ubuntu - hadoop3.2.0 使用
简单说明
hadoop2.x版本和hadoop3.x版本在端口上有一些不一样,在阅读官方文档的时候要注意你现在使用的是哪个版本的文档。同时官网默认打开的是2.9.x版本的文档。可以到下载的子菜单下面查询版本对应的文档

官网说明文档连接
安装JAVA-JDK
我这里是直接在内网的一台linux服务器上进行的操作。系统是ubuntu
hadoop是运行在jvm中的,我们需要安装java jdk
sudo add-apt-repository ppa:openjdk-r/ppa
sudo apt-get update
sudo apt-get install openjdk-8-jdk
sudo update-alternatives --config java
sudo update-alternatives --config javac
安装完之后,我们可以使用java -version 查询一下安装是否成功。
部署3.2.0版本的hadoop
# 首先获取到hadoop3.2.0的安装包
wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.0/hadoop-3.2.0.tar.gz
# 解压安装包
tar zxvf xx.tar -C hadoop/
安装完之后我们立马进入来hadoop的文件目录中

我们进入到etc/hadoop的目录中。首先在hadoop-env.sh中配置java的安装目录

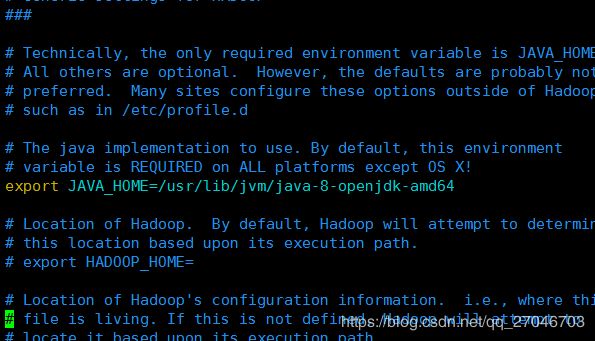
# 查询java jdk的安装目录
whereis java
# 返回目录一步步查询
ls -lrt /usr/bin/java
# 上步得到是一个软件了,继续查询
ls -lrt /etc/alternatives/java
# 上步得到仍然是一个软连接,继续查询
ls -lrt /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java
# 得到最终的安装路径
/usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java
# 我们只需要配置到根路径就可以了。
配置core-site.xml和hdfs-site.xml
这里运行的是伪集群的方案,直接参考官网的配置即可。
core-site.xml 的配置:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml 的配置
dfs.replication
1
配置ssh登录
我的电脑远程ssh是需要输入密码的,所以我在本地配置了一下秘钥。
# 切换到ssh目录:
cd ~/.ssh/
# 生成秘钥
ssh-keygen -t rsa -P ""
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
启动hadoop
# 格式化目录 默认在/tem/hadoop-root/
bin/hdfs namenode -format
# 运行启动脚本
sbin/start-dfs.sh
用户未定义异常
在/hadoop/sbin路径下:
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
start-yarn.sh,stop-yarn.sh顶部也需添加以下
YARN_RESOURCEMANAGER_USER=root
HDFS_DATANODE_SECURE_USER=yarn
YARN_NODEMANAGER_USER=root
注意一个配置属性,版本不同名称不同
版本>3.0 , HDFS_DATANODE_SECURE_USER , 版本<3.0 HADOOP_SECURE_DN_USER
到这里不出意外hadoop就运行成功了,在根目录下会生成一个logs的文件夹,里面是运行的日志,我们可以进去看看。同时我们可以通过浏览器访问 http://ip:9870端口来获取一个便于查看运行状况的网页。
祸不单行,出了问题咋办
因为我的测试服务器里面跑了一些测试服务,端口会被占用,启动的时候通过日志发现hadoop因为端口占用起不来,在官网找了一圈最后才发现在角落里的配置文件说明。包括上一步的默认格式化目录也可以修改。

我这里就我的问题进行一下演示,我这里的问题是我运行环境的9870端口已经被占用了,我只能换一个端口才能启动。并且这个信息我是通过log日志得知的。通过jps你可以快速得知hadoop有没有启动成功,成功需要启动三个节点 DataNode,SecondaryNameNode,NameNode。 哪个节点没启动就看哪个节点的日志。
我们先看看官方怎么说

我们发现了是这个配置。那我们可以对这个配置进行一下修改,我看的是hdfs的配置,所以对hdfs-site.xml进行修改

可以看到我这里对绑定的ip和绑定的port进行了重新配置。接着重新进行启动hadoop节点的步骤。大功告成,附上结果图

分布式配置
hadoop 分布式配置。 这里我用两台机器进行简单的使用,master机器(内网ip 172.16.10.2) slave机器(内网ip 172.16.10.1)。
配置两台机器免密登录
查看上面配置SSH登录的过程,在slave机器上也执行一样的操作。生成好之后 查看authorized_keys里面的内容,把slave的authorized_keys内容一下,粘贴到master的authorized_keys配置中。 同时master的的authorized_keys配置也拷贝到slave中。保证两台机器互相登录不需要密码。
配置slave机器
和master节点的安装配置差不多。我们先按照上面的文章再配置一个新节点。接着我们对master和slave的配置文件的修改。这里以master的配置文件为例子(slave也是一样的配置)。
主要修改 hdfs-site.xml,core-site.xml,mapred-site.xml , yarn-site.xml 四个文件
hdfs-site.xml
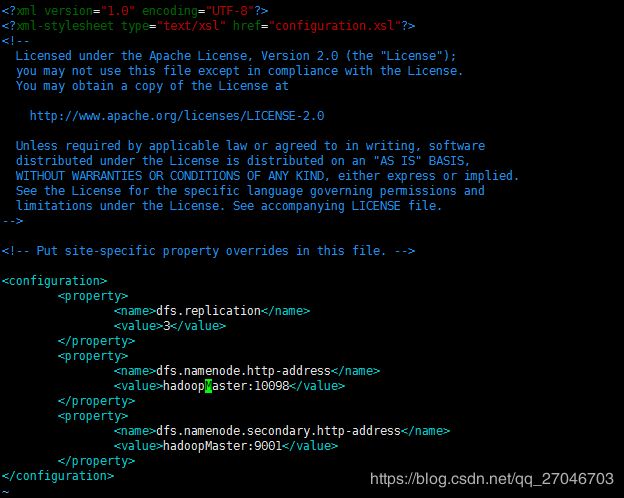
这里的hadoopMaster = 172.16.10.2 hadoopSlave=172.16.10.1,dfs.replication 表示datanode节点的个数,这里只有1个,但是我懒得改了,默认值是3。
core-site.xml
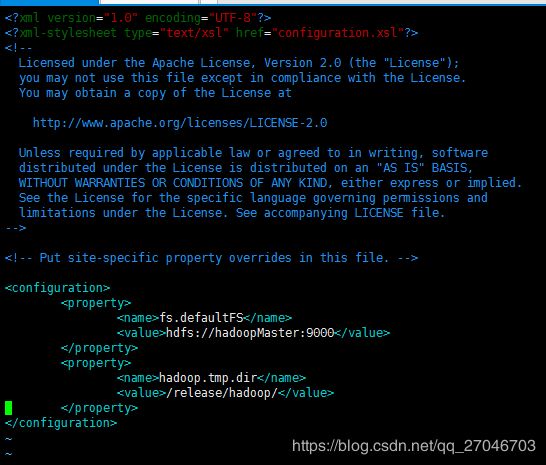
hadoop.tmp.dir 这个属性指的是生成文件的目录。默认是tmp/hadoop-root/ 因为tmp目录是临时目录,所以我把生成的文件路径改了一下。
mapred-site.xml
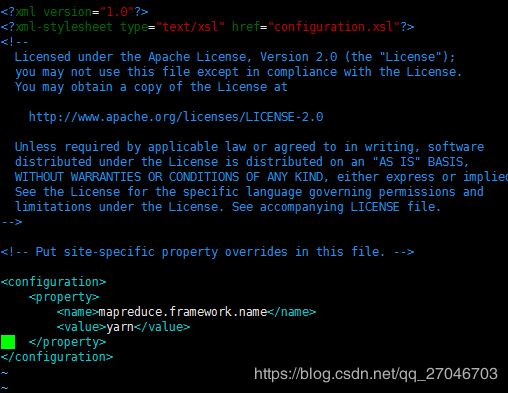
yarn-site.xml

yarn.resourcemanager.hostname, 资源管理器的主机路径。
yarn.resourcemanager.webapp.address , 这是一个查询资源管理的web页面。
yarn.log-aggregation-enable 大概意思是收集每个节点的聚合日志,并且转移到hdfs的文件系统上。
开启关闭
# 格式化
bin/hdfs namenode -format
# 开启,这类似一个命令的封装,一个命令里面调用了其他多个命令
sbin/start-all.sh
# 关闭,
sbin/stop-all.sh
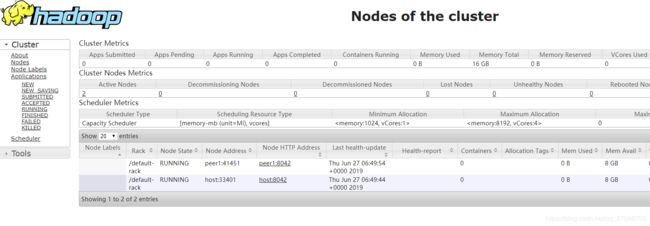
web页面观察情况
# 节点数据信息
http://172.16.10.2:10098/
# 分布式节点健康信息
http://172.16.10.2:8088/
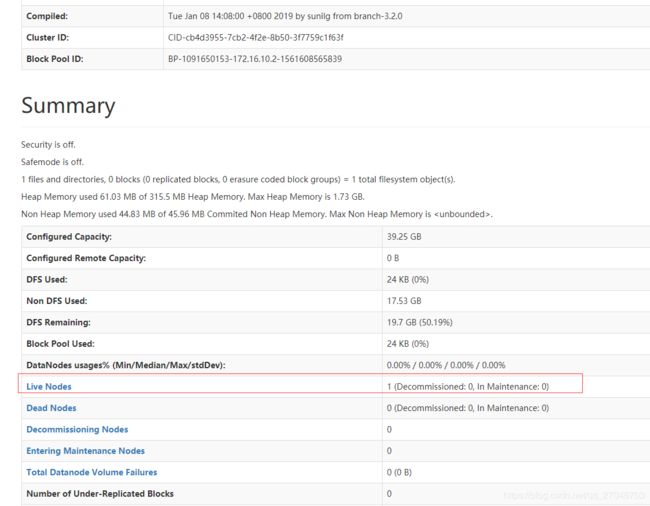
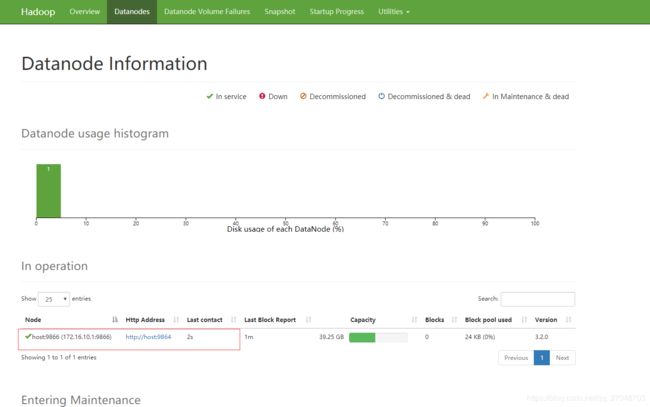
下面这个是分布式节点的信息,这个页面看起来还有很多地方可以调整,应该通过配置参数可以修改显示的内容。具体需要查一下文档做一下测试然后再后续更新分享