Caffe学习(5)——其他常用层及参数
除了数据层、视觉层和激活层外,还有一些常用层,包括:softmax_loss layer,Inner Product layer,reshape layer和dropout layer。整理如下:
1、softmax_loss
softmax-loss层和softmax层的计算大致相同。不过softmax是一个分类器,计算的是类别的概率,是逻辑回归(Logistics Regression)的一种推广。逻辑回归只能用于二分类,而softmax可用于多分类。
softmax和softmax_loss的区别在于:
softmax计算公式: softmax_loss计算公式:

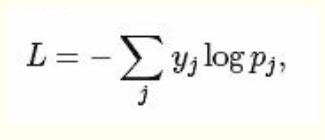
一般,用户的目的是得到各类别的概率似然值,这时只需要一个Softmax层就可以了;而用户得到似然值之后要做最大似然估计时,则只需要softmax_loss而不需要Softmax操作。不管是softmax layer还是softmax_loss layer,都是没有参数的,只是层类型不同。
softmax_loss layer(输出loss值):
layer {
name:"loss"
type:"SoftmaxWithLoss"
bottom:"ip1"
bottom:"label"
top:"loss"
}layers {
bottom:"cls3_fc"
top:"prob"
name:"prob"
type:"softmax"
}全连接层,把输入作为一个向量,输出一个简单向量,即把输入数据的blobs的width和height全变为1。(n*c1*h*w——>n*c2*1*1)
全连接层实际上也是一种卷积层,只是它的卷积核大小和原数据大小一致。因此它的参数基本和卷积层的参数一样。
layer {
name: "ip1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}num_output:filter过滤器的个数(这是必须设置的参数)
其他参数:
weight_filter:权值初始化。默认为“constant”,值全为0;很多时候也用“xavier”和“gaussian”算法来进行初始化。
bias_filler:偏置顶初始化。默认值为“constant”,值全为0。
3、accuracy
输出分类(预测)精确度。只有test阶段才有,需要加入include参数声明。
layer {
name: "accuracy"
type: "Accuracy"
bottom: "ip2"
bottom: "label"
top: "accuracy"
include {
phase: TEST
}
}4、reshape
在不改变数据的情况下,改变输入的维度。
layer {
name: "reshape"
type: "Reshape"
bottom: "input"
top: "output"
reshape_param {
shape {
dim: 0 #copy the dimension from below
dim: 2
dim: 3
dim: -1 # infer it from the other dimensions
}
}
}dim:0 ——表示维度不变,即输入和输出是相同的维度
dim:2或3 ——表示将原来维度变成2或3
dim:-1 ——表示由系统自动计算出维度。数据的总量不变,系统会根据blob数据的其他三维,自动计算当前维的维度值。
5、dropout
Dropout是一个防止过拟合的trick。可以随机让网络某些隐含层节点的权重不工作。
layer {
name: "drop7"
type: "Dropout"
bottom: "fc7conv"
top: "fc7conv"
dropout_param {
dropout_ratio: 0.5
}
}只需要设置一个dropout_ratio就可以了。
还有很多不同类型的层,如不同的损失层等等。softmax_loss是用于卷积神经网络进行分类的损失函数;Euclidean_loss用于卷积神经网络进行回归的损失函数。
layer {
name: "loss"
type: "EuclideanLoss"
bottom: "fc2"
bottom: "landmark"
top: "loss"
include {
phase: TRAIN
}
}