传统机器学习之朴素贝叶斯、支持向量机、LDA
1. 朴素贝叶斯的原理
朴素贝叶斯的原理:
基于朴素贝叶斯公式,比较出后验概率的最大值来进行分类,后验概率的计算是由先验概率与类条件概率的乘积得出,先验概率和类条件概率要通过训练数据集得出,即为朴素贝叶斯分类模型,将其保存为中间结果,测试文档进行分类时调用这个中间结果得出后验概率。
优点:在数据较少的情况下仍然有效,可以处理多分类问题
缺点:对于输入数据的准备方式较为敏感
2. 利用朴素贝叶斯模型进行文本分类
垃圾邮件曾经是一个令人非常头痛的问题,长期困扰着邮件运营商和用户。据统计,在2005年,用户收到的电子邮件中80%以上是垃圾邮件。
但你有没有感觉到,这些年来,你收到的垃圾邮件越来越少了,甚至已经几乎感受不到它们的存在。背后一定有什么原因,那就是运营商采用了垃圾邮件过滤方法。
一)基本方法
现在我们收到一封新邮件,我们假定它是正常邮件和垃圾邮件的概率各是50%。即:
P(正常)= P(垃圾)=50%
然后,对这封新邮件的内容进行解析,发现其中含有“发票”这个词,那么这封邮件属于垃圾邮件的概率提高到多少?其实就是计算一个条件概率,在有“发票”词语的条件下,邮件是垃圾邮件的概率:P(垃圾|发票)。直接计算肯定是无法计算了,这时要用到贝叶斯定理:
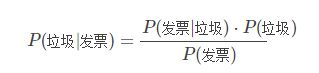
根据全概率公式:
![]()
所以:

其中,P(发票|垃圾)表示所有垃圾邮件中出现“发票”的概率,我们假设100封垃圾邮件中有5封包含“发票”这个词,那么这个概率是5%。P(发票|正常)表示所有正常邮件中出现“发票”的概率,我们假设1000封正常邮件中有1封包含“发票”这个词,那么这个概率是0.1%。于是:
P(垃圾|发票)=(5%×50%) / (5%×50% + 0.1%×50%)
因此,这封新邮件是垃圾邮件的概率是98%。从贝叶斯思维的角度,这个“发票”推断能力很强,直接将垃圾邮件50%的概率提升到98%了。那么,我们是否就此能给出结论:这是封垃圾邮件?
回答是不能!这里有2个核心问题没有解决:
一是 P(发票|垃圾)和P(发票|正常)是我们假定的,怎样实际计算它们?
二是 正常邮件也是可能含有“发票”这个词的,误判了怎么办?
(二)概率值计算问题
对于第一个问题,该“统计学”出场了。过程很简单,我们首先收集10000封邮件,用人工方式进行简单判断标定,哪个是正常邮件,哪个是垃圾邮件,假设各有5000封,即P(正常)= P(垃圾)=50%。然后编写程序解析所有邮件的内容文本,提取每一个词,计算每个词语在正常邮件和垃圾邮件中的出现频率。例如“发票”在5000封正常邮件中,出现了5次,那么P(发票|正常)=0.1%,“发票”在5000封垃圾邮件中个,出现了250次,那么P(发票|正常)=1%。以后,就全自动运行,随着邮件数量的增加,这些计算结果会自动调整,越来越精确。(注意:如果一个词只出现在垃圾邮件中,正常邮件中没有,那么在正常邮件中的出现频率也需要设定一个很小的值(例如0.1%),反之亦然,这样做是为了避免概率为0)。
(三)误判问题
对于第二个问题,解决的思路是“多特征判断”。就像猫和老虎,如何单看颜色、花纹都不好判断,那就颜色、花纹、大小、体重等一起来判断。同理,对于“发票”不好来判断,那就联合其他词语一起来判断,如果这封邮件中除了“发票”,还有“常年”,“代开”,“各种”,“行业”,“绝对正规”,“税点低”等词语,那么就通过这些词语联合认定这封邮件是垃圾邮件。
计算方法也不复杂,在基本方法计算的基础上,选取前n个(例如n=3,实际应用中是15个词/字以上)概率最高的词,假设为:“发票”,“常年”,“代开”。然后计算其联合条件概率。即在这3个词同时出现的条件下,是垃圾邮件的概率,即:P(垃圾|发票;常年;代开)。这时仍要用到贝叶斯定理:
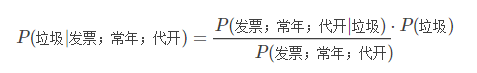
这里还需要一个假设:所有词语彼此之间是不相关的(当然实际上不可能完全没有相关性,但可以忽略)。所以:
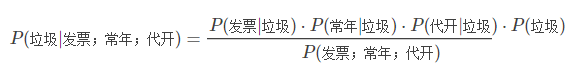
上边式子中右边的分母不太好求。我们可以换种方式,求这封邮件是正常邮件的概率:
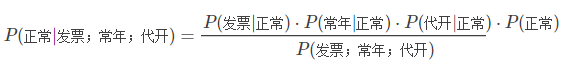
上面两个式子相除,得到:

即在这3个词同时出现的情况下,是垃圾邮件的概率与是正常邮件的概率的比值。上边式子中的每一项,都可以用前面介绍的统计学方法得到。假设P(常年|垃圾)=P(常年|正常)=5%,P(代开|垃圾)=5%,P(代开|正常)=0.1%。那么:
![]()
即多个词联合认定,这封邮件是垃圾邮件概率是正常邮件的2500倍,可以确定是垃圾邮件了
作者:saltriver
原文:https://blog.csdn.net/saltriver/article/details/72571876
3. SVM的原理
支持向量机,因其英文名为support vector machine,故一般简称SVM,通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
4. 利用SVM模型进行文本分类
1 SVM简介
支持向量机(SVM)算法被认为是文本分类中效果较为优秀的一种方法,它是一种建立在统计学习理论基础上的机器学习方法。该算法基于结构风险最小化原理,将数据集合压缩到支持向量集合,学习得到分类决策函数。这种技术解决了以往需要无穷大样本数量的问题,它只需要将一定数量的文本通过计算抽象成向量化的训练文本数据,提高了分类的精确率。
支持向量机(SVM)算法是根据有限的样本信息,在模型的复杂性与学习能力之间寻求最佳折中,以求获得最好的推广能力支持向量机算法的主要优点有:
(1)专门针对有限样本情况,其目标是得到现有信息下的最优解而不仅仅是样本数量趋于无穷大时的最优值;
(2)算法最终转化为一个二次型寻优问题,理论上得到的是全局最优点,解决了在神经网络方法中无法避免的局部极值问题;
(3)支持向量机算法能同时适用于稠密特征矢量与稀疏特征矢量两种情况,而其他一些文本分类算法不能同时满足两种情况。
(4)支持向量机算法能够找出包含重要分类信息的支持向量,是强有力的增量学习和主动学习工具,在文本分类中具有很大的应用潜力。
2 基于SVM的文本分类过程
SVM 文本分类算法主要分四个步骤:文本特征提取、文本特征表示、归一化处理和文本分类。
2.1文本特征提取
目前,在对文本特征进行提取时,常采用特征独立性假设来简化特征选择的过程,达到计算时间和计算质量之间的折中。一般的方法是根据文本中词汇的特征向量,通过设置特征阀值的办法选择最佳特征作为文本特征子集,建立特征模型。(特征提取前,先分词,去停用词)。
本特征提取有很多方法,其中最常用的方法是通过词频选择特征。先通过词频计算出权重,按权重从大到小排序,然后剔除无用词,这些词通常是与主题无关的,任何类的文章中都有可能大量出现的,比如“的”“是”“在”一类的词,一般在停词表中已定义好,去除这些词以后,有一个新的序列排下来,然后可以按照实际需求选取权重最高的前8个,10个或者更多词汇来代表该文本的核心内容。
综上所述,特征项的提取步骤可以总结为:
(1)对全部训练文档进行分词,由这些词作为向量的维数来表示文本;
(2)统计每一类内文档所有出现的词语及其频率,然后过滤,剔除停用词和单字词;
(3)统计每一类内出现词语的总词频,并取其中的若干个频率最高的词汇作为这一类别的特征词集;
(4)去除每一类别中都出现的词,合并所有类别的特征词集,形成总特征词集。最后所得到的特征词集就是我们用到的特征集合,再用该集合去筛选测试集中的特征。
2.2文本特征表示
用tfidf计算权值
2.3归一化处理
归一化就是要把需要处理的数据经过处理后(通过某种算法)限制在你需要的一定范围内。
2.4文本分类
经过文本预处理、特征提取、特征表示、归一化处理后,已经把原来的文本信息抽象成一个向量化的样本集,然后把此样本集与训练好的模板文件进行相似度计算,若不属于该类别,则与其他类别的模板文件进行计算,直到分进相应的类别,这就是SVM 模型的文本分类方式。
5. pLSA、共轭先验分布;LDA主题模型原理
LDA的全称是Latent Dirichlet allocation
LDA算法可以根据给定的文本集合以及预先指定的主题个数,对文本进行主题分类,并给出每个类别下的主题关键词。
理解LDA算法的关键是共轭先验分布,LDA利用了共轭先验分布的特性:经过Bayes推断之后的后验分布仍然和先验分布的形式相同,这意味着可以利用一批数据来更新先验分布P0的参数,使其变成服从同样分布的后验分布P1,并可以将P1作为下一批数据的先验分布。
如果制定了数据生成过程的概率分布,以及参数模型的先验分布,我们可以推导出后验概率分布服从的概率分布模型。如果先验分布和后验分布可以使用同一种概率分布模型来表示,则称![]()
共轭分布描述的是概率分布之间的关系。比如高斯分布是高斯分布的先验分布,Beta分布是二项分布的先验分布。这里有个小技巧,为了证明上述两个例子,无须完整计算Bayes后验分布的表达形式,即可得出结论:


如何理解共轭先验分布?
我们可以将先验分布看做机器学习中的模型(比如Beta分布),那么Beta分布中的参数a,b可以作为模型状态的表示。每次有新的训练数据(样本观测结果),我们就可以更新模型参数(根据数据将先验分布转换为后验分布),以Beta分布为例,如果数据生成过程服从二项分布,参数a,b根据数据更新后的值为a+s,b+f,其中s和f只依赖于训练数据。那么我们可以说模型得到了“训练”,训练的结果就是模型的状态(a,b)得到了更新。这个解释类似于维基百科【1】中的Dynamical system的解释。
6. 使用LDA生成主题特征,在之前特征的基础上加入主题特征进行文本分类
主题模型主要作用
有了主题模型,我们该怎么使用它呢?它有什么优点呢?我总结了以下几点:
1)它可以衡量文档之间的语义相似性。对于一篇文档,我们求出来的主题分布可以看作是对它的一个抽象表示。对于概率分布,我们可以通过一些距离公式(比如KL距离)来计算出两篇文档的语义距离,从而得到它们之间的相似度。
2)它可以解决多义词的问题。回想最开始的例子,“苹果”可能是水果,也可能指苹果公司。通过我们求出来的“词语-主题”概率分布,我们就可以知道“苹果”都属于哪些主题,就可以通过主题的匹配来计算它与其他文字之间的相似度。
3)它可以排除文档中噪音的影响。一般来说,文档中的噪音往往处于次要主题中,我们可以把它们忽略掉,只保持文档中最主要的主题。
4)它是无监督的,完全自动化的。我们只需要提供训练文档,它就可以自动训练出各种概率,无需任何人工标注过程。
5)它是跟语言无关的。任何语言只要能够对它进行分词,就可以进行训练,得到它的主题分布。
使用主题模型特点:
- 如果要训练一个主题模型用于预测,数据量要足够大;
- 理论上讲,词汇长度越长,表达的主题越明确,这需要一个优秀的词库;
- 如果想要主题划分的更细或突出专业主题,需要专业的词典;
- LDA的参数alpha对计算效率和模型结果影响非常大,选择合适的alpha可以提高效率和模型可靠性;
- 主题数的确定没有特别突出的方法,更多需要经验;
- 根据时间轴探测热点话题和话题趋势,主题模型是一个不错的选择;
下面用lda来测试分类的效果。之前的准备工作有分词,停用词加载。语料用的是某通信客服语料。
import codecs
from gensim.models import LdaModel
from gensim.corpora import Dictionary
from gensim import corpora
from gensim import similarities
import jieba
train = []
stopwords = codecs.open('stopword.txt','r',encoding='utf8').readlines()
stopwords = [ w.strip() for w in stopwords ]
fp = codecs.open('E:\loaddata\qa_seg.txt','r',encoding='utf8')
# 去除停止词
for line in fp:
line = line.split()
train.append([ w for w in line if w not in stopwords ])
dictionary = corpora.Dictionary(train)
corpus = [ dictionary.doc2bow(text) for text in train ]
lda = LdaModel(corpus=corpus, id2word=dictionary, num_topics=50)
print(dictionary)
# print(dictionary.token2id)
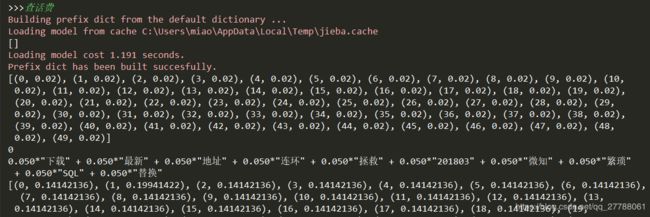
# 打印前30个topic的词分布
print(lda.print_topics(30))
# 打印id为30的topic的词分布
print("------")
print(lda.print_topic(30))
# 输入一句话,查询属于LDA得到的哪个主题类型,先建立索引:
print('输入一句话,查询属于LDA得到的哪个主题类型,先建立索引:')
index = similarities.MatrixSimilarity(lda[corpus])
query = input(">>>")
query_bow = dictionary.doc2bow(list(jieba.cut(query)))
print (query_bow)
query_lda = lda[query_bow]
print (query_lda) # 主题编号 + 相似度
print(query_lda[0][0]) # 主题编号
print(lda.print_topic(query_lda[0][0])) # 主题
# print(lda.print_topic(query_lda[0][0]-1))
# 比较和第几句话相似,用LDA得到的索引接着做,并排序输出
sims = index[query_lda]
print(list(enumerate(sims)))
print("排序输出")
sort_sims = sorted(enumerate(sims), key=lambda item: -item[1])
print(sort_sims)
print('与第' + str(sort_sims[0][0]) + '句话最相似')

可以看出输出结果里有各个文本的主题占比
其中我们输入一句话判断属于那个主题
7. 参考
朴素贝叶斯1:sklearn:朴素贝叶斯(naïve beyes) - 专注计算机体系结构 - CSDN博客
LDA数学八卦
lda2:用LDA处理文本(Python) - 专注计算机体系结构 - CSDN博客
合并特征:Python:合并两个numpy矩阵 - 专注计算机体系结构 - CSDN博客