20项任务全面碾压BERT,全新XLNet预训练模型
这是继BERT发布以来又一个令广大NLPer兴奋的消息, CMU 与谷歌大脑提出的 XLNet 在 20 个任务上超过了 BERT 的表现,并在 18 个任务上取得了当前最佳效果。
而真正令人激动的是, XLNet 已经开放了训练代码和大型预训练模型,
论文地址:https://arxiv.org/pdf/1906.08237.pdf
开源代码与预训练模型:https://github.com/zihangdai/xlnet
BERT 带来的震撼还未平息,今日又一全新模型出现。

XLNet是一种基于 a novel generalized permutation language modeling objective的无监督表示学习方法。此外,采用Transformer-XL作为主干模型,在长文本表示的语言任务中表现出了卓越的性能。并且在各种语言任务上实现了当前最好的(SOTA)效果,如QA,natural language inference, sentiment analysis, and document ranking等。
截止到2019年6月19日,XLNet在20项任务上的表现优于BERT,并在18项任务中取得了最好的成果。以下是XLNet-Large和BERT-Large之间的一些比较:
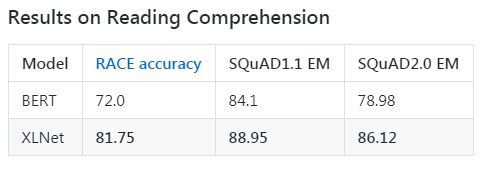
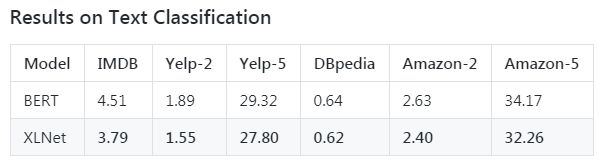

作者阵容也是相当牛*:
杨植麟(曾经的清华学霸,现在 CMU 读博)
Zihang Dai(CMU 博士)
CMU 教授 Yiming Yang
CMU 语言技术中心的总负责人 Jaime Carbonell
CMU 教授 & 苹果 AI 负责人 Russ Salakhutdinov
谷歌大脑的创始成员 & AutoML 的缔造者之一 Quoc Le
相比于 BERT,XLNet 有哪些提升呢?
BERT存在的一些问题:
基于DAE预训练模型虽然可以很好地建模双向语境信息,但由于需要 mask 一部分输入,从而忽略了被 mask 位置之间的依赖关系
出现预训练和微调效果的差异(pretrain-finetune discrepancy)。
泛化自回归预训练模型 XLNet的优化点:
通过最大化所有可能的因式分解顺序的对数似然,学习双向语境信息;
用自回归本身的特点克服 BERT 的缺点。
融合了当前最优自回归模型 Transformer-XL 的思路。
深度解读
首先,XLNet 不使用传统 AR 模型中固定的前向或后向因式分解顺序,而是最大化所有可能因式分解顺序的期望对数似然。由于对因式分解顺序的排列操作,每个位置的语境都包含来自左侧和右侧的 token。因此,每个位置都能学习来自所有位置的语境信息,即捕捉双向语境。
其次,作为一个泛化 AR 语言模型,XLNet 不依赖残缺数据。因此,XLNet 不会有 BERT 的预训练-微调差异。同时,自回归目标提供一种自然的方式,来利用乘法法则对预测 token 的联合概率执行因式分解(factorize),这消除了 BERT 中的独立性假设。
除了提出一个新的预训练目标,XLNet 还改进了预训练的架构设计。
简单地使用 Transformer(-XL) 架构进行基于排列的(permutation-based)语言建模是不成功的,因为因式分解顺序是任意的、训练目标是模糊的。因此,研究人员提出,对 Transformer(-XL) 网络的参数化方式进行修改,移除模糊性。
目标:排列语言建模(Permutation Language Modeling)
为了提供一个完整的概览图,研究者展示了一个在给定相同输入序列 x(但因式分解顺序不同)时预测 token x_3 的示例,如下图所示:
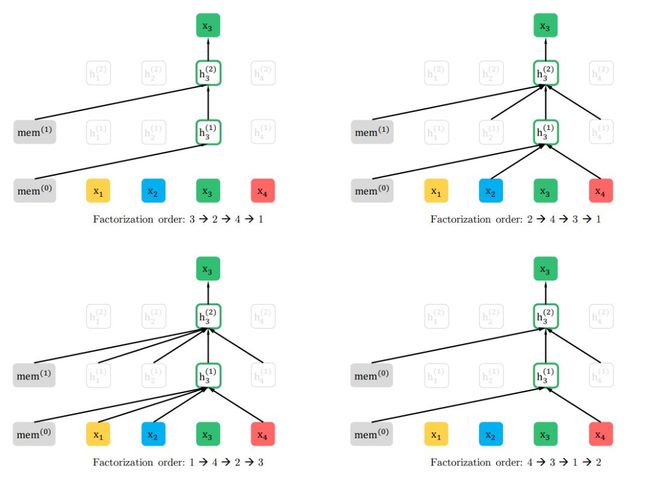
图 1:排列语言建模目标示例:给定相同的输入序列 x,但因式分解顺序不同,此时预测 x_3。
模型架构:对目标感知表征的双流自注意力
下图 2 的 a、b 分别展示了这两种表征的学习。其中内容表征与 Transforme 的隐藏状态类似,它将同时编码输入本身的内容及上下文信息。Query 表征仅能获取上下文信息及当前的位置,它并不能获取当前位置的内容。具体来说,他们借鉴了 Transformer-XL 中的两项重要技术——相对位置编码范式和分割循环机制。现在,结合双流注意力和 Transformer-XL 的改进,上面图 2(c) 展示了最终的排列语言建模架构。
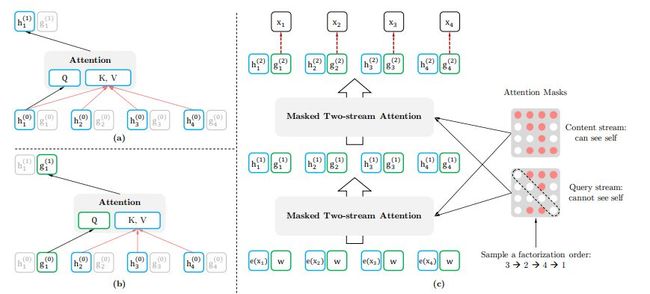
图 2:(a)内容流注意力,与标准自注意力相同;(b)Query 流注意力,没有获取内容 x_z_t 的信息;(c)利用双流注意力的排列语言建模概览图。
Fine-tuning 与使用
STS-B: sentence pair relevance regression (with GPUs)
1# Download the GLUE data by running this script and unpack it to some directory $GLUE_DIR. 2 3# Perform multi-GPU (4 V100 GPUs) finetuning with XLNet-Large by running 4 5CUDA_VISIBLE_DEVICES=0,1,2,3 python run_classifier.py 6 --do_train=True 7 --do_eval=False 8 --task_name=sts-b 9 --data_dir=${GLUE_DIR}/STS-B 10 --output_dir=proc_data/sts-b 11 --model_dir=exp/sts-b 12 --uncased=False 13 --spiece_model_file=${LARGE_DIR}/spiece.model 14 --model_config_path=${LARGE_DIR}/model_config.json 15 --init_checkpoint=${LARGE_DIR}/xlnet_model.ckpt 16 --max_seq_length=128 17 --train_batch_size=8 18 --num_hosts=1 19 --num_core_per_host=4 20 --learning_rate=5e-5 21 --train_steps=1200 22 --warmup_steps=120 23 --save_steps=600 24 --is_regression=True2526# Evaluate the finetuning results with a single GPU by2728CUDA_VISIBLE_DEVICES=0 python run_classifier.py 29 --do_train=False 30 --do_eval=True 31 --task_name=sts-b 32 --data_dir=${GLUE_DIR}/STS-B 33 --output_dir=proc_data/sts-b 34 --model_dir=exp/sts-b 35 --uncased=False 36 --spiece_model_file=${LARGE_DIR}/spiece.model 37 --model_config_path=${LARGE_DIR}/model_config.json 38 --max_seq_length=128 39 --eval_batch_size=8 40 --num_hosts=1 41 --num_core_per_host=1 42 --eval_all_ckpt=True 43 --is_regression=True4445# Expected performance: "eval_pearsonr 0.916+ "# Download the GLUE data by running this script and unpack it to some directory $GLUE_DIR.
2
3# Perform multi-GPU (4 V100 GPUs) finetuning with XLNet-Large by running
4
5CUDA_VISIBLE_DEVICES=0,1,2,3 python run_classifier.py
6 --do_train=True
7 --do_eval=False
8 --task_name=sts-b
9 --data_dir=${GLUE_DIR}/STS-B
10 --output_dir=proc_data/sts-b
11 --model_dir=exp/sts-b
12 --uncased=False
13 --spiece_model_file=${LARGE_DIR}/spiece.model
14 --model_config_path=${LARGE_DIR}/model_config.json
15 --init_checkpoint=${LARGE_DIR}/xlnet_model.ckpt
16 --max_seq_length=128
17 --train_batch_size=8
18 --num_hosts=1
19 --num_core_per_host=4
20 --learning_rate=5e-5
21 --train_steps=1200
22 --warmup_steps=120
23 --save_steps=600
24 --is_regression=True
25
26# Evaluate the finetuning results with a single GPU by
27
28CUDA_VISIBLE_DEVICES=0 python run_classifier.py
29 --do_train=False
30 --do_eval=True
31 --task_name=sts-b
32 --data_dir=${GLUE_DIR}/STS-B
33 --output_dir=proc_data/sts-b
34 --model_dir=exp/sts-b
35 --uncased=False
36 --spiece_model_file=${LARGE_DIR}/spiece.model
37 --model_config_path=${LARGE_DIR}/model_config.json
38 --max_seq_length=128
39 --eval_batch_size=8
40 --num_hosts=1
41 --num_core_per_host=1
42 --eval_all_ckpt=True
43 --is_regression=True
44
45# Expected performance: "eval_pearsonr 0.916+ "
Custom Usage of XLNet
1 2For finetuning, it is likely that you will be able to modify 3existing files such as run_classifier.py, run_squad.py and 4run_race.py for your task at hand. However, we also provide an 5abstraction of XLNet to enable more flexible usage. Below is an 6example: 7 8import xlnet 910# some code omitted here...11# initialize FLAGS12# initialize instances of tf.Tensor, including input_ids, seg_ids, and input_mask1314# XLNetConfig contains hyperparameters that are specific to a model checkpoint.15xlnet_config = xlnet.XLNetConfig(json_path=FLAGS.model_config_path)1617# RunConfig contains hyperparameters that could be different between pretraining and finetuning.18run_config = xlnet.create_run_config(is_training=True, is_finetune=True, FLAGS=FLAGS)1920# Construct an XLNet model21xlnet_model = xlnet.XLNetModel(22 xlnet_config=xlnet_config,23 run_config=run_config,24 input_ids=input_ids,25 seg_ids=seg_ids,26 input_mask=input_mask)2728# Get a summary of the sequence using the last hidden state29summary = xlnet_model.get_pooled_out(summary_type="last")3031# Get a sequence output32seq_out = xlnet_model.get_sequence_output()3334# build your applications based on `summary` or `seq_out`
2For finetuning, it is likely that you will be able to modify
3existing files such as run_classifier.py, run_squad.py and
4run_race.py for your task at hand. However, we also provide an
5abstraction of XLNet to enable more flexible usage. Below is an
6example:
7
8import xlnet
9
10# some code omitted here...
11# initialize FLAGS
12# initialize instances of tf.Tensor, including input_ids, seg_ids, and input_mask
13
14# XLNetConfig contains hyperparameters that are specific to a model checkpoint.
15xlnet_config = xlnet.XLNetConfig(json_path=FLAGS.model_config_path)
16
17# RunConfig contains hyperparameters that could be different between pretraining and finetuning.
18run_config = xlnet.create_run_config(is_training=True, is_finetune=True, FLAGS=FLAGS)
19
20# Construct an XLNet model
21xlnet_model = xlnet.XLNetModel(
22 xlnet_config=xlnet_config,
23 run_config=run_config,
24 input_ids=input_ids,
25 seg_ids=seg_ids,
26 input_mask=input_mask)
27
28# Get a summary of the sequence using the last hidden state
29summary = xlnet_model.get_pooled_out(summary_type="last")
30
31# Get a sequence output
32seq_out = xlnet_model.get_sequence_output()
33
34# build your applications based on `summary` or `seq_out`
Pretraining with XLNet
1 2Refer to train.py for pretraining on TPUs and train_gpu.py for 3pretraining on GPUs. First we need to preprocess the text data 4into tfrecords. 5 6python data_utils.py 7 --bsz_per_host=32 8 --num_core_per_host=16 9 --seq_len=512 10 --reuse_len=256 11 --input_glob=*.txt 12 --save_dir=${SAVE_DIR} 13 --num_passes=20 14 --bi_data=True 15 --sp_path=spiece.model 16 --mask_alpht=6 17 --mask_beta=1 18 --num_predict=8519 20where input_glob defines all input text files, save_dir is the 21output directory for tfrecords, and sp_path is a Sentence Piece 22model. Here is our script to train the Sentence Piece model23 2425spm_train 26 --input=$INPUT 27 --model_prefix=sp10m.cased.v3 28 --vocab_size=32000 29 --character_coverage=0.99995 30 --model_type=unigram 31 --control_symbols=,,,, 32 --user_defined_symbols=,.,(,),",-,–,£,€ 33 --shuffle_input_sentence 34 --input_sentence_size=1000000035
2Refer to train.py for pretraining on TPUs and train_gpu.py for
3pretraining on GPUs. First we need to preprocess the text data
4into tfrecords.
5
6python data_utils.py
7 --bsz_per_host=32
8 --num_core_per_host=16
9 --seq_len=512
10 --reuse_len=256
11 --input_glob=*.txt
12 --save_dir=${SAVE_DIR}
13 --num_passes=20
14 --bi_data=True
15 --sp_path=spiece.model
16 --mask_alpht=6
17 --mask_beta=1
18 --num_predict=85
19
20where input_glob defines all input text files, save_dir is the
21output directory for tfrecords, and sp_path is a Sentence Piece
22model. Here is our script to train the Sentence Piece model
23
24
25spm_train
26 --input=$INPUT
27 --model_prefix=sp10m.cased.v3
28 --vocab_size=32000
29 --character_coverage=0.99995
30 --model_type=unigram
31 --control_symbols=,,,,
32 --user_defined_symbols=,.,(,),",-,–,£,€
33 --shuffle_input_sentence
34 --input_sentence_size=10000000
35
详细使用介绍请访问GitHub
推荐阅读
全国392所“野鸡大学”曝光:门槛很低,只看名字难分辨
中国神童13岁免试上大学,极端荣耀后却选择出家为僧!
12 个 Python 程序员面试必备问题与答案
Python 是不是有点膨胀啊,甚至想和 Java 刚一把

喜欢就点击“在看”吧!