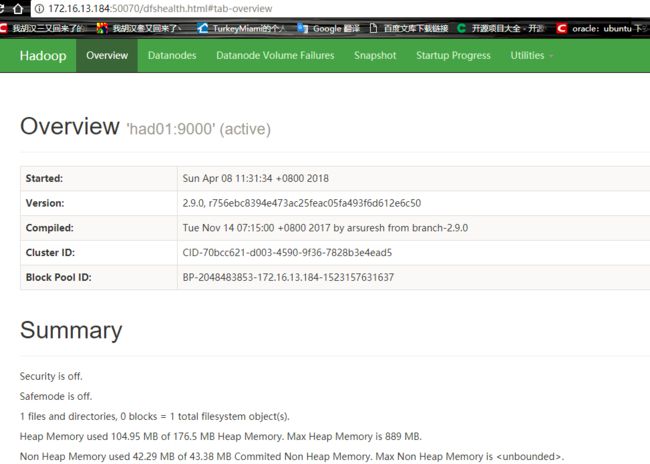
had01是我们的namanode,该机器的IP是172.16.13.184,在谷歌浏览器访问如下地址:http://172.16.13.184:50070
自动跳转到了overview页面,如下图所示:
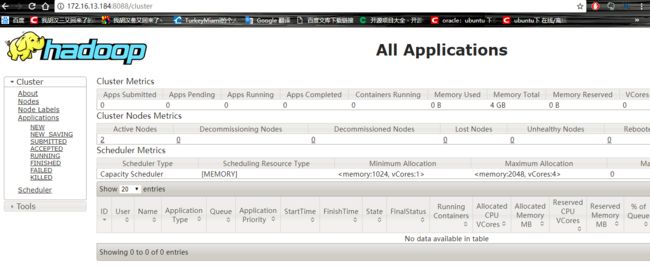
在谷歌浏览器里访问如下地址:http://172.16.13.184:8088
自动跳转到了cluster页面,如下图所示:
至此hadoop集群的安装完成!