字符串常量池、class常量池和运行时常量池
原文链接:http://tangxman.github.io/2015/07/27/the-difference-of-java-string-pool/
在java的内存分配中,经常听到很多关于常量池的描述,我开始看的时候也是看的很模糊,网上五花八门的说法简直太多了,最后查阅各种资料,终于算是差不多理清了,很多网上说法都有问题,笔者尝试着来区分一下这几个概念。
1.全局字符串池(string pool也有叫做string literal pool)
全局字符串池里的内容是在类加载完成,经过验证,准备阶段之后在堆中生成字符串对象实例,然后将该字符串对象实例的引用值存到string pool中(记住:string pool中存的是引用值而不是具体的实例对象,具体的实例对象是在堆中开辟的一块空间存放的。)。 在HotSpot VM里实现的string pool功能的是一个StringTable类,它是一个哈希表,里面存的是驻留字符串(也就是我们常说的用双引号括起来的)的引用(而不是驻留字符串实例本身),也就是说在堆中的某些字符串实例被这个StringTable引用之后就等同被赋予了”驻留字符串”的身份。这个StringTable在每个HotSpot VM的实例只有一份,被所有的类共享。
2.class文件常量池(class constant pool)
我们都知道,class文件中除了包含类的版本、字段、方法、接口等描述信息外,还有一项信息就是常量池(constant pool table),用于存放编译器生成的各种字面量(Literal)和符号引用(Symbolic References)。 字面量就是我们所说的常量概念,如文本字符串、被声明为final的常量值等。 符号引用是一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能无歧义地定位到目标即可(它与直接引用区分一下,直接引用一般是指向方法区的本地指针,相对偏移量或是一个能间接定位到目标的句柄)。一般包括下面三类常量:
- 类和接口的全限定名
- 字段的名称和描述符
- 方法的名称和描述符
常量池的每一项常量都是一个表,一共有如下表所示的11种各不相同的表结构数据,这每个表开始的第一位都是一个字节的标志位(取值1-12),代表当前这个常量属于哪种常量类型。  每种不同类型的常量类型具有不同的结构,具体的结构本文就先不叙述了,本文着重区分这三个常量池的概念(读者若想深入了解每种常量类型的数据结构可以查看《深入理解java虚拟机》第六章的内容)。
每种不同类型的常量类型具有不同的结构,具体的结构本文就先不叙述了,本文着重区分这三个常量池的概念(读者若想深入了解每种常量类型的数据结构可以查看《深入理解java虚拟机》第六章的内容)。
3.运行时常量池(runtime constant pool)
当java文件被编译成class文件之后,也就是会生成我上面所说的class常量池,那么运行时常量池又是什么时候产生的呢?
jvm在执行某个类的时候,必须经过加载、连接、初始化,而连接又包括验证、准备、解析三个阶段。而当类加载到内存中后,jvm就会将class常量池中的内容存放到运行时常量池中,由此可知,运行时常量池也是每个类都有一个。在上面我也说了,class常量池中存的是字面量和符号引用,也就是说他们存的并不是对象的实例,而是对象的符号引用值。而经过解析(resolve)之后,也就是把符号引用替换为直接引用,解析的过程会去查询全局字符串池,也就是我们上面所说的StringTable,以保证运行时常量池所引用的字符串与全局字符串池中所引用的是一致的。
举个实例来说明一下:
public class HelloWorld {
public static void main(String []args) {
String str1 = "abc";
String str2 = new String("def");
String str3 = "abc";
String str4 = str2.intern();
String str5 = "def";
System.out.println(str1 == str3);//true
System.out.println(str2 == str4);//false
System.out.println(str4 == str5);//true
}
}回到上面的那个程序,现在就很容易解释整个程序的内存分配过程了,首先,在堆中会有一个”abc”实例,全局StringTable中存放着”abc”的一个引用值,然后在运行第二句的时候会生成两个实例,一个是”def”的实例对象,并且StringTable中存储一个”def”的引用值,还有一个是new出来的一个”def”的实例对象,与上面那个是不同的实例,当在解析str3的时候查找StringTable,里面有”abc”的全局驻留字符串引用,所以str3的引用地址与之前的那个已存在的相同,str4是在运行的时候调用intern()函数,返回StringTable中”def”的引用值,如果没有就将str2的引用值添加进去,在这里,StringTable中已经有了”def”的引用值了,所以返回上面在new str2的时候添加到StringTable中的 “def”引用值,最后str5在解析的时候就也是指向存在于StringTable中的”def”的引用值,那么这样一分析之后,下面三个打印的值就容易理解了。上面程序的首先经过编译之后,在该类的class常量池中存放一些符号引用,然后类加载之后,将class常量池中存放的符号引用转存到运行时常量池中,然后经过验证,准备阶段之后,在堆中生成驻留字符串的实例对象(也就是上例中str1所指向的”abc”实例对象),然后将这个对象的引用存到全局String Pool中,也就是StringTable中,最后在解析阶段,要把运行时常量池中的符号引用替换成直接引用,那么就直接查询StringTable,保证StringTable里的引用值与运行时常量池中的引用值一致,大概整个过程就是这样了。
总结
- 1.全局常量池在每个VM中只有一份,存放的是字符串常量的引用值。
- 2.class常量池是在编译的时候每个class都有的,在编译阶段,存放的是常量的符号引用。
- 3.运行时常量池是在类加载完成之后,将每个class常量池中的符号引用值转存到运行时常量池中,也就是说,每个class都有一个运行时常量池,类在解析之后,将符号引用替换成直接引用,与全局常量池中的引用值保持一致。
================================
class文件常量池和运行时常量池
最近一直被方法区里面存着什么东西困扰着?
1.方法区里存class文件信息和class文件常量池是个什么关系。
2.class文件常量池和运行时常量池是什么关系。
方法区存着类的信息,常量和静态变量,即类被编译后的数据。这个说法其实是没问题的,只是太笼统了。更加详细一点的说法是方法区里存放着类的版本,字段,方法,接口和常量池。常量池里存储着字面量和符号引用。
符号引用包括:1.类的全限定名,2.字段名和属性,3.方法名和属性。
下面一张图是我画的方法区,class文件信息,class文件常量池和运行时常量池的关系
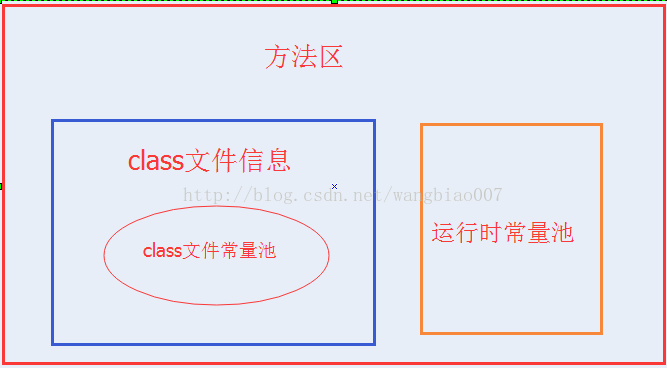
下面一张图用来表示方法区class文件信息包括哪些内容:

可以看到在方法区里的class文件信息包括:魔数,版本号,常量池,类,父类和接口数组,字段,方法等信息,其实类里面又包括字段和方法的信息。
下面的图表是class文件中存储的数据类型
| 类型 | 名称 | 数量 |
| u4 | magic | 1 |
| u2 | minor_version | 1 |
| u2 | major_version | 1 |
| u2 | constant_pool_count | 1 |
| cp_info | constant_pool | constant_pool_count - 1 |
| u2 | access_flags | 1 |
| u2 | this_class | 1 |
| u2 | super_class | 1 |
| u2 | interfaces_count | 1 |
| u2 | interfaces | interfaces_count |
| u2 | fields_count | 1 |
| field_info | fields | fields_count |
| u2 | methods_count | 1 |
| method_info | methods | methods_count |
| u2 | attribute_count | 1 |
| attribute_info | attributes | attributes_count |
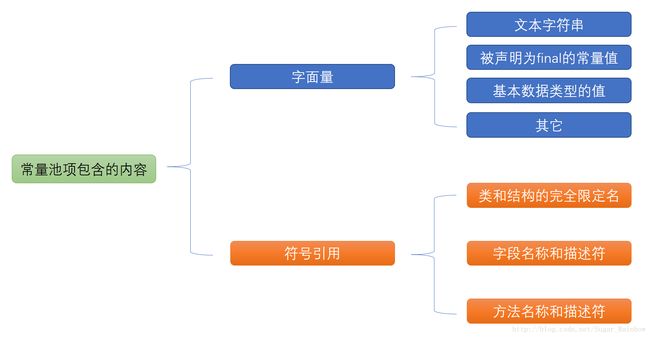
下面用一张图来表示常量池里存储的内容:
用一个class文件实际反编译一下
下面是原java代码
[java] view plain copy
- public class TestInt {
- private String str = "hello";
- void printInt(){
- System.out.println(65535);
- }
- }
经过反编译后获得class文件是下面这样的

可以看出被反编译的class文件中的内容和上面所说的是能对应上的。这就解答了class文件和class文件常量池的关系
class文件常量池和运行时常量池的关系以及区别
class文件常量池存储的是当class文件被java虚拟机加载进来后存放在方法区的一些字面量和符号引用,字面量包括字符串,基本类型的常量。
运行时常量池是当class文件被加载完成后,java虚拟机会将class文件常量池里的内容转移到运行时常量池里,在class文件常量池的符号引用有一部分是会被转变为直接引用的,比如说类的静态方法或私有方法,实例构造方法,父类方法,这是因为这些方法不能被重写其他版本,所以能在加载的时候就可以将符号引用转变为直接引用,而其他的一些方法是在这个方法被第一次调用的时候才会将符号引用转变为直接引用的。
总结:
方法区里存储着class文件的信息和运行时常量池,class文件的信息包括类信息和class文件常量池。
运行时常量池里的内容除了是class文件常量池里的内容外,还将class文件常量池里的符号引用转变为直接引用,而且运行时常量池里的内容是能动态添加的。例如调用String的intern方法就能将string的值添加到String常量池中,这里String常量池是包含在运行时常量池里的,但在jdk1.8后,将String常量池放到了堆中。
下面有一篇文章写的是比较好的
http://blog.csdn.net/vegetable_bird_001/article/details/51278339
https://www.cnblogs.com/holos/p/6603379.html
=====================================
基本类型的包装类、String类和常量池
一.相关概念
-
什么是常量
用final修饰的成员变量表示常量,值一旦给定就无法改变!
final修饰的变量有三种:静态变量、实例变量和局部变量,分别表示三种类型的常量。 -
Class文件中的常量池
在Class文件结构中,最头的4个字节用于存储魔数Magic Number,用于确定一个文件是否能被JVM接受,再接着4个字节用于存储版本号,前2个字节存储次版本号,后2个存储主版本号,再接着是用于存放常量的常量池,由于常量的数量是不固定的,所以常量池的入口放置一个U2类型的数据(constant_pool_count)存储常量池容量计数值。
常量池主要用于存放两大类常量:字面量(Literal)和符号引用量(Symbolic References),字面量相当于Java语言层面常量的概念,如文本字符串,声明为final的常量值等,符号引用则属于编译原理方面的概念,包括了如下三种类型的常量:
- 类和接口的全限定名
- 字段名称和描述符
- 方法名称和描述符
-
方法区中的运行时常量池
运行时常量池是方法区的一部分。
CLass文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池,用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中存放。
运行时常量池相对于CLass文件常量池的另外一个重要特征是具备动态性,Java语言并不要求常量一定只有编译期才能产生,也就是并非预置入CLass文件中常量池的内容才能进入方法区运行时常量池,运行期间也可能将新的常量放入池中,这种特性被开发人员利用比较多的就是String类的intern()方法。 -
常量池的好处
常量池是为了避免频繁的创建和销毁对象而影响系统性能,其实现了对象的共享。
例如字符串常量池,在编译阶段就把所有的字符串文字放到一个常量池中。
(1)节省内存空间:常量池中所有相同的字符串常量被合并,只占用一个空间。
(2)节省运行时间:比较字符串时,==比equals()快。对于两个引用变量,只用==判断引用是否相等,也就可以判断实际值是否相等。 -
双等号==的含义
基本数据类型之间应用双等号,比较的是他们的数值。
复合数据类型(类)之间应用双等号,比较的是他们在内存中的存放地址。
二.8种基本类型的包装类和常量池
- java中基本类型的包装类的大部分都实现了常量池技术,
即Byte,Short,Integer,Long,Character,Boolean;
Integer i1 = 40;
Integer i2 = 40;
System.out.println(i1==i2);//输出TRUE
这5种包装类默认创建了数值[-128,127]的相应类型的缓存数据,但是超出此范围仍然会去创建新的对象。
//Integer 缓存代码 :
public static Integer valueOf(int i) {
assert IntegerCache.high >= 127;
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
Integer i1 = 400;
Integer i2 = 400;
System.out.println(i1==i2);//输出false
- 两种浮点数类型的包装类Float,Double并没有实现常量池技术。
Double i1=1.2;
Double i2=1.2;
System.out.println(i1==i2);//输出false
- 应用常量池的场景
(1)Integer i1=40;Java在编译的时候会直接将代码封装成Integer i1=Integer.valueOf(40);,从而使用常量池中的对象。
(2)Integer i1 = new Integer(40);这种情况下会创建新的对象。
Integer i1 = 40;
Integer i2 = new Integer(40);
System.out.println(i1==i2);//输出false
- Integer比较更丰富的一个例子
Integer i1 = 40;
Integer i2 = 40;
Integer i3 = 0;
Integer i4 = new Integer(40);
Integer i5 = new Integer(40);
Integer i6 = new Integer(0);
System.out.println("i1=i2 " + (i1 == i2));
System.out.println("i1=i2+i3 " + (i1 == i2 + i3));
System.out.println("i1=i4 " + (i1 == i4));
System.out.println("i4=i5 " + (i4 == i5));
System.out.println("i4=i5+i6 " + (i4 == i5 + i6));
System.out.println("40=i5+i6 " + (40 == i5 + i6));
i1=i2 true
i1=i2+i3 true
i1=i4 false
i4=i5 false
i4=i5+i6 true
40=i5+i6 true
解释:语句i4 == i5 + i6,因为+这个操作符不适用于Integer对象,首先i5和i6进行自动拆箱操作,进行数值相加,即i4 == 40。然后Integer对象无法与数值进行直接比较,所以i4自动拆箱转为int值40,最终这条语句转为40 == 40进行数值比较。
Java中的自动装箱与拆箱
三.String类和常量池
- String对象创建方式
String str1 = "abcd";
String str2 = new String("abcd");
System.out.println(str1==str2);//false
这两种不同的创建方法是有差别的,第一种方式是在常量池中拿对象,第二种方式是直接在堆内存空间创建一个新的对象。
只要使用new方法,便需要创建新的对象。
- 连接表达式 +
(1)只有使用引号包含文本的方式创建的String对象之间使用“+”连接产生的新对象才会被加入字符串池中。
(2)对于所有包含new方式新建对象(包括null)的“+”连接表达式,它所产生的新对象都不会被加入字符串池中。
String str1 = "str";
String str2 = "ing";
String str3 = "str" + "ing";
String str4 = str1 + str2;
System.out.println(str3 == str4);//false
String str5 = "string";
System.out.println(str3 == str5);//true
java基础:字符串的拼接
- 特例1
public static final String A = "ab"; // 常量A
public static final String B = "cd"; // 常量B
public static void main(String[] args) {
String s = A + B; // 将两个常量用+连接对s进行初始化
String t = "abcd";
if (s == t) {
System.out.println("s等于t,它们是同一个对象");
} else {
System.out.println("s不等于t,它们不是同一个对象");
}
}
s等于t,它们是同一个对象
A和B都是常量,值是固定的,因此s的值也是固定的,它在类被编译时就已经确定了。也就是说:String s=A+B; 等同于:String s="ab"+"cd";
- 特例2
public static final String A; // 常量A
public static final String B; // 常量B
static {
A = "ab";
B = "cd";
}
public static void main(String[] args) {
// 将两个常量用+连接对s进行初始化
String s = A + B;
String t = "abcd";
if (s == t) {
System.out.println("s等于t,它们是同一个对象");
} else {
System.out.println("s不等于t,它们不是同一个对象");
}
}
s不等于t,它们不是同一个对象
A和B虽然被定义为常量,但是它们都没有马上被赋值。在运算出s的值之前,他们何时被赋值,以及被赋予什么样的值,都是个变数。因此A和B在被赋值之前,性质类似于一个变量。那么s就不能在编译期被确定,而只能在运行时被创建了。
-
String s1 = new String("xyz");创建了几个对象?
考虑类加载阶段和实际执行时。
(1)类加载对一个类只会进行一次。"xyz"在类加载时就已经创建并驻留了(如果该类被加载之前已经有"xyz"字符串被驻留过则不需要重复创建用于驻留的"xyz"实例)。驻留的字符串是放在全局共享的字符串常量池中的。
(2)在这段代码后续被运行的时候,"xyz"字面量对应的String实例已经固定了,不会再被重复创建。所以这段代码将常量池中的对象复制一份放到heap中,并且把heap中的这个对象的引用交给s1 持有。
这条语句创建了2个对象。 -
java.lang.String.intern()
运行时常量池相对于CLass文件常量池的另外一个重要特征是具备动态性,Java语言并不要求常量一定只有编译期才能产生,也就是并非预置入CLass文件中常量池的内容才能进入方法区运行时常量池,运行期间也可能将新的常量放入池中,这种特性被开发人员利用比较多的就是String类的intern()方法。
String的intern()方法会查找在常量池中是否存在一份equal相等的字符串,如果有则返回该字符串的引用,如果没有则添加自己的字符串进入常量池。
public static void main(String[] args) {
String s1 = new String("计算机");
String s2 = s1.intern();
String s3 = "计算机";
System.out.println("s1 == s2? " + (s1 == s2));
System.out.println("s3 == s2? " + (s3 == s2));
}
s1 == s2? false
s3 == s2? true
- 字符串比较更丰富的一个例子
public class Test {
public static void main(String[] args) {
String hello = "Hello", lo = "lo";
System.out.println((hello == "Hello") + " ");
System.out.println((Other.hello == hello) + " ");
System.out.println((other.Other.hello == hello) + " ");
System.out.println((hello == ("Hel"+"lo")) + " ");
System.out.println((hello == ("Hel"+lo)) + " ");
System.out.println(hello == ("Hel"+lo).intern());
}
}
class Other { static String hello = "Hello"; }
package other;
public class Other { public static String hello = "Hello"; }
true true true true false true```
在同包同类下,引用自同一String对象.
在同包不同类下,引用自同一String对象.
在不同包不同类下,依然引用自同一String对象.
在编译成.class时能够识别为同一字符串的,自动优化成常量,引用自同一String对象.
在运行时创建的字符串具有独立的内存地址,所以不引用自同一String对象.
-----
[2015-08-26]
作者:梦工厂
链接:https://www.jianshu.com/p/c7f47de2ee80
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。