java面试(进阶五篇)解答
题目来自于网络,答案是笔者整理的。仅供参考,欢迎指正
来源: https://mp.weixin.qq.com/s?__biz=MzI1NDQ3MjQxNA==&mid=2247485897&idx=1&sn=25f71098bd5421722db2511730eb8f50&chksm=e9c5f078deb2796e2dd7759f69e6411040b23a6bbf52858bcffe9fdfb6dee565591f3af66f82&scene=38&key=cf3fe9b79f0039bf69268b0540b67e011bfd70fe16f76fc783ed4e03c426be52c1f0a8ba23b8145b3bc3814a3443959df592edd1a50043f5faa70186e5313a84d03fe9dac595abfdb8fd783ebfdb3e1f&ascene=7&uin=MjM2OTQ3MDkzOQ%3D%3D&devicetype=Windows+7&version=6206021b&lang=zh_CN&pass_ticket=h97v%2FevjbeMS22Cec6mLcTFMVU17Iq0u%2FWtXpCY668m3AU7lLNOkKa9JdWj%2B8omE&winzoom=1
一、Java相关
-
乐观悲观锁的设计,如何保证原子性,解决的问题;
-
char和double的字节,以及在内存的分布是怎样;
-
对象内存布局,然后讲下对象的死亡过程?
-
对象头,详细讲下;
-
sync原理详细,sync内抛异常会怎样,死锁吗?还是释放掉?怎么排查死锁?死锁会怎样?有没有什么更好的替代方案?
-
详细讲一下集合,HashSet源码,HashMap源码,如果要线程安全需要怎么做?
-
多线程是解决什么问题的?线程池解决什么问题?
-
线程池,如何设计的,里面的参数有多少种,里面的工作队列和线程队列是怎样的结构,如果给你,怎样设计线程池?
-
AQS原理,ReentranLock源码,设计原理,整体过程。
-
继续聊多线程源码,sync原理,然后一个场景设计题;
-
float f = 1.4f;double d = 1.4d; 与 float f = 1.5f;double d = 1.5d; 是否为true,内存是怎样的;
-
split的源码,split("a|b|c");得出多少个数组;
-
把所有认识熟用的JUC( java.util.concurrent(简称JUC)包)下的类写出来,讲下使用,然后讲下原生的线程操作;
-
开闭原则,解析工厂方法模式,建造者模式,区别。手撸出来。
-
讲下JVM的大页模式,JVM内存模型;
-
什么是敏捷开发,防御性编程,并行编程。Team Leader的思考;
-
逃逸分析是什么,作用是什么,用途是什么;
-
怎么认为一个类是线程安全?线程安全的定义是什么?Java有多少个关键字进行同步?为什么这样设计?(聊了一大堆,一堆为什么);
-
两个线程设计题。记得一个是:t1,t2,t3,让t1,t2执行完才执行t3,原生实现。
-
写个后缀表达式,为什么要设计后缀表达式,有什么好处?然后写下中缀。
-
我看你做过性能优化,比如你怎么分析项目里面的OOM的,内存泄露呢?详细说思路;
-
说下多线程,我们什么时候需要分析线程数,怎么分析,分析什么因素;
-
抽象方法和类方法的区别,static的抽象方法可以吗?
-
说下Java的克隆体系;
-
涉及OOM、JVM优化、源码问题、数据库优化、多线程等问题;
-
CPU高?什么情况CPU高?解决什么问题?
-
你有遇到过临界区问题吗?有遇到过吗?你在项目遇到这个问题是怎样解决的?
-
volatile关键字作用;
-
Java的多态怎么实现;
-
解释一下自旋;
-
解释一下信号量;
-
什么情况下会触发类加载;
-
Java内存抖动严重,优化的思路;
二、数据库相关
-
SQL优化思路,联合索引与底层树结构的映像关系,索引结构(B+、B-),为什么用这样的结构;
-
讲下MySQL的集群?集群遇到过什么问题?sql的优化?
-
你目前为止遇到的最大数据量是多少?知道100万时候怎么设计吗?1000万呢?过几十亿呢?
-
MySQL有多少个参数可调,除了最大连接数。全部列出来,一个个分析。
-
聊下优化过的索引,怎么优化;
-
红黑树和平衡树的区别,为什么数据库不用红黑树;
-
mysql有哪些锁,意向锁有什么用;
-
数据库高并发下的优化思路;
-
数据库什么情况下索引会失效;
三、数据结构和操作系统相关
-
数据结构学过吧,聊一下?学过什么结构?讲下树和队列?B树呢?
-
操作系统学过吧,聊一下?讲一下系统内存是怎样的?分段分页虚拟内存?
-
页面置换算法呢?多少种?有最优的置换算法吗?
-
你学过什么课程?然后聊下操作系统,内核、用户之类。
-
反转链表手撸;
-
快排,给一串数组,把具体每次patition写下,最终结果也写45, 32, 41, 35, 38, 20, 50;
-
一个整数status, 判断第K个比特位是否为比特1;
-
把递归实现的快排改成非递归,你知道非递归有什么好处吗;
-
举例使用分治思想的算法;
四、网络相关
-
讲下请求头细节?
-
Http和Https?Http1.0,1.1,2.0,讲下长连接和短连接?Https是怎样的?如果我篡改了公钥呢?怎么防止?
-
Get和Post,讲下区别,要我模拟出抓包来。
-
详细讲下Cookie和Session,Token,OAuth2.0协议;
-
拥塞算法知道吗?哪些,分别怎样?
-
学过计算机网络是吧?socket熟悉吗?对它的读写缓冲区有理解吗?怎么的?那滑动窗口是怎样的?为什么这样设计?
-
再聊下Http的Http basic authentication;
-
Https的过程;
五、框架相关
-
聊下Spring源码,知道多少,都聊一下;
-
聊下Spring注解,@Autowire,@Resource,以及他们的解析过程;
-
聊一下架构,接入层架构,服务层架构。聊下技术栈,Spring Boot,Spring Cloud、Docker;
-
Spring ioc的具体优势,和直接New一个对象有什么区别;
-
Servlet生命周期,是否单例,为什么是单例;
-
Spring Mvc初始化过程;
五、分布式相关
-
多少种RPC框架?
-
一致性哈希是干嘛的?
-
搭建高并发高可用系统需要怎样设计?考虑哪些东西,有多少说多少。
-
你对缓存有什么理解?缓存是解决什么问题?后端缓存有哪些,分别解决什么问题?
-
聊一下分布式锁;
-
你是怎么设计系统缓存的,为什么,什么场景;
-
也来说下,削峰的多种实现,Redis?MQ?
-
为什么用mq就能削峰?解决什么问题?
六、设计题
-
有几台机器存储着几亿淘宝搜索日志,你只有一台2g的电脑,怎么选出搜索热度最高的十个搜索关键词;
-
如何设计算法压缩一段URL;
-
有一个页面能同时展示两个广告,现在有五个广告,设计算法使五个广告展示概率为1:2:3:4:5;
-
有25匹马,五个赛道,用最少比赛次数将25匹马排序;
七、其他相关
-
Tomcat缓存,聊下缓存的整体理解,知道多少种缓存;
-
解释下Mucene原理,倒排索引,怎样进行中文分词,基于什么进行分词;
-
TopN的大数据量题;
-
你对接入层要思考什么东西?遇到过哪些问题?搭建系统要考量哪些因素?
-
然后项目问题,优化问题;
-
熟悉maven是吧?我们来聊下Maven的源码原理,Maven冲突的时候,怎么选择依赖包,我们怎么查,我们遇到两个不一样的版本,我们应该如何去选择,为什么?
-
项目如何分组,性能优化小组应该做哪些;
-
我们来说下接入层的搭建,认知分析;
-
问下项目的系统构建,思考,为什么这样构建?
-
如何判断一段代码的好坏;
参考答案
一、Java相关
1.乐观悲观锁的设计,如何保证原子性,解决的问题;
悲观锁:总是假设最坏的情况,每次拿数据的时候都会以为别人会修改数据,所以拿数据时会上锁。java中synchronized就是一个悲观锁的实现
乐观锁:每次拿数据的时候并不会上锁,但是会在更新的时候判断是否已经有别人已经更新数据。乐观锁适用于多读的情况,这样可以提高吞吐量。java.util.concurrent.atomic包下的原子变量类就是使用了乐观锁的一种方式(CAS)
2.char和double的字节,以及在内存的分布是怎样
char:1byte
double:8byte
char和double都是基本类型,所以并不会像对象类型那样,有对象头和对其填充,所以在内存中也是占用1byte和8byte
3.对象内存布局,然后讲下对象的死亡过程
对象在内存中的布局主要分为三个块:
* 对象头(header)
* MarkWord(存储对象自身的运行时数据,如:哈希码、GC年龄分代、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等。32和64位虚拟机分别使用32和64个bit)
* 类型指针(对象指向它的类的元数据的指针,JVM通过这个指针来确定这个对象是哪个类的实例)
* 实例数据(instance data)
* 对齐填充(padding)
对象的死亡过程:
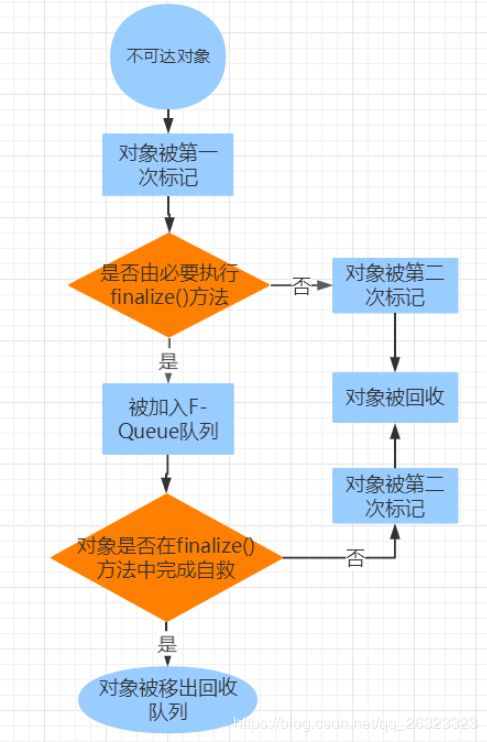
4.对象头,详细讲下
对象头包括两部分:
* MarkWord(主要是对象运行时的自身数据,哈希码、线程持有的锁等信息)
* 类型指针(指向对象所属类元数据的指针)
5.sync原理详细,sync内抛异常会怎样,死锁吗?还是释放掉?怎么排查死锁?死锁会怎样?有没有什么更好的替代方案
* Monitor:是一个同步工具,相当于操作系统中的互斥量(mutex),即值为1的信号量。它内置于每个Object中,相当于一个许可证,拿到许可证即可操作,没有则需要阻塞等待
* synchronized原理:
synchronized的同步代码块在字节码引擎中执行时,其实是通过锁对象的monitor的使用与释放来实现的。
由于一个对象的monitor是唯一的,所以未获取对象monitor的线程需要阻塞等待。
sync抛异常会释放掉锁;
排查死锁可以通过jstack pid来查看栈信息,死锁线程会展示为dead lock;
更好的替代方案是:可以使用ReentrantLock.tryLock等方法
6.详细讲一下集合,HashSet源码,HashMap源码,如果要线程安全需要怎么做
源码可参考之前的解答方案
线程安全需要:采用HashTable获取ConcurrentHashMap;CopyOnWriteArraySet等线程安全类
7.多线程是解决什么问题的?线程池解决什么问题?
多线程:在单线程情况下(也就是只有main线程执行),任务是顺序执行的,执行效率较低,无法利用CPU多核特性;如果一个任务发生阻塞,其他任务都无法执行;使用多线程执行的时候,可以充分利用CPU多核的特性,将任务执行变成并行的,执行效率更高
线程池:线程的创建和销毁是需要操作系统配合的高级操作,是一种高开销的操作。所以我们使用线程池来回收已经使用完成的线程,合理利用线程资源
8.线程池,如何设计的,里面的参数有多少种,里面的工作队列和线程队列是怎样的结构,如果给你,怎样设计线程池?
有关于ThreadPoolExecutor的构造方法如下:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
RejectedExecutionHandler handler) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), handler);
} * Executors.newSingleThreadExecutor() 工作队列:LinkedBlockingQueue
* Executors.newCacheThreadPool() 工作队列:SynchronousQueue ,线程池线程数量>corePoolSize,若线程有60秒的空闲时间,超过这个时间则回收
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
} * Executors.newFixedThreadPool() 工作队列:LinkedBlockingQueue
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
} * Executors.newScheduledThreadPool() 工作队列:DelayWorkQueue,
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}9.AQS原理,ReentranLock源码,设计原理,整体过程
具体可参考:https://www.cnblogs.com/chengxiao/p/7141160.html
10.继续聊多线程源码,sync原理,然后一个场景设计题
参考5
11.float f = 1.4f;double d = 1.4d; 与 float f = 1.5f;double d = 1.5d; 是否为true,内存是怎样的;
不明白什么叫是否为true;
由于是基本类型,float占用4byte,double占用8byte
12.split的源码,split("a|b|c");得出多少个数组
?
13.把所有认识熟用的JUC( java.util.concurrent(简称JUC)包)下的类写出来,讲下使用,然后讲下原生的线程操作
并发类:
Executors
CountDownLatch
CyclicBarrier
ReentrantLock
ReentrantReadWriteLock
原子类:
AtomicBoolean
AtomicInteger
AtomicIntegerArray
AtomicLong
AtomicLongArray
AtomicReference
容器类:
ArrayBlockingQueue
CopyOnWriteArrayList
LinkedBlockingQueue
LinkedBlockingDeque
CopyOnWriteArraySet
ConcurrentSkipListSet
ConcurrentHashMap
ConcurrentSkipListMap
14.开闭原则,解析工厂方法模式,建造者模式,区别。手撸出来
开闭原则:对扩展开放,对修改关闭
15.讲下JVM的大页模式,JVM内存模型
JVM内存模型:
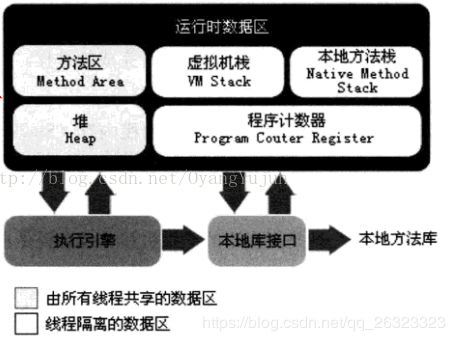
JVM大页模式 具体可参考:https://blog.csdn.net/zero__007/article/details/52926366
16.什么是敏捷开发,防御性编程,并行编程。Team Leader的思考
敏捷开发:https://www.sohu.com/a/157053455_590354
防御性编程:https://www.cnblogs.com/bakari/archive/2012/08/27/2658215.html
并行编程:
17.逃逸分析是什么,作用是什么,用途是什么
逃逸分析是目前JVM中比较前沿的优化技术
逃逸分析的基本行为就是分析对象动态作用域:
* 当一个对象在方法中被定义后,他有可能被外部方法所引用,例如作为调用参数传递到其他地方中,称为方法逃逸
* 甚至有可能被外部线程访问到,比如赋值给类变量或可以在其他线程中访问的实例变量,称为线程逃逸
如果证明一个对象不会逃逸到方法或线程外,则可以为这个变量进行一些高效优化,优化方案如下:
* 栈上分配(把方法中的变量和对象分配到栈上,方法执行完之后自动销毁,不需要垃圾回收的介入,从而提高系统性能)
* 同步消除(线程对象同步本身比较消耗,如果确定一个线程不会被其他线程访问到,那么该对象的读写就不会存在竞争,对这个变量的同步措施就可以取消掉)
* 标量替换(JVM中的原始数据类型都不能再进一步分解,它们被称为标量;如果一个数据可以继续分解,那它称为聚合量,对象就是聚合量。如果逃逸分析证明一个对象不会被外部访问并且这个对象是可分解的,那程序真正执行的时候可能不会创建这个对象,而是直接创建它的若干个被这个方法访问到的成员变量来替代)
18.怎么认为一个类是线程安全?线程安全的定义是什么?Java有多少个关键字进行同步?为什么这样设计?
线程安全:当多个线程访问该类,这个类的方法始终表现为正确的行为,那么可称这个类线程安全
关键字:synchronized、ReentrantLock、ReentrantReadWriteLock、volatile(可见性非原子性)
19.两个线程设计题。记得一个是:t1,t2,t3,让t1,t2执行完才执行t3,原生实现
使用Thread.join方法
t1.start();
t1.join();
t2.start();
t2.join();
t3.start();
t3.join();更多线程设计题可参考: https://blog.csdn.net/qq_26323323/article/details/83750198
20.写个后缀表达式,为什么要设计后缀表达式,有什么好处?然后写下中缀
如我们正常表达式为:a+b-c
如果变成后缀表达式:ab+c-
后缀表达式的好处,就是我们在设计表达式的计算模型的时候,如果将表达式设计为后缀的,那么可以使用栈来快速的实现计算
21.我看你做过性能优化,比如你怎么分析项目里面的OOM的,内存泄露呢?详细说思路
22.说下多线程,我们什么时候需要分析线程数,怎么分析,分析什么因素
为了达到线程数最优,系统运行最优,我们需要设置线程池中线程的数量。
如果是IO密集型,则将线程数设置为:((线程等待时间+线程CPU时间)/线程CPU时间)*CPU数目
如果是CPU密集型,则将线程数设置为:CPU核数+1
23.抽象方法和类方法的区别,static的抽象方法可以吗?
抽象方法需要在子类中具体实现使用,最终还是通过对象来调用
类方法:通过类来调用,可以不通过对象调用
不可以创建static类型的抽象方法
24.说下Java的克隆体系
java的clone分为浅克隆和深克隆
浅克隆:只克隆基本类型的参数,对于对象类型的参数直接引用,而不是新创建一个对象
深克隆:相对于浅克隆而言,对于对象类型的成员变量,会创建一个新的对象,与原对象内容一致
未完待续...