Hadoop中正确地添加和移除节点
正确地添加和移除节点
添加节点
克隆
克隆一台全新的Linux(如有IP冲突,可右击VMware右下角网络图标断开连接)
打开/etc/hostname修改主机名
打开/etc/sysconfig/network-script/ifcfg-ens33修改IP
重启
安装
使用安装包+hadoop-install.sh脚本快速安装一个Hadoop节点
注意使用source hadoop-install.sh执行
配置NameNode
打开/etc/hosts添加新节点的IP和主机名
打开etc/hadoop/slaves添加新节点的主机名
打开hdfs-site.xml,设置节点平衡带宽设置(默认值1M,下面设置为10M)
同步DataNode配置
在所有DataNode节点上执行hadoop-pull.sh
注意修改脚本中的NameNode变量值!
启动
在新节点上执行
hadoop-daemon.sh start datanode
平衡
让各个DataNode中的数据均匀分布,
start-balancer.sh -threshold 5
-threshold是平衡阈值,默认值允许10%的差异,值越小越平衡,但花费的时间会越长
通过下面的命令也可以设置平衡时使用的网络带宽(字节/秒)
hdfs dfsadmin -setBalancerBandwidth20971520
在网络带宽受限的情况下,平衡速度较慢,需要耐心等待一段时间才能观察到效果
平衡时先通过NameNode提供的元数据进行平衡规划,然后开启多线程将数据从老节点移到新节点。
如果想查看平衡的过程,可以用下面的命令:
hdfs balancer -threshold 5
移除节点
如果节点中已经保存了数据,则从slaves中移除节点,重启集群这种暴力手段就不适用了,如果暴力删除则会造成数据丢失。为了解决生产环境中平稳安全地移除节点的问题,Hadoop提供了一个流程:
设置排除
在namenode中打开hdfs-site.xml,设置节点排除文件的位置(必须是绝对路径)
在excludes文件中添加要排除的节点主机名,一行一个
更新节点配置
在NameNode中执行下面命令,强制重新加载配置
hdfs dfsadmin -refreshNodes
在Hadoop站点上很快就能看到Decommission正在进行,此时NameNode会检查并将数据复制到其它节点上以恢复副本数(要移除的节点上的数据不会被删除,如果数据比较敏感,要手动删除它们)。通过命令也可以查看状态:
hdfs dfsadmin -report
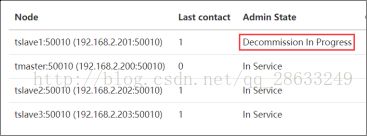
等状态变成Decommissioned后就可以关闭这个节点了,可在要移除的节点上运行相应的关闭命令,如:
hadoop-daemon.sh stop datanode
几分钟后,节点将从Decommissioned进入Dead状态。
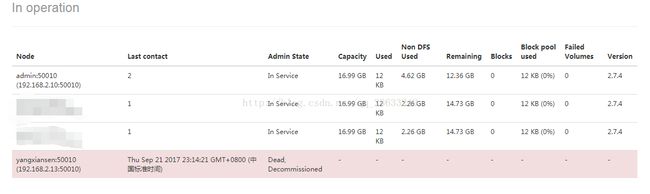
更新集群配置
从NameNode的excludes文件及slaves文件、hosts文件中去掉已经移除的主机名
在所有DataNode上执行hadoop-pull.sh脚本,同步配置。