(十八)Python爬虫:XPath的使用
经历了爬取豆瓣电影TOP250数据我们会发现使用正则表达式其实并没有多么方便,有没有更加好的工具呢?答案当然是有的。接下来将使用三个篇幅分别介绍XPath,Beautiful Soup和pyquery这三个解析库。
XPath介绍
XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言。XPath基于XML的树状结构,有不同类型的节点,包括元素节点,属性节点和文本节点,提供在数据结构树中找寻节点的能力。 起初 XPath 的提出的初衷是将其作为一个通用的、介于XPointer与XSLT间的语法模型。但是 XPath 很快的被开发者采用来当作小型查询语言。[来自360百科] 现在我们使用它对HTML文档进行搜索。
lxml的安装
lxml库是Python的一个解析库,支持HTML和XML的解析,支持XPath。下面介绍在Windows,Linux和Mac上的安装。
Windows下的安装
首先使用命令`pip3 install lxml`进行安装。如果没有错误信息说明安装成功了;如果出现错误,比如缺少libxml2库,使用wheel文件离线安装。提供Win64位,Python3.6的lxml安装包:https://pan.baidu.com/s/1wM1xKxCxOH8QOWclp6iasw。使用命令`pip3 install lxml-4.2.4-cp36-cp36m-win_amd64.whl`进行安装。Linux下的安装
首先也是使用命令`pip3 install lxml`进行安装。如果没有错误信息说明安装成功了。如果报错一般都是缺少必要的库,可以参考以下解决方案。- Centos、Red Hat:
yum groupinstall -y development tools
yum install -y epel-release libxslt-devel libxml2-devel openssl-devel
- Ubuntu、Debian和Deepin:
sudo apt-get install -y python3-dev build-essential libssl-dev libffi-dev libxml2 libxml2-dev libxslt1-dev zlib1g-dev
安装好这些必要的类库后重试命令pip3 install lxml进行安装。
Mac下的安装
首先也是使用命令`pip3 install lxml`进行安装。如果没有错误信息说明安装成功了。如果报错一般都是缺少必要的库,执行命令`xcode-select --install`。再次重试安装命令。验证安装
 如果导入lxml库没有错误则证明安装成功了!
如果导入lxml库没有错误则证明安装成功了!
XPath常用规则
| 表达式 | 描述 |
|---|---|
| nodename | 选择这个节点名的所有子节点 |
| / | 从当前节点选择直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选择当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
标签补全
以下是一段HTML:
<div>
<ul>
<li class="item-0"><a href="www.baidu.com">baidua>
<li class="item-1"><a href="https://blog.csdn.net/qq_25343557">mybloga>
<li class="item-2"><a href="https://www.csdn.net/">csdna>
<li class="item-3"><a href="https://hao.360.cn/?a1004">hao123a>
显然,这段HTML中的节点没有闭合,我们可以使用lxml中的etree模块进行补全。
from lxml import etree
text = '''
- baidu
- myblog
- csdn
- hao123
'''
html = etree.HTML(text)
result = etree.tostring(html)
print(result.decode('UTF-8'))

可以看见etree不仅将节点闭合了还添加了其他需要的标签。
除了直接读取文本进行解析,etree也可以读取文件进行解析。
from lxml import etree
html = etree.parse('./test.html',etree.HTMLParser())
result = etree.tostring(html)
print(result.decode('UTF-8'))

获取所有节点
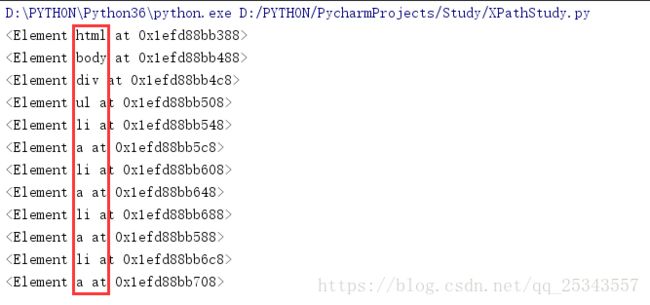
根据XPath常用规则可以知道通过//可以查找当前节点下的子孙节点,以上面的html为例获取所有节点。
from lxml import etree
html = etree.parse('./test.html',etree.HTMLParser())
result = html.xpath('//*')#'//'表示获取当前节点子孙节点,'*'表示所有节点,'//*'表示获取当前节点下所有节点
for item in result:
print(item)
如果我们不要获取所有节点而是指定获取某个名称的节点,只需要将*改为指定节点名称即可。如获取所有的li节点
from lxml import etree
html = etree.parse('./test.html',etree.HTMLParser())
result = html.xpath('//li')#将*改为li,表示只获取名称为li的子孙节点
#返回一个列表
for item in result:
print(item)

获取子节点
根据XPath常用规则我们可以使用/或//获取子孙节点或子节点。现在我要获取li节点下的a节点。
from lxml import etree
html = etree.parse('./test.html',etree.HTMLParser())
result = html.xpath('//li/a')#//li选择所有的li节点,/a选择li节点下的直接子节点a
for item in result:
print(item)

我们也可以使用//ul//a首先选择所有的ul节点,再获取ul节点下的的所有a节点,最后结果也是一样的。但是使用//ul/a就不行了,首先选择所有的ul节点,再获取ul节点下的直接子节点a,然而ul节点下没有直接子节点a,当然获取不到。需要深刻理解//和/的不同之处。/用于获取直接子节点,//用于获取子孙节点。
根据属性获取
根据XPath常用规则可以通过@匹配指定的属性。我们通过class属性找最后一个li节点。
from lxml import etree
html = etree.parse('./test.html',etree.HTMLParser())
result = html.xpath('//li[@class="item-3"]')#最后一个li的class属性值为item-3,返回列表形式
print(result)
获取父节点
根据XPath常用规则可以通过..获取当前节点的父节点。现在我要获取最后一个a节点的父节点下的class属性。
from lxml import etree
html = etree.parse('./test.html',etree.HTMLParser())
result = html.xpath('//a[@href="https://hao.360.cn/?a1004"]/../@class')
#a[@href="https://hao.360.cn/?a1004"]:选择href属性为https://hao.360.cn/?a1004的a节点
#..:选取父节点
#@class:选取class属性,获取属性值
print(result)
获取文本信息
很多时候我们找到指定的节点都是要获取节点内的文本信息。我们使用text()方法获取节点中的文本。现在获取所有a标签的文本信息。
from lxml import etree
html = etree.parse('./test.html',etree.HTMLParser())
result = html.xpath('//ul//a/text()')
print(result)
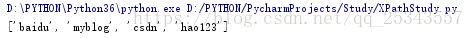
属性多值匹配
在上面的例子中所有的属性值都只有一个,如果属性值有多个还能匹配的上吗?
from lxml import etree
text = '''
- baidu
- myblog
- csdn
- hao123
'''
html = etree.HTML(text)
result = html.xpath('//li[@class="sp"]')
print(result)
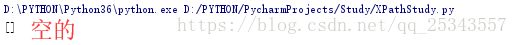
第二个li节点的class属性有两个值:sp和item-1。如果我们的xpath匹配规则为//li[@class="sp"]匹配的仅仅是class属性值只为sp的li节点,这显然是不存在的。
遇到属性值有多个的情况我们需要使用contains()函数了,contains()匹配一个属性值中包含的字符串 。包含的字符串,而不是某个值。
from lxml import etree
text = '''
- baidu
- myblog
- csdn
- hao123
'''
html = etree.HTML(text)
result = html.xpath('//li[contains(@class,"sp")]/a/text()')
print(result)
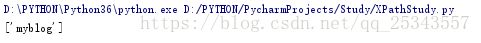
多属性匹配
属性多值匹配是节点属性有许多个值,我们根据一个值获取符合添加的节点。由于我们很多情况下无法仅仅根据一个属性值就获取到目标节点,往往要根据多个属性来获取目标节点。
from lxml import etree
text = '''
- baidu
'''
html = etree.HTML(text)
result = html.xpath('//li[contains(@class,"item-0") and @name="one"]/a/text()')#使用and操作符将两个条件相连。
print(result)
也许你会说这个直接使用name的属性值就可以得到了,然而,这里只是作为演示。
下面列出了可用在 XPath 表达式中的运算符:
运算符
描述
实例
返回值
|
计算两个节点集
//book | //cd
返回所有拥有 book 和 cd 元素的节点集
+
加法
6 + 4
10
-
减法
6 - 4
2
*
乘法
6 * 4
24
div
除法
8 div 4
2
=
等于
price=9.80
如果 price 是 9.80,则返回 true。
如果 price 是 9.90,则返回 false。
!=
不等于
price!=9.80
如果 price 是 9.90,则返回 true。
如果 price 是 9.80,则返回 false。
<
小于
price<9.80
如果 price 是 9.00,则返回 true。
如果 price 是 9.90,则返回 false。
<=
小于或等于
price<=9.80
如果 price 是 9.00,则返回 true。
如果 price 是 9.90,则返回 false。
>
大于
price>9.80
如果 price 是 9.90,则返回 true。
如果 price 是 9.80,则返回 false。
>=
大于或等于
price>=9.80
如果 price 是 9.90,则返回 true。
如果 price 是 9.70,则返回 false。
or
或
price=9.80 or price=9.70
如果 price 是 9.80,则返回 true。
如果 price 是 9.50,则返回 false。
and
与
price>9.00 and price<9.90
如果 price 是 9.80,则返回 true。
如果 price 是 8.50,则返回 false。
mod
计算除法的余数
5 mod 2
1
【上表来源:w3school运算符】
根据顺序选择
在上面的操作中我多次找第2个li节点或找最后一个li节点,使用属性值进行匹配。其实何必呢!我们可以根据顺序进行选择。
from lxml import etree
text = '''
- baidu
- myblog
- csdn
- hao123
'''
html = etree.HTML(text)
result = html.xpath('//li[2]/a/text()')#选择第二个li节点,获取a节点的文本
print(result)
result = html.xpath('//li[last()]/a/text()')#选择最后一个li节点,获取a节点的文本
print(result)
result = html.xpath('//li[last()-1]/a/text()')#选择倒数第2个li节点,获取a节点的文本
print(result)
result = html.xpath('//li[position()<=3]/a/text()')#选择前三个li节点,获取a节点的文本
print(result)

我们使用了last()和postion()函数,在XPath中还有很多函数,详情见:w3school 函数。
XPath 轴
我们可以通过XPath获取祖先节点,属性值,兄弟节点等等,这就是XPath的节点轴。轴可定义相对于当前节点的节点集。
轴名称
结果
ancestor
选取当前节点的所有先辈(父、祖父等)。
ancestor-or-self
选取当前节点的所有先辈(父、祖父等)以及当前节点本身。
attribute
选取当前节点的所有属性。
child
选取当前节点的所有直接子元素。
descendant
选取当前节点的所有后代元素(子、孙等)。
descendant-or-self
选取当前节点的所有后代元素(子、孙等)以及当前节点本身。
following
选取文档中当前节点的结束标签之后的所有节点。
following-sibling
选取当前节点之后的所有同级节点。
namespace
选取当前节点的所有命名空间节点。
parent
选取当前节点的父节点。
preceding
选取文档中当前节点的开始标签之前的所有同级节点及同级节点下的节点。
preceding-sibling
选取当前节点之前的所有同级节点。
self
选取当前节点。
【上表来源:[w3school XPath轴](https://www.w3cschool.cn/xpath/xpath-axes.html)】
使用示例:
from lxml import etree
text = '''
- baidu
- myblog
- csdn
- hao123
'''
html = etree.HTML(text)
result = html.xpath('//li[1]/ancestor::*')#ancestor表示选取当前节点祖先节点,*表示所有节点。合:选择当前节点的所有祖先节点。
print(result)
result = html.xpath('//li[1]/ancestor::div')#ancestor表示选取当前节点祖先节点,div表示div节点。合:选择当前节点的div祖先节点。
print(result)
result = html.xpath('//li[1]/ancestor-or-self::*')#ancestor-or-self表示选取当前节点及祖先节点,*表示所有节点。合:选择当前节点的所有祖先节点及本及本身。
print(result)
result = html.xpath('//li[1]/attribute::*')#attribute表示选取当前节点的所有属性,*表示所有节点。合:选择当前节点的所有属性。
print(result)
result = html.xpath('//li[1]/attribute::name')#attribute表示选取当前节点的所有属性,name表示name属性。合:选择当前节点的name属性值。
print(result)
result = html.xpath('//ul/child::*')#child表示选取当前节点的所有直接子元素,*表示所有节点。合:选择ul节点的所有直接子节点。
print(result)
result = html.xpath('//ul/child::li[@name="two"]')#child表示选取当前节点的所有直接子元素,li[@name="two"]表示name属性值为two的li节点。合:选择ul节点的所有name属性值为two的li节点。
print(result)
result = html.xpath('//ul/descendant::*')#descendant表示选取当前节点的所有后代元素(子、孙等),*表示所有节点。合:选择ul节点的所有子节点。
print(result)
result = html.xpath('//ul/descendant::a/text()')#descendant表示选取当前节点的所有后代元素(子、孙等),a/test()表示a节点的文本内容。合:选择ul节点的所有a节点的文本内容。
print(result)
result = html.xpath('//li[1]/following::*')#following表示选取文档中当前节点的结束标签之后的所有节点。,*表示所有节点。合:选择第一个li节点后的所有节点。
print(result)
result = html.xpath('//li[1]/following-sibling::*')#following-sibling表示选取当前节点之后的所有同级节点。,*表示所有节点。合:选择第一个li节点后的所有同级节点。
print(result)
result = html.xpath('//li[1]/parent::*')#选取当前节点的父节点。父节点只有一个,祖先节点可能多个。
print(result)
result = html.xpath('//li[3]/preceding::*')#preceding表示选取文档中当前节点的开始标签之前的所有同级节点及同级节点下的节点。,*表示所有节点。合:选择第三个li节点前的所有同级节点及同级节点下的子节点。
print(result)
result = html.xpath('//li[3]/preceding-sibling::*')#preceding-sibling表示选取当前节点之前的所有同级节点。,*表示所有节点。合:选择第三个li节点前的所有同级节点。
print(result)
result = html.xpath('//li[3]/self::*')#选取当前节点。
print(result)

XPath Helper插件
实话说我不想写XPath的匹配规则,在真正的网页解析中怎么可能那么短的规则。这时候我们就可以使用Chrome的插件XPath Helper了【下载地址】,使用它我们可以很快速的得到匹配规则。直接将下载下来的crx文件拖进Chrome扩展程序界面安装即可。

出现红框内图标说明安装成功了。
运行XPath Helper插件,安装shift选择我们需要的内容,自动生成匹配规则。

插件----让前面一切“白干”。_