Apache Kylin查询性能优化
更多干货
- 分布式实战(干货)
- spring cloud 实战(干货)
- mybatis 实战(干货)
- spring boot 实战(干货)
- React 入门实战(干货)
- 构建中小型互联网企业架构(干货)
- python 学习持续更新
- ElasticSearch 笔记
- kafka storm 实战 (干货)
Apache Kylin查询性能优化
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区,可在亚秒内查询巨大的Hive表。
在Apache Kylin的实际部署过程中,SQL查询有时并不能如预期在很短的时间内完成,需要开发人员进行有针对性的分析和优化。
在进行分析、优化之前,我们需要先了解Apache Kylin查询的整个生命周期。这一周期主要分为三个阶段:第一阶段的SQL解析阶段,第二阶段的SQL查询阶段,以及第三阶段的数据集中和聚合阶段。接下来,我们将分阶段为大家解析应如何分析和优化Apache Kylin的查询性能。

第一阶段:SQL解析
在收到SQL请求后,Kylin Query Server会调用Calcite对SQL语句进行解析,Calcite的工作流程如下图。
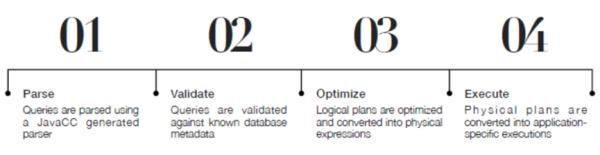
首先,Calcite会将SQL语句通过范式编译器解析为一颗抽象语义树(AST)。
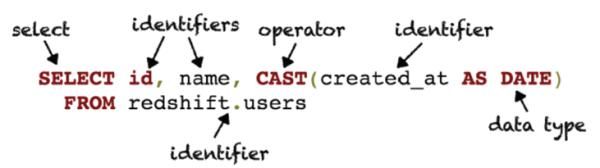
然后Calcite对这棵AST树进行优化,将Project(select部分)和Filter(where部分)Push down至Hadoop集群。

接着定义implement plan,共有两种方式:HepPlanner(启发式优化)和VolcanoPlanner(基于代价的优化)。目前Kylin只启用了一些必要的HepPlanner规则,大部分使用的是VolcanoPlanner。
第二阶段:SQL查询
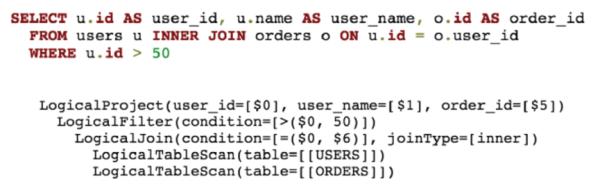
针对子查询,UNION等场景,Calcite将SQL分解为多个OLAPContext,同时执行Filter Pushdown和Limit Pushdown等优化手段,然后提交到HBase上执行。
第三阶段:数据集中和聚合
HBase上的查询任务执行完成后,数据返回至Kylin Query Server端,由Calcite聚合多个OLAP Context的查询结果后,最后返回给前端BI。在了解Apache Kylin的查询生命周期以后,碰到一些查询速度较慢的情况,就能够有针对性地进行分析和优化了。
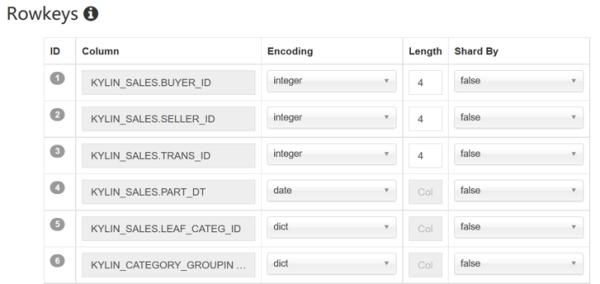
1、从模型设计角度,需要合理调整RowKey中维度的排列顺序,原则是把过滤字段(例如PART_DT等日期型字段)和高基维(例如BUYER_ID,SELLER_ID等客户字段)放在Rowkey的前列,这样能够显著提升【第二阶段SQL查询】在HBase上数据扫描和I/O读取的效率。
2、Kylin遵循的是“Scatter and gather”模式,而有的时候在【第二阶段SQL查询】时无法实现Filter Pushdown和Limit Pushdown等优化手段,需要等待数据集中返回Kylin后再筛选数据,这样数据吞吐量会很大,影响查询性能。优化方法是重写SQL语句。
例如,该SQL查询的筛选条件(斜体加粗部分)放在子查询中,因此无法实现Filter Pushdown。
select KYLIN_SALES.PART_DT, sum(KYLIN_SALES.PRICE)from KYLIN_SALESinner join (select ACCOUNT_ID, ACCOUNT_BUYER_LEVEL from KYLIN_ACCOUNT whereACCOUNT_COUNTRY = 'US' ) as TTon KYLIN_SALES.BUYER_ID = TT.ACCOUNT_IDgroup by KYLIN_SALES.PART_DT
正确的写法应该是:
select KYLIN_SALES.PART_DT, sum(KYLIN_SALES.PRICE)from KYLIN_SALESinner join KYLIN_ACCOUNT as TT on KYLIN_SALES.BUYER_ID = TT.ACCOUNT_IDwhere TT.ACCOUNT_COUNTRY = 'US'group by KYLIN_SALES.PART_DT
如下图所示,可以在日志中查看Filter Pushdown是否成功。
![]()
3、查看后台日志,如果查询击中了Base Cuboid,则【第三阶段数据集中和聚合】将会花费大量时间,优化方法是调整模型中聚合组,联合维度,必要维度的设计。
相关优化方法可以参考以下技术文章:
Apache Kylin高级设置:聚合组(Aggregation Group)原理解析
Apache Kylin高级设置:联合维度(Joint Dimension)原理解析
Apache Kylin高级设置:必要维度 (Mandatory Dimension)原理解析
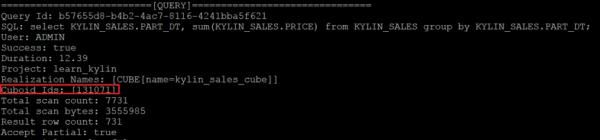
在日志中可以看到查询击中的Cuboid组合,如下图红框中的131071,将其转换为二进制数值是0x1 1111 1111 1111 1111,从右至左,共有17个1,表示该Cuboid中包含了17个维度(这里从右至左指代的维度的对应顺序是Cube模型中Rowkey中自下而上定义的维度),而Cube模型中所有维度的数量是17,说明击中了Base Cuboid。
4、从Kylin Query Server处理效率角度,需要实时监控Kylin节点的CPU占有率和内存消耗,如果两者很高的话可能导致【第一阶段SQL解析】的效率下降,优化方法是增加Kylin节点CPU和JVM配置。
具体方法是修改setenv.sh中的KYLIN_JVM_SETTINGS配置项。
![]()
5、监控BI前端,Kylin Query Server节点和Hadoop集群之间的网络通信状态,大数据集传输可能引起网络堵塞,尤其是在多并发查询的情况下更容易发生网络堵塞,进而对查询性能产生显著影响。优化方法是确保BI前端、Kylin节点、Hadoop集群之间的网络通畅,一个简单的方法是用PING命令查看网络之间的延迟。
6、对于一些复杂的SQL语句,如果包含子查询的话,尽量避免Left Join操作,尤其是Join的两个数据集都较大的情况下,会对查询性能有显著的影响。建议将SQL的数据处理逻辑放在ETL阶段,而前端SQL逻辑保持简单明了。