Linux 内存管理概要
之前学习内存方面的都太关注于细节,就有些知其然而不知其所以然的感觉。所以这篇文章抛开细节实现,将Linux内存管理的大概思路整理一下。
Linux操作系统支持多任务系统,即(看上去)支持多任务并发处理。实际上,系统同时运行的进程数不会超过CPU数目,因此内核会在很短的时间间隔在不同的进程之间切换(用户是注意不到),从而产生同时处理多进程的假象。
Linux对于每一个任务有分配一个虚拟地址空间,而CPU的字长决定了虚拟地址空间的大小,如32位CPU即![]() 字节=4GB。
字节=4GB。
那么,现在问题就有来了,给每个任务分配一个这么大的虚拟地址空间是否实际内存会不够用,虚拟地址空间又如何跟实际内存关联起来的?
在解释这个问题前,先厘清下一些特殊的情况。
Linux又将虚拟地址空间划分为两部分,分别是内核空间和用户空间。如下图所示,0~TASK_SIZE为用户空间,TASK_SIZE~![]() /
/![]() 为内核空间。每个任务是有自己的用户空间,但每个任务的内核空间是相同的。
为内核空间。每个任务是有自己的用户空间,但每个任务的内核空间是相同的。
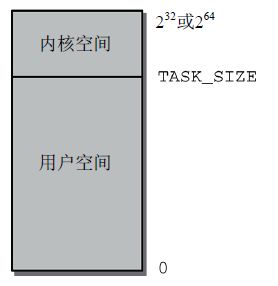
那么,又有问题了。内核空间既然对每个任务是相同的,那么岂不是违反了设计虚拟地址空间的初衷(即每个任务跑在自己地址空间,相互不打扰)?
每个用户态任务是无法直接访问内核空间内容的,而是通过系统调用间接访问。大致flow是这样的,用户态任务发起系统调用后,会引发exception,对于ARM芯片架构就是由USER mode->IRQ mode->SVC mode,从而进入内核态,内核态的接口将内核空间的数据copy至用户态进程的用户空间,最后再恢复状态,从而让用户态任务能够拿到想要的数据。
这里还介绍一个内核态任务。与用户态任务不同,内核态任务只会访问内核空间,且所有内核态任务共用内核空间。
在回到之前的问题,给每个任务分配一个这么大的虚拟地址空间是否实际内存会不够用,虚拟地址空间又如何跟实际内存关联起来的?
那么这边要介绍三个概念,页,页表,页帧
每个虚拟地址空间都会被内核分为等长的部分,这每个部分,被称为页。而实际内存也被分为等长的部分,被称为页帧。下图为两个虚拟地址空间与实际内存的映射图。而用于保存该映射关系的,被称为页表。
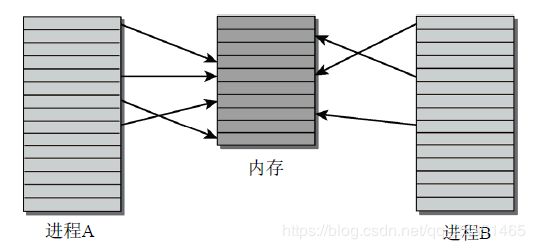
一个进程是用多少页,才会对应申请多少页帧。所以实际内存不会因虚拟地址为![]() /
/![]() 而占用相同的实际内存。
而占用相同的实际内存。
现在算一笔账,一页一般是4KB,以![]() 即4GB虚拟内存为例,那么便是需要
即4GB虚拟内存为例,那么便是需要![]() 个页表项,而地址是32位的,即每个地址4Byte去保存,那么一个进程的页表需要4MB的空间去存储。那么50个进程就需要200MB的空间,这无疑是非常浪费的。
个页表项,而地址是32位的,即每个地址4Byte去保存,那么一个进程的页表需要4MB的空间去存储。那么50个进程就需要200MB的空间,这无疑是非常浪费的。
好吧,现在看这个读者肯定有各种思路的要反驳我,不着急,我们先介绍一下,以已说明的这种方式是如何找到实际内存的。
首先,用户态进程有保存页表项首地址(实际地址)。进程想访问虚拟地址011..011(32位),那么会将虚拟地址除以4K(![]() )即该地址的前20位,该结果指示是第几个页表项,通过页表项的首地址找到对应页表,从而找到实际地址位置,然后再根据虚拟地址的后12位,得到对应偏移。这其实就要求,保存页表项的实际内存地址一定是连续的,如果不连续,难道还要再建一个表去保存对应页表项的实际地址,得不偿失。
)即该地址的前20位,该结果指示是第几个页表项,通过页表项的首地址找到对应页表,从而找到实际地址位置,然后再根据虚拟地址的后12位,得到对应偏移。这其实就要求,保存页表项的实际内存地址一定是连续的,如果不连续,难道还要再建一个表去保存对应页表项的实际地址,得不偿失。
那么建立页这个概念,将内存分为等大的页的 意义也呼之欲出。保存内存为4GB的页表项内存都需要4M,那么每一个字节都有自己映射,所需的表项内存为![]() 即16GB。这样,还不如一一映射来的好一些。
即16GB。这样,还不如一一映射来的好一些。
那么,再回到上面页表项占据一定内存,内存浪费问题。是否可以将页的大小变大一些。其实从上面的介绍,可以看出,页的大小是申请实际内存的最小单位,如果将页的大小调的过大,那么在实际使用中,会造成申请一页中,只使用了其中一部分,造成更多浪费,术语是内碎片。
换个思路,我们是否可以根据用多少页再创建多长的页表。这是可行的,不过由于要求实际内存地址连续,所以当页表超过当前可存放的位置时,就需要搬移到其他位置。而仍然会用使用实际内存较多的进程,由于页表实际地址需要连续,操作系统的内存仍然会因此变得紧张。
那么,怎么样可以破坏这种连续性呢?其实页的引入,就是将原本连续的一整块大的内存切割成很多小块。以同样的思路,也可以对页表生效。4GB的虚拟内存需要1M个页表项,那么以1K个页表项(4K大小)为一个单位进行保存,需要1K页目录(4K大小)去保存页表项单位的地址。
那么这种方式是如何找到实际内存的呢?首先用户态进程保存页目录的首地址,进程想访问虚拟地址011..011(32位),那么会将该虚拟地址除以![]() (4K*1K),结果指示的就是第几个页目录。通过页目录指示的实际地址找到1K个页表项单位。然后在取虚拟地址的中间1K的值,找到是对应第几个页表,通过该页表指示的实际位置,找到页的实际地址,最后通过4K的偏移,找到实际位置。
(4K*1K),结果指示的就是第几个页目录。通过页目录指示的实际地址找到1K个页表项单位。然后在取虚拟地址的中间1K的值,找到是对应第几个页表,通过该页表指示的实际位置,找到页的实际地址,最后通过4K的偏移,找到实际位置。
这样的做法好处是,将页表原本连续的实际物理地址切分开,从而达到提高实际内存的效率的作用。这样的方法被称为多级页表。上述描述的为二级页表的流程,目前操作系统多用三级页表和四级页表。
多级页表有没有问题呢?是有的,由于每次访问内存都需要访问多次数组,才能将虚拟地址转换实际地址。试图用下面两种方法加速该过程。
(1) CPU中有一个专门的部分称为MMU(Memory Management Unit,内存管理单元),该单元优化了内存访问操作。
(2) 地址转换中出现最频繁的那些地址,保存到称为地址转换后备缓冲器(Translation LookasideBuffer,TLB)的CPU高速缓存中。无需访问内存中的页表即可从高速缓存直接获得地址数据,因而大大加速了地址转换。