DAGScheduler详解
文章目录
- 概述
- 基本概念
- 主要功能
- DAGScheduler类说明
- Job的提交
- stage的划分与提交
- stage的划分
- 创建ResultStage
- 获取或创建父Stage列表
- 获取RDD的所有shuffle依赖列表
- 获取或创建ShuffleMapStage列表
- 获取缺失的祖先Shuffle依赖列表
- stage的提交
- 提交ResultStage
- 获取stage所有未提交的父Stage列表
- 提交未计算的Task集合
- 将Stage标记为已完成
- 提交所有子stage
- 参考文章
概述
在spark中调度器(Scheduler)有两种:
- TaskScheduler(低级的调度器接口):负责实际每个具体Task的物理调度执行。
- DAGScheduler(高级的调度器接口):负责将Task拆分成不同Stage的具有依赖关系(包含RDD的依赖关系)的多批任务,然后提交给TaskScheduler进行具体处理。
DAGScheduler会根据各个RDD之间的依赖关系形成一个DAG,并根据ShuffleDependency来进行stage的划分。stage包含多个tasks,个数由该stage的finalRDD决定,stage里面的task完全相同。DAGScheduler完成stage的划分后基于每个Stage生成TaskSet,并提交给TaskScheduler。TaskScheduler负责具体的task的调度,在Executor上启动执行task。

基本概念
- Job:提交给调度器的顶层工作组件,一次RDD Action生成的一个或多个Stage所组成的一次计算作业。举例说明,当用户调用一个action操作,如count,则一个Job会通过submitJob方式被提交。每个Job可能需要执行多个stage来生成中间和结果数据。
- Stage:用来计算Job中间和结果数据的tasks的集合,其中每个task在同一个RDD的不同partition上执行同样的函数。Stages是在shuffle边缘被分离,这会产生一个依赖等待(即必须等待前一个stage完成后才能拉取其输出数据)。有两种类型的stages:ResultStage是执行一个action操作的最后的一个stage,用来生成最终结果;而ShuffleMapStage会为一个shuffle操作生成map输出文件,即中间数据。当这些jobs重用同一个RDD,则Stages会在多个jobs间共享。
- Task:在集群上运行的基本单位。一个Task负责处理RDD的一个partition。RDD的多个patition会分别由同一个TaskSet的不同Task去处理。Tasks是独立工作的单元,每个将会被发送到一台机器上执行。
- TaskSet任务集:一组关联的,但是互相之间没有Shuffle依赖关系的任务所组成的任务集,一个stage对应生成一个TaskSet任务集。
- Cache跟踪:DAGScheduler找到哪些RDDs已经被cache了来避免重计算它们,而且同样地记住哪些ShuffleMapStages已经生成了输出文件来避免重建一个shuffle的map侧计算任务。
- Preferred locations:优化的任务计算位置,DAGScheduler同样基于潜在RDDs的最优化位置,或缓存及shuffle数据的位置,来计算在哪里执行stage中的每个task。
- Cleanup:所有数据结构会被清除当依赖于它们运行的jobs完成后,以防止在一个长期运行的应用中内存泄漏。
主要功能
- 接收用户提交的job;
- 将job划分为不同stage的DAG图,记录哪些RDD、Stage被物化存储,并在每一个stage内产生一系列的task,并封装成TaskSet;
- 结合当前的缓存情况,决定每个Task的最佳位置(移动计算而不是移动数据,任务在数据所在的节点上运行),将TaskSet提交给TaskScheduler;
- 重新提交Shuffle输出丢失的Stage给TaskScheduler(不是由shuffle输出丢失造成的Stage内部的错误,DAGScheduler是不管的,由TaskScheduler负责尝试重新提交task执行);
DAGScheduler类说明
SparkContext中创建DAGScheduler的代码如下,创建DAGScheduler时将SparkContext自身的引用传递进去了。
// 为什么用volatile修饰?并行提交job时,保持多线程内的可见性?
@volatile private var _dagScheduler: DAGScheduler = _
_dagScheduler = new DAGScheduler(this)
由DAGScheduler类定义可以看出DAGScheduler持有了SparkContext,TaskScheduler以及MapOutTrackerMaster和BlockManagerMaster等。DAGScheduler的数据结构主要维护jobId和stageId的关系、Stage、ActiveJob,以及缓存的RDD的partitions的位置信息等。
private[spark] class DAGScheduler(
private[scheduler] val sc: SparkContext,
private[scheduler] val taskScheduler: TaskScheduler,
listenerBus: LiveListenerBus,
mapOutputTracker: MapOutputTrackerMaster,
blockManagerMaster: BlockManagerMaster,
env: SparkEnv,
clock: Clock = new SystemClock())
extends Logging {
// 用于生成jobId(taskId是在taskschedulerImpl中生成,shuffleId和RddId在SparkContext中生成)
private[scheduler] val nextJobId = new AtomicInteger(0)
// 生成stageId
private val nextStageId = new AtomicInteger(0)
// jobid到Stage id集合的映射
private[scheduler] val jobIdToStageIds = new HashMap[Int, HashSet[Int]]
// StageId到stage的映射
private[scheduler] val stageIdToStage = new HashMap[Int, Stage]
/**
* 来自shuffle dependency ID到ShuffleMapStage的映射,将会生成对应依赖的数据。只包含当前运行job部分的
* stage(当jobs要求的shuffle stage完成后,这个映射将会被移除,并且这个shuffle数据的唯一记录将会
* 被放在MapOutputTracker中)。
*/
private[scheduler] val shuffleIdToMapStage = new HashMap[Int, ShuffleMapStage]
// jobId对应的ActiveJob(正在运行的job)集合
private[scheduler] val jobIdToActiveJob = new HashMap[Int, ActiveJob]
// 需要运行的Stage的集合,依赖stage还没有完成的stage集合
private[scheduler] val waitingStages = new HashSet[Stage]
// 正在运行的Stage集合
private[scheduler] val runningStages = new HashSet[Stage]
// 由于拉取数据失败而需要重新提交的stage集合
private[scheduler] val failedStages = new HashSet[Stage]
private[scheduler] val activeJobs = new HashSet[ActiveJob]
// 包含每个RDD的partitions被缓存的位置。
// 这个映射的key是RDD的id,而它的value是用partition分区值索引的数组。
// 数组的每个值是缓存的RDD分区partition的位置集合。
// 所以访问这个映射的操作应该被用synchronizing进行监控(具体查看问题SPARK-4454)。
private val cacheLocs = new HashMap[Int, IndexedSeq[Seq[TaskLocation]]]
// 为了跟踪记录失败的结点,我们使用MapOutputTracker的时间值,它和每个task一起发送。
// 当我们检测到一个结点失败,我们记录下当前的时间值和失败的executor,为新tasks增加它的值,并利用它来忽视
// 丢失的ShuffleMapTask的结果。
// TODO: 关于失败时间点的垃圾收集信息,当我们知道没有更多的丢失的消息需要被检测。
private val failedEpoch = new HashMap[String, Long]
// 是一个典型的生产者和消费者模式,提供事件的缓冲与异步处理
// 为什么不在dagscheduler中直接生成缓冲队列?因为用一个EventLoop抽象类定义缓冲队列
// 的模板,而在子类中具体实现onReceive方法,实现具体的实现,这样可扩展性强
// 这样就不用在想扩展事件处理方法时去继承DAGScheduler类,更加灵活方便
// 事件处理框架对象,监听发现有事件发生时,取出事件并调用相应的事件处理函数进行处理。
private[scheduler] val eventProcessLoop = new DAGSchedulerEventProcessLoop(this)
taskScheduler.setDAGScheduler(this)
Job的提交
以RDD.count的action为例,job提交的整个函数调用如下:
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum
DAGScheduler#runJob
DAGScheduler#submitJob
eventProcessLoop.post(JobSubmitted(**))
eventQueue.put
eventProcessLoop#onReceive
dagScheduler.handleJobSubmitted
其中eventProcessLoop是一个DAGSchedulerEventProcessLoop(this)对象,循环接收处理DAGScheduler的消息事件,可以把它理解成DAGScheduler的对外的功能接口。它对外隐藏了自己内部实现的细节。无论是内部还是外部消息,DAGScheduler可以共用同一消息处理代码,逻辑清晰,处理方式统一。eventProcessLoop接收各种消息并进行处理,处理的逻辑在其doOnReceive方法中:
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
case MapStageSubmitted(jobId, dependency, callSite, listener, properties) =>
dagScheduler.handleMapStageSubmitted(jobId, dependency, callSite, listener, properties)
......
}
当提交的是JobSubmitted,便会通过dagScheduler.handleJobSubmitted处理此事件,进行stage的划分。
stage的划分与提交
Spark的stages是以shuffle为边界切分RDD图来创建的。具有窄依赖(例:map(),filter())的操作会在对应Stage的一系列任务中管道式的运行,但是具有宽依赖的操作则需要多个Stage。最后所有的Stage之间将只有shuffle依赖关系。
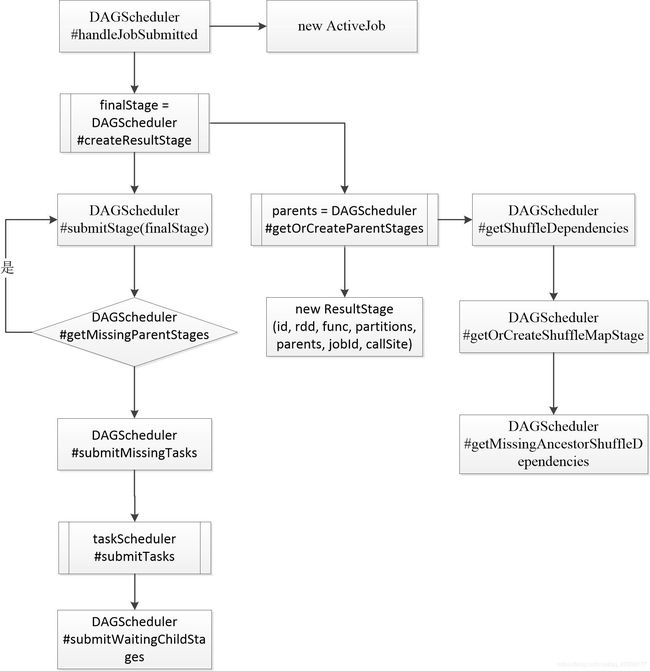
DAGScheduler中的handleJobSubmitted方法的主要功能代码如下,主要完成了两件事情:
-
创建ResultStage,即完成stage的划分;
-
submitStage(finalStage),stage的提交;
private[scheduler] def handleJobSubmitted(jobId: Int, finalRDD: RDD[_], func: (TaskContext, Iterator[_]) => _, partitions: Array[Int], callSite: CallSite, listener: JobListener, properties: Properties) { // Stage划分过程是从最后一个Stage开始往前执行的,最后一个Stage的类型是ResultStage finalStage = newResultStage(finalRDD, func, partitions, jobId, callSite) // 为此job生成一个ActiveJob对象 val job = new ActiveJob(jobId, finalStage, callSite, listener, properties) // 向LiveListenerBus发送Job提交事件 listenerBus.post( SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties)) submitStage(finalStage) //提交Stage }
stage的划分
创建ResultStage
创建finalStage,即ResultStage。下面是newResultStage的代码,可以发现创建ResultStage之前需要获取所有父Stage的列表,然后在创建ResultStage时将父stage的列表传入,从而形成整个stage依赖的DAG图。
DAGScheduler#createResultStage
private def createResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
val parents = getOrCreateParentStages(rdd, jobId)
val id = nextStageId.getAndIncrement()
val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)
stageIdToStage(id) = stage // 将Stage和stage id关联
updateJobIdStageIdMaps(jobId, stage) // 更新job所包含的stage
stage
}
获取或创建父Stage列表
对于给定的RDD,获取或创建父Stage列表。从当前的RDD向前探索,找到宽依赖处划分出parentStage,并用提供的firstJobId获取或创建ShuffleMapStage。
这里不是直接创建你stage列表的原因是因为stage可能会在job间复用。当该stage已经在前面的job中创建过之后,则直接获取即可。有一个细节,传进来的jobId参数名到这里变成了firstJobId。
DAGScheduler#getOrCreateParentStages
private def getOrCreateParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
getShuffleDependencies(rdd).map { shuffleDep =>
getOrCreateShuffleMapStage(shuffleDep, firstJobId)
}.toList
}
获取RDD的所有shuffle依赖列表
根据RDD的依赖血缘图,从给定RDD开始递归向上遍历其所有父RDD,遇到窄依赖就继续往前遍历,直到找到所有RDD的第一个shuffle依赖,并返回这个shuffle依赖列表。这个功能只会返回第一个shuffle依赖,例如,如果C对B有shuffle依赖关系,B对A具有shuffle依赖关系,C对D有shuffle依赖,那对RDD C调用函数只会返回C对B和C对D的shuffle依赖列表。这里的parentStage是Stage直接依赖的父stages(其Stage也有自己的parentStage),而不是整个DAG的所有stages。
DAGScheduler#getShuffleDependencies
private[scheduler] def getShuffleDependencies(
rdd: RDD[_]): HashSet[ShuffleDependency[_, _, _]] = {
val parents = new HashSet[ShuffleDependency[_, _, _]]
val visited = new HashSet[RDD[_]]
val waitingForVisit = new Stack[RDD[_]]
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.pop()
if (!visited(toVisit)) {
visited += toVisit
toVisit.dependencies.foreach {
case shuffleDep: ShuffleDependency[_, _, _] =>
parents += shuffleDep
case dependency =>
waitingForVisit.push(dependency.rdd)
}
}
}
parents
}
获取或创建ShuffleMapStage列表
如果存在于shuffleIdToMapStage中,则获取ShuffleMapStage。否则,首先创建祖先的ShuffleMapStage,然后再创建自己的ShuffleMapStage。
DAGScheduler#getOrCreateShuffleMapStage
private def getOrCreateShuffleMapStage(
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int): ShuffleMapStage = {
shuffleIdToMapStage.get(shuffleDep.shuffleId) match {
case Some(stage) => // 若已经在shuffleIdToMapStage中存在则直接返回stage
stage
case None =>
// 不存在则获得当前shuffle缺失的父shuffle依赖列表,并创建ShuffleMapStage列表
getMissingAncestorShuffleDependencies(shuffleDep.rdd).foreach { dep =>
// 尽管getMissingAncestorShuffleDependencies方法仅返回不在shuffleIdToMapStage中的shuffle依赖,
// 但是它可能在运行到foreach循环中的特定依赖前,已经被更早依赖的创建过程添加到shuffleIdToMapStage中了。
// 更多信息可参考问题:SPARK-13902。
if (!shuffleIdToMapStage.contains(dep.shuffleId)) {
createShuffleMapStage(dep, firstJobId)
}
}
// 最后,对给定的shuffle依赖创建ShuffleMapStage
createShuffleMapStage(shuffleDep, firstJobId)
}
}
获取缺失的祖先Shuffle依赖列表
查找所有尚未在shuffleIdToMapStage中注册的祖先shuffle依赖关系。貌似和getParentStages方法很像,区别是这里获取的所有祖先Shuffle依赖,而不是直接父Shuffle依赖。
DAGScheduler#getMissingAncestorShuffleDependencies
private def getMissingAncestorShuffleDependencies(
rdd: RDD[_]): Stack[ShuffleDependency[_, _, _]] = {
val ancestors = new Stack[ShuffleDependency[_, _, _]] // 当前shuffleDependency所有的祖先shuffle依赖
val visited = new HashSet[RDD[_]]
// 我们在这里手动维护一个堆栈以防止递归访问引起的StackOverflowError。
val waitingForVisit = new Stack[RDD[_]]
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.pop()
if (!visited(toVisit)) {
visited += toVisit
getShuffleDependencies(toVisit).foreach { shuffleDep =>
// 若为shuffleDependency并且还没有在映射shuffleIdToMapStage中,则添加到ancestors
if (!shuffleIdToMapStage.contains(shuffleDep.shuffleId)) {
ancestors.push(shuffleDep)
waitingForVisit.push(shuffleDep.rdd) // 即使是shuffleDependency的rdd也要继续遍历
} // 否则,依赖和它的祖先已经被注册了。
}
}
}
ancestors
}
由finalRDD往前追溯递归生成Stage,最终生成ResultStage。至此,DAGScheduler对Stage的划分已经完成,整个Job的DAG图已经生成。
stage的提交
提交ResultStage
在DAGScheduler的handleJobSubmitted方法创建完ResultStage后,最后一步是调用submitStage提交Stage。判断当前Stage的父Stage是否完成,如果有未完成的,则递归的提交所有父Stage。如果父stage都已完成,则提交当前stage的task任务。
DAGScheduler#submitStage
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
// 如果当前job正在执行
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
// 如果当前stage还未提交,同时不在waitingStages、runningStages和failedStages中
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
// 获得所有未提交的父stage
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
// 如果不存在未提交的父stage,则提交当前stage的task任务
submitMissingTasks(stage, jobId.get)
} else {
// 如果存在未提交的父stage,则递归提交所有父stage
for (parent <- missing) {
submitStage(parent)
}
// 将当前stage添加到waitingStages中
waitingStages += stage
}
}
} else {
// 如果没有对应当前stage的活跃job,则停止依赖于当前stage的所有Job
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
获取stage所有未提交的父Stage列表
获取当前stage所有未提交的父stage列表。判断Stage有未提交父Stage的条件如下:
-
Stage的RDD分区中存在没有对应的TaskLocation序列的分区,即调用getCacheLocs方法获取不到某个分区的TaskLocation序列,说明当前Stage的某个上游ShuffleMapStage的某个分区未执行。
-
Stage的上游ShuffleMapStage不可用(即调用ShuffleMapStage的isAvailable方法返回false)
DAGScheduler#getMissingParentStages private def getMissingParentStages(stage: Stage): List[Stage] = { val missing = new HashSet[Stage] // 存储当前stage的所有父stage val visited = new HashSet[RDD[_]] // 存储访问过的RDD // 我们在这里手动维护一个堆栈以防止递归访问引起的StackOverflowError。 val waitingForVisit = new Stack[RDD[_]] // 堆栈来保存未访问过的RDD,先进后出 def visit(rdd: RDD[_]) { if (!visited(rdd)) { visited += rdd val rddHasUncachedPartitions = getCacheLocs(rdd).contains(Nil) // 如果RDD包含未cache的partitions,即其依赖数据还未生成 if (rddHasUncachedPartitions) { // 遍历RDD的依赖 for (dep <- rdd.dependencies) { dep match { // 如果是宽依赖,则获取或创建依赖RDD所在的ShuffleMapStage case shufDep: ShuffleDependency[_, _, _] => val mapStage = getOrCreateShuffleMapStage(shufDep, stage.firstJobId) if (!mapStage.isAvailable) { missing += mapStage } // 如果是窄依赖,将依赖的RDD也压入栈中,下次循环时会检查该RDD的依赖情况,直到找到宽依赖划分新的stage为止。 case narrowDep: NarrowDependency[_] => waitingForVisit.push(narrowDep.rdd) } } } } } waitingForVisit.push(stage.rdd) while (waitingForVisit.nonEmpty) { visit(waitingForVisit.pop()) } missing.toList }
提交未计算的Task集合
如果当前Stage没有不可用的父Stage时,则提交当前Stage中还未提交的Task集合。
DAGScheduler#submitMissingTasks
private def submitMissingTasks(stage: Stage, jobId: Int) {
// 首先找到要计算的partition ids的索引列表
val partitionsToCompute: Seq[Int] = stage.findMissingPartitions()
// 获取ActiveJob的properties,properties中包含了当前stage相关的scheduling pool、job group和description等
val properties = jobIdToActiveJob(jobId).properties
runningStages += stage
// SparkListenerStageSubmitted事件应该会在测试tasks是否可以被序列化前被发送。
// 如果tasks不能被序列化,则SparkListenerStageCompleted事件会被发送,
// 而其应该总是在对应的SparkListenerStageSubmitted事件之后。
stage match { // 启动对当前stage的输出提交到HDFS的Coordinator
case s: ShuffleMapStage =>
outputCommitCoordinator.stageStart(stage = s.id, maxPartitionId = s.numPartitions - 1)
case s: ResultStage =>
outputCommitCoordinator.stageStart(
stage = s.id, maxPartitionId = s.rdd.partitions.length - 1)
}
// 获取还没有完成计算的每一个分区的偏好位置
val taskIdToLocations: Map[Int, Seq[TaskLocation]] = try {
stage match {
case s: ShuffleMapStage =>
partitionsToCompute.map { id => (id, getPreferredLocs(stage.rdd, id))}.toMap
case s: ResultStage =>
partitionsToCompute.map { id =>
val p = s.partitions(id)
(id, getPreferredLocs(stage.rdd, p))
}.toMap
}
} catch { // 如果发生异常,则调用stage.makeNewStageAttempt方法开始一次新的尝试
case NonFatal(e) =>
stage.makeNewStageAttempt(partitionsToCompute.size)
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
// 开始stage的执行尝试
stage.makeNewStageAttempt(partitionsToCompute.size, taskIdToLocations.values.toSeq)
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
// TODO: 也许我们可以在stage中保存taskBinary来防止对其多次序列化。
// 广播task的二进制序列,将tasks分发给executors。
// 注意我们为每个task广播RDD的序列化拷贝,并且我们将会反序列化它,这意味着每个task得到了RDD的不同拷贝。
// 这提供了tasks间的强隔离,因此我们可以改变它们闭包中的对象引用的状态。
// 这在hadoop中是必须的,在hadoop中JobConf/Configuration对象都不是线程安全的。
var taskBinary: Broadcast[Array[Byte]] = null
var partitions: Array[Partition] = null
try {
// 对ShuffleMapTask,则序列化并广播(rdd, shuffleDep)。
// 对ResultTask,则序列化并广播(rdd, func)。
var taskBinaryBytes: Array[Byte] = null
// taskBinaryBytes和partitions都会被checkpint的状态影响。
// 我们需要该操作同步以防止另一个并发的job正在checkpint这个RDD,从而我们得到两个变量的一致的值。
RDDCheckpointData.synchronized {
taskBinaryBytes = stage match {
case stage: ShuffleMapStage =>
JavaUtils.bufferToArray(
closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef))
case stage: ResultStage =>
JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.func): AnyRef))
}
partitions = stage.rdd.partitions
}
taskBinary = sc.broadcast(taskBinaryBytes)
} catch {
// In the case of a failure during serialization, abort the stage.
case e: NotSerializableException =>
abortStage(stage, "Task not serializable: " + e.toString, Some(e))
runningStages -= stage
// Abort execution
return
case NonFatal(e) =>
abortStage(stage, s"Task serialization failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
val tasks: Seq[Task[_]] = try {
val serializedTaskMetrics = closureSerializer.serialize(stage.latestInfo.taskMetrics).array()
stage match {
case stage: ShuffleMapStage =>
stage.pendingPartitions.clear()
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = partitions(id)
stage.pendingPartitions += id
new ShuffleMapTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, properties, serializedTaskMetrics, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId)
}
case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, id, properties, serializedTaskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId)
}
}
} catch {
case NonFatal(e) =>
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
if (tasks.size > 0) {
// 如果有task等待执行,则调用taskScheduler.submitTasks方法提交这批TaskSet
logInfo(s"Submitting ${tasks.size} missing tasks from $stage (${stage.rdd}) (first 15 " +
s"tasks are for partitions ${tasks.take(15).map(_.partitionId)})")
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))
stage.latestInfo.submissionTime = Some(clock.getTimeMillis())
} else {
// 因为我们前面发送过SparkListenerStageSubmitted事件,因此当没有task要运行时我们应该
// 把当前stage标记为完成。
// 如果没有创建任何task,则将当前stage标记为完成
markStageAsFinished(stage, None)
val debugString = stage match {
case stage: ShuffleMapStage =>
s"Stage ${stage} is actually done; " +
s"(available: ${stage.isAvailable}," +
s"available outputs: ${stage.numAvailableOutputs}," +
s"partitions: ${stage.numPartitions})"
case stage : ResultStage =>
s"Stage ${stage} is actually done; (partitions: ${stage.numPartitions})"
}
logDebug(debugString)
submitWaitingChildStages(stage)
}
将Stage标记为已完成
将stage标记为已完成,并将它从runningStages中移除。
DAGScheduler#markStageAsFinished
private def markStageAsFinished(
stage: Stage,
errorMessage: Option[String] = None,
willRetry: Boolean = false): Unit = {
// 计算stage的执行时间
val serviceTime = stage.latestInfo.submissionTime match {
case Some(t) => "%.03f".format((clock.getTimeMillis() - t) / 1000.0)
case _ => "Unknown"
}
if (errorMessage.isEmpty) {
// 设置stage完成时间
stage.latestInfo.completionTime = Some(clock.getTimeMillis())
// 为当前stage清除失败计数,现在该stage成功了。
// 我们仅限制stage尝试的连续失败次数,因此如果一个stage被一个长期运行的job多次使用,
// 那么无关的错误不会最终造成该stage被终止。
stage.clearFailures()
} else {
// 保存失败原因和完成时间
stage.latestInfo.stageFailed(errorMessage.get)
logInfo(s"$stage (${stage.name}) failed in $serviceTime s due to ${errorMessage.get}")
}
if (!willRetry) {
// 停止当前stage的输出提交到HDFS的Coordinator
outputCommitCoordinator.stageEnd(stage.id)
}
listenerBus.post(SparkListenerStageCompleted(stage.latestInfo))
runningStages -= stage // 将当前stage从runningStages中移除
}
提交所有子stage
当stage成功完成后,需要检查依赖于该stage的子stages是否可以提交运行(检查他们是否还有任何依赖的Stage没有完成,如果没有就可以提交该Stage)。
此外每当完成一次DAGScheduler的事件循环以后,也会触发一次从等待(waitingStages)和失败列表(failedStages)中扫描并提交就绪Stage的调用过程。
DAGScheduler#submitWaitingChildStages
/**
* 检查等待执行的stages现在是否合格来重新提交。
* 提交依赖于给定父stage的stages。该函数当该父stage成功完成时被调用。
*/
private def submitWaitingChildStages(parent: Stage) {
logTrace(s"Checking if any dependencies of $parent are now runnable")
logTrace("running: " + runningStages)
logTrace("waiting: " + waitingStages)
logTrace("failed: " + failedStages)
val childStages = waitingStages.filter(_.parents.contains(parent)).toArray
waitingStages --= childStages
for (stage <- childStages.sortBy(_.firstJobId)) {
submitStage(stage)
}
}
参考文章
- http://www.voidcn.com/article/p-ozmmmqvu-bgs.html
- https://www.waitig.com/spark-dagscheduler划分stage源码解析.html
- https://www.cnblogs.com/luogankun/p/3826245.html
- http://cxy7.com/articles/2018/06/19/1529413760405.html