数仓开发面试题之Hadoop相关
提纲
- MapReduce原理,map数、reduce数的参数
- 说一下 map join 与 reduce join
- hive sql怎么优
- spark和hive的区别
- 数据倾斜几种解决方式
- 数据如何清洗
- 说一下udf、udtf、udaf ,集成的类、接口,怎么写
- hive文件存储格式,对比
- 内外表区别
- hive执行的job数是怎么确定的
- cube、grouping sets、grouping__id
- order by、sort by、distribute by、cluster by
- 小文件如何优化
1.MapReduce原理,map数、reduce数的参数
MapReduce是一个基于集群的计算平台,是一个简化分布式编程的计算框架,是一个将分布式计算抽象为Map和Reduce两个阶段的编程模型。
MapReduce计算模型主要由三个阶段构成:Map、shuffle、Reduce。
Map是映射,负责数据的过滤分法,将原始数据转化为键值对;Reduce是合并,将具有相同key值的value进行处理后再输出新的键值对作为最终结果。为了让Reduce可以并行处理Map的结果,必须对Map的输出进行一定的排序与分割,然后再交给对应的Reduce,而这个将Map输出进行进一步整理并交给Reduce的过程就是Shuffle。
Map shuffle
在Map端的shuffle过程是对Map的结果进行分区、排序、分割,然后将属于同一划分(分区)的输出合并在一起并写在磁盘上,最终得到一个分区有序的文件,分区有序的含义是map输出的键值对按分区进行排列,具有相同partition值的键值对存储在一起,每个分区里面的键值对又按key值进行升序排列(默认)。
(1)Partition
对于map输出的每一个键值对,系统都会给定一个partition,partition值默认是通过计算key的hash值后对Reduce task的数量取模获得。如果一个键值对的partition值为1,意味着这个键值对会交给第一个Reducer处理。
我们知道每一个Reduce的输出都是有序的,但是将所有Reduce的输出合并到一起却并非是全局有序的,如果要做到全局有序,我们该怎么做呢?最简单的方式,只设置一个Reduce task,但是这样完全发挥不出集群的优势,而且能应对的数据量也很受限。最佳的方式是自己定义一个Partitioner,用输入数据的最大值除以系统Reduce task数量的商作为分割边界,也就是说分割数据的边界为此商的1倍、2倍至numPartitions-1倍,这样就能保证执行partition后的数据是整体有序的。
另一种需要我们自己定义一个Partitioner的情况是各个Reduce task处理的键值对数量极不平衡。对于某些数据集,由于很多不同的key的hash值都一样,导致这些键值对都被分给同一个Reducer处理,而其他的Reducer处理的键值对很少,从而拖延整个任务的进度。当然,编写自己的Partitioner必须要保证具有相同key值的键值对分发到同一个Reducer。
(2)Collector
Map的输出结果是由collector处理的,每个Map任务不断地将键值对输出到在内存中构造的一个环形数据结构中。使用环形数据结构是为了更有效地使用内存空间,在内存中放置尽可能多的数据。
这个数据结构其实就是个字节数组,叫Kvbuffer,名如其义,但是这里面不光放置了数据,还放置了一些索引数据,给放置索引数据的区域起了一个Kvmeta的别名,在Kvbuffer的一块区域上穿了一个IntBuffer(字节序采用的是平台自身的字节序)的马甲。数据区域和索引数据区域在Kvbuffer中是相邻不重叠的两个区域,用一个分界点来划分两者,分界点不是亘古不变的,而是每次Spill之后都会更新一次。初始的分界点是0,数据的存储方向是向上增长,索引数据的存储方向是向下增长
(3)Sort
当Spill触发后,SortAndSpill先把Kvbuffer中的数据按照partition值和key两个关键字升序排序,移动的只是索引数据,排序结果是Kvmeta中数据按照partition为单位聚集在一起,同一partition内的按照key有序。
(4)Spill
Spill线程为这次Spill过程创建一个磁盘文件:从所有的本地目录中轮训查找能存储这么大空间的目录,找到之后在其中创建一个类似于“spill12.out”的文件。Spill线程根据排过序的Kvmeta挨个partition的把数据吐到这个文件中,一个partition对应的数据吐完之后顺序地吐下个partition,直到把所有的partition遍历完。一个partition在文件中对应的数据也叫段(segment)。在这个过程中如果用户配置了combiner类,那么在写之前会先调用combineAndSpill(),对结果进行进一步合并后再写出。Combiner会优化MapReduce的中间结果,所以它在整个模型中会多次使用。那哪些场景才能使用Combiner呢?Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果。所以从我的想法来看,Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。比如累加,最大值等。Combiner的使用一定得慎重,如果用好,它对job执行效率有帮助,反之会影响reduce的最终结果。
(5)Merge
Map任务如果输出数据量很大,可能会进行好几次Spill,out文件和Index文件会产生很多,分布在不同的磁盘上。最后把这些文件进行合并的merge过程闪亮登场。
Merge过程怎么知道产生的Spill文件都在哪了呢?从所有的本地目录上扫描得到产生的Spill文件,然后把路径存储在一个数组里。Merge过程又怎么知道Spill的索引信息呢?没错,也是从所有的本地目录上扫描得到Index文件,然后把索引信息存储在一个列表里。到这里,又遇到了一个值得纳闷的地方。在之前Spill过程中的时候为什么不直接把这些信息存储在内存中呢,何必又多了这步扫描的操作?特别是Spill的索引数据,之前当内存超限之后就把数据写到磁盘,现在又要从磁盘把这些数据读出来,还是需要装到更多的内存中。之所以多此一举,是因为这时kvbuffer这个内存大户已经不再使用可以回收,有内存空间来装这些数据了。(对于内存空间较大的土豪来说,用内存来省却这两个io步骤还是值得考虑的。)
Reduce shuffle
在Reduce端,shuffle主要分为复制Map输出、排序合并两个阶段。
(1)Copy
Reduce任务通过HTTP向各个Map任务拖取它所需要的数据。Map任务成功完成后,会通知父TaskTracker状态已经更新,TaskTracker进而通知JobTracker(这些通知在心跳机制中进行)。所以,对于指定作业来说,JobTracker能记录Map输出和TaskTracker的映射关系。Reduce会定期向JobTracker获取Map的输出位置,一旦拿到输出位置,Reduce任务就会从此输出对应的TaskTracker上复制输出到本地,而不会等到所有的Map任务结束。
(2)Merge Sort
Copy过来的数据会先放入内存缓冲区中,如果内存缓冲区中能放得下这次数据的话就直接把数据写到内存中,即内存到内存merge。Reduce要向每个Map去拖取数据,在内存中每个Map对应一块数据,当内存缓存区中存储的Map数据占用空间达到一定程度的时候,开始启动内存中merge,把内存中的数据merge输出到磁盘上一个文件中,即内存到磁盘merge。在将buffer中多个map输出合并写入磁盘之前,如果设置了Combiner,则会化简压缩合并的map输出。Reduce的内存缓冲区可通过mapred.job.shuffle.input.buffer.percent配置,默认是JVM的heap size的70%。内存到磁盘merge的启动门限可以通过mapred.job.shuffle.merge.percent配置,默认是66%。
当属于该reducer的map输出全部拷贝完成,则会在reducer上生成多个文件(如果拖取的所有map数据总量都没有内存缓冲区,则数据就只存在于内存中),这时开始执行合并操作,即磁盘到磁盘merge,Map的输出数据已经是有序的,Merge进行一次合并排序,所谓Reduce端的sort过程就是这个合并的过程。一般Reduce是一边copy一边sort,即copy和sort两个阶段是重叠而不是完全分开的。最终Reduce shuffle过程会输出一个整体有序的数据块。
参考:MapReduce基本原理(详解!)_mapreduce工作原理-CSDN博客
Map数设置
Map数是Split机制决定的,Map数过多和过少都会带来问题。
- Split会有10%的buffer来控制尾巴;
- 小文件如果过多,要开启小文件合并,分为输入的合并和输出端合并;
- 如果单个split数据条数过多,处理起来异常缓慢,这个时候要增大map数减少单个map task处理的的数据量,可以通过设置map任务数或者通过中间表用distribute by随机打散的方式来增大。
输入端合并参数设置为:
set hive.hadoop.supports.splittable.combineinputformat=true;
-- 执行map前进行小文件合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
set mapred.min.split.size=100000000;
set mapred.max.split.size=100000000;
-- 一个节点上split的至少的大小 ,决定了多个data node上的文件是否需要合并
set mapred.min.split.size.per.node=50000000;
-- 一个交换机下split的至少的大小,决定了多个交换机上的文件是否需要合并
set mapred.min.split.size.per.rack=50000000;输出端合并mergefiles
set hive.merge.mapfiles=true; --在Map-only的任务结束时合并小文件
set hive.merge.mapredfiles=true; --在Map-Reduce的任务结束时合并小文件
set hive.merge.size.per.task=128000000; --合并后文件的大小为128M左右
set hive.merge.smallfiles.avgsize=128000000; --当输出文件的平均大小小于128M时,启动一个独立的map-reduce任务进行文件merge
map数设置:
set mapred.reduce.tasks=10;map的最终个数取决于goalsize=min(totalsize/mapred.reduce.tasks,块大小),goalsize就相当于splitsize
但是往往这个是不生效的
- 如果hive处理的文件是压缩模式,且压缩模式不支持文件切分,那么这个时候我们只能通过控制参数来减少map个数,而不能通过配置参数来增加map个数,所以Hive对于压缩不可切分文件的调优有限。
那么我们可以利用中间表
create table a_1 as
select * from a
distribute by CAST(RAND() *10 AS INT);这样会将a表的记录,随机的分散到包含10个文件的a_1表中,再用a_1代替上面sql中的a表,则会用10个map任务去完成。每个map任务处理大于12M(几百万记录)的数据,效率肯定会好很多。
看上去,貌似这两种有些矛盾,一个是要合并小文件,一个是要把大文件拆成小文件,这点正是重点需要关注的地方,根据实际情况,控制map数量需要遵循两个原则:使大数据量利用合适的map数;使单个map任务处理合适的数据量。
参考:
【精选】Hive--控制map和reduce的个数(为什么&什么场景设置&如何设置)_韩家小志的博客-CSDN博客
真正让你明白Hive参数调优系列1:控制map个数与性能调优参数_mapred.min.split.size.per.node-CSDN博客
Reduce数设置
Reducer数量通过两种方式进行设置,一种是直接设置但很少使用mapred.reduce.tasks,一种是通过控制最大reducer数量默认1009,和每个reducer处理的数据量来控制,最大reducer数决定了上限,每个reducer处理的数据量决定了下限。
Reducer数量决定了输出文件的数量,过多会产生小文件问题,另外过多的任务导致过多的JVM开启消耗带来性能开销,导致效率不高;如果设置过少,可能会导致数据倾斜,作业耗时时间长,需要结合实际进行设置。
1.set hive.exec.reducers.bytes.per.reducer=256000000 --默认值 256Mb
注意:在hive 0.14.0之前默认hive.exec.reducers.bytes.per.reducer默认值是1Gb,每个reduce最多处理1Gb。
但是在之后版本默认值都是256Mb。为什么256Mb写的是300*1000*1000?因为网络传输中用的1000,而不是1024机制。
2.set hive.exec.reducers.max=1009 --我们公司默认值,这个值一般不会修改。
注意,在hive 0.14.0之前默认是999,之后是1009,所以我们公司的也是官方默认值。
3.reduce计算方式:计算reducer数的公式很简单
Num=min(hive.exec.reducers.max,map输出数据量 / hive.exec.reducers.bytes.per.reducer)
什么情况下只有一个reduce?
很多时候你会发现任务中不管数据量多大,不管你有没有设置调整reduce个数的参数,任务中一直都只有一个reduce任务;其实只有一个reduce任务的情况,除了数据量小于hive.exec.reducers.bytes.per.reducer参数值的情况外,还有以下原因:
- 没有group by的汇总
比如把 select pt,count(1) from table_xxx where pt = '2020-08-11' group by pt;
写成 select count(1) from table_xxx where pt = '2020-08-11'; - 用了Order by
- 有笛卡尔积
- count(distinct xx)
通常这些情况下,除了找办法来变通和避免,我暂时没有什么好的办法,因为这些操作都是全局的,所以hadoop不得不用一个reduce去完成;
同样的,在设置reduce个数的时候也需要考虑这两个原则:使大数据量利用合适的reduce数;使单个reduce任务处理合适的数据量。
参考:
【精选】真正让你明白Hive参数调优系列2:如何控制reduce个数与参数调优_真正让你明白 hive 参数调优:控制 reduce 个数与性能调优参数!-CSDN博客
2.说一下 map join 与 reduce join
Map join
配置:
set hive.auto.convert.join = true(0.11版本后默认是true)
set hive.mapjoin.smalltable.filesize=25000000(设置小表的大小,默认就是25M)
限制:
只适用于inner join
原理:

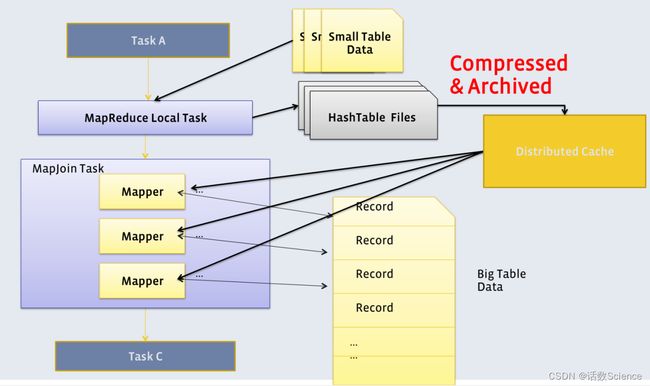
mapjoin :主要用于小表连接大表,一般小表的大小为25M,大表没有什么具体的限制。
使用mapjoin的原因是:
在进行表的连接时,在map端处理完数据后,会把不同表的数据,形成不同的文件,reduce端进行拉取map端获得文件时,由于map端文件不在一个节点 ,且由于表的大小不一,获得的相应的文件也会大小不一,特别是针对相差较大的大小表,更会在数据拉去的时候浪费资源,拖慢job进度。为此引入了mapjoin这种处理手断。
解决:hive会自动选择小表(元数据中有记录),把小表put到各个节点的缓存(Distributed Cache)中,大表在硬盘中(这个和普通表进入map的操作一样)在map中直接与关联表连接,连表操作直接在map中进行,从内存中拉取小表,从硬盘中拉去大表,不需要走reduce,大大节约的时间。提高效率。
Reduce join
原理:
reduce join 又称shuffle join和commen join
他是一个完整的mapreduce过程,包括map阶段、shuffel阶段、reduce阶段,通过这三个阶段完整表的连接
Map阶段
读取源表数据,map输出的数据的key是join 中的on的条件,如果有多个,则一起作为key
map输出的数据的value为join之后所关心的列(select或者where所需的数据),同时还会有tag数据,用于标志数据属于哪个表,同时按key进行排序
Shuffle阶段
根据key的值进行hash,并将key/value按照hash值推送至不同的reduce中,这样确保两个表中相同的key位于同一个reduce中
Reduce阶段
根据key的值完成join操作。
总结
mapjoin主要就是用于连表,现在已经默认开启,一旦hive发现大表和小表,就会走mapjoin ,如果一个小表和大表关联后,也有统计求和等操作 ,也会把数据的放到迭代器中,也要走reduce操作。
总的来说:map就做数据处理,(连表也是一种数据处理)
reduce:根据业务,对数据进行计算,获得我们想要的结果,比如统计,求和等。
3.Hive SQL怎么优化
分组聚合优化
Map端聚合
Hive中未经优化的分组聚合,是通过一个MapReduce Job实现的。Map端负责读取数据,并按照分组字段分区,通过Shuffle,将数据发往Reduce端,各组数据在Reduce端完成最终的聚合运算。
Hive对分组聚合的优化主要围绕着减少Shuffle数据量进行,具体做法是map-side聚合。所谓map-side聚合,就是在map端维护一个hash table,利用其完成部分的聚合,然后将部分聚合的结果,按照分组字段分区,发送至reduce端,完成最终的聚合。map-side聚合能有效减少shuffle的数据量,提高分组聚合运算的效率。
map-side 聚合相关的参数如下:
--启用map-side聚合
set hive.map.aggr=true;
--用于检测源表数据是否适合进行map-side聚合。检测的方法是:先对若干条数据进行map-side聚合,若聚合后的条数和聚合前的条数比值小于该值,则认为该表适合进行map-side聚合;否则,认为该表数据不适合进行map-side聚合,后续数据便不再进行map-side聚合。
set hive.map.aggr.hash.min.reduction=0.5;
--用于检测源表是否适合map-side聚合的条数。
set hive.groupby.mapaggr.checkinterval=100000;
--map-side聚合所用的hash table,占用map task堆内存的最大比例,若超出该值,则会对hash table进行一次flush。
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;Join优化
Hive拥有多种join算法,包括Common Join,Map Join,Bucket Map Join,Sort Merge Buckt Map Join等
1)Common Join
Common Join是Hive中最稳定的join算法,其通过一个MapReduce Job完成一个join操作。Map端负责读取join操作所需表的数据,并按照关联字段进行分区,通过Shuffle,将其发送到Reduce端,相同key的数据在Reduce端完成最终的Join操作。
2)Map Join
Map Join算法可以通过两个只有map阶段的Job完成一个join操作。其适用场景为大表join小表。若某join操作满足要求,则第一个Job会读取小表数据,将其制作为hash table,并上传至Hadoop分布式缓存(本质上是上传至HDFS)。第二个Job会先从分布式缓存中读取小表数据,并缓存在Map Task的内存中,然后扫描大表数据,这样在map端即可完成关联操作。
select
*
from order_detail od
join product_info product on od.product_id = product.id
join province_info province on od.province_id = province.id;| 表名 |
大小 |
| order_detail |
1176009934(约1122M) |
| product_info |
25285707(约24M) |
| province_info |
369(约0.36K) |
--方案一:这样可保证将两个Common Join operator均可转为Map Join operator,并保留Common Join作为后备计划,保证计算任务的稳定
--启用Map Join自动转换。
set hive.auto.convert.join=true;
--不使用无条件转Map Join。
set hive.auto.convert.join.noconditionaltask=false;
--调整hive.mapjoin.smalltable.filesize参数,使其大于等product_info大小
set hive.mapjoin.smalltable.filesize=25285707;
--方案二:可直接将两个Common Join operator转为两个Map Join operator,并且由于两个Map Join operator的小表大小之和小于等于hive.auto.convert.join.noconditionaltask.size,故两个Map Join operator任务可合并为同一个。这个方案计算效率最高,但需要的内存也是最多的。
--启用Map Join自动转换。
set hive.auto.convert.join=true;
--启用无条件转Map Join。
set hive.auto.convert.join.noconditionaltask=true;
--调整hive.auto.convert.join.noconditionaltask.size参数,使其大于等于product_info和province_info之和。
set hive.auto.convert.join.noconditionaltask.size=25286076;
--方案三:这样可直接将两个Common Join operator转为Map Join operator,但不会将两个Map Join的任务合并。该方案计算效率比方案二低,但需要的内存也更少。
--启用Map Join自动转换。
set hive.auto.convert.join=true;
--启用无条件转Map Join。
set hive.auto.convert.join.noconditionaltask=true;
--调整hive.auto.convert.join.noconditionaltask.size参数,使其等于product_info。
set hive.auto.convert.join.noconditionaltask.size=25285707;3)Bucket Map Join
Bucket Map Join是对Map Join算法的改进,其打破了Map Join只适用于大表join小表的限制,可用于大表join大表的场景。
Bucket Map Join的核心思想是:若能保证参与join的表均为分桶表,且关联字段为分桶字段,且其中一张表的分桶数量是另外一张表分桶数量的整数倍,就能保证参与join的两张表的分桶之间具有明确的关联关系,所以就可以在两表的分桶间进行Map Join操作了。这样一来,第二个Job的Map端就无需再缓存小表的全表数据了,而只需缓存其所需的分桶即可。

--关闭cbo优化,cbo会导致hint信息被忽略
set hive.cbo.enable=false;
--map join hint默认会被忽略(因为已经过时),需将如下参数设置为false
set hive.ignore.mapjoin.hint=false;
--启用bucket map join优化功能
set hive.optimize.bucketmapjoin = true;4)Sort Merge Bucket Map Join
Sort Merge Bucket Map Join(简称SMB Map Join)基于Bucket Map Join。SMB Map Join要求,参与join的表均为分桶表,且需保证分桶内的数据是有序的,且分桶字段、排序字段和关联字段为相同字段,且其中一张表的分桶数量是另外一张表分桶数量的整数倍。
SMB Map Join同Bucket Join一样,同样是利用两表各分桶之间的关联关系,在分桶之间进行join操作,不同的是,分桶之间的join操作的实现原理。Bucket Map Join,两个分桶之间的join实现原理为Hash Join算法;而SMB Map Join,两个分桶之间的join实现原理为Sort Merge Join算法。
Hash Join和Sort Merge Join均为关系型数据库中常见的Join实现算法。Hash Join的原理相对简单,就是对参与join的一张表构建hash table,然后扫描另外一张表,然后进行逐行匹配。Sort Merge Join需要在两张按照关联字段排好序的表中进行。
--启动Sort Merge Bucket Map Join优化
set hive.optimize.bucketmapjoin.sortedmerge=true;
--使用自动转换SMB Join
set hive.auto.convert.sortmerge.join=true;任务并行度
Map端并行度
输入端存在大量小文件,可以开启合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;map端存在复杂任务,可以减少数据量
set mapreduce.input.fileinputformat.split.maxsize=256000000;Reduce端并行度
reduce端并行度计算公式:
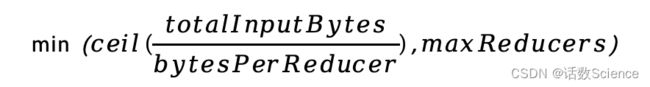
--指定Reduce端并行度,默认值为-1,表示用户未指定
set mapreduce.job.reduces;
--Reduce端并行度最大值
set hive.exec.reducers.max;
--单个Reduce Task计算的数据量,用于估算Reduce并行度
set hive.exec.reducers.bytes.per.reducer;小文件合并
Map端输入文件合并
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;Reduce输出文件合并
--开启合并map only任务输出的小文件
set hive.merge.mapfiles=true;
--开启合并map reduce任务输出的小文件
set hive.merge.mapredfiles=true;
--合并后的文件大小
set hive.merge.size.per.task=256000000;
--触发小文件合并任务的阈值,若某计算任务输出的文件平均大小低于该值,则触发合并
set hive.merge.smallfiles.avgsize=16000000;其他优化
开启CBO,默认开启
--是否启用cbo优化
set hive.cbo.enable=true;开启谓词下推
--是否启动谓词下推(predicate pushdown)优化
set hive.optimize.ppd = true;开启矢量化查询
Hive的矢量化查询,可以极大的提高一些典型查询场景(例如scans, filters, aggregates, and joins)下的CPU使用效率。
set hive.vectorized.execution.enabled=true;Fetch抓取
Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算。例如:select * from emp;在这种情况下,Hive可以简单地读取emp对应的存储目录下的文件,然后输出查询结果到控制台。
--是否在特定场景转换为fetch 任务
--设置为none表示不转换
--设置为minimal表示支持select *,分区字段过滤,Limit等
--设置为more表示支持select 任意字段,包括函数,过滤,和limit等
set hive.fetch.task.conversion=more;本地模式
大多数的Hadoop Job是需要Hadoop提供的完整的可扩展性来处理大数据集的。不过,有时Hive的输入数据量是非常小的。在这种情况下,为查询触发执行任务消耗的时间可能会比实际job的执行时间要多的多。对于大多数这种情况,Hive可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短。
--开启自动转换为本地模式
set hive.exec.mode.local.auto=true;
--设置local MapReduce的最大输入数据量,当输入数据量小于这个值时采用local MapReduce的方式,默认为134217728,即128M
set hive.exec.mode.local.auto.inputbytes.max=50000000;
--设置local MapReduce的最大输入文件个数,当输入文件个数小于这个值时采用local MapReduce的方式,默认为4
set hive.exec.mode.local.auto.input.files.max=10;并行执行
Hive会将一个SQL语句转化成一个或者多个Stage,每个Stage对应一个MR Job。默认情况下,Hive同时只会执行一个Stage。但是某SQL语句可能会包含多个Stage,但这多个Stage可能并非完全互相依赖,也就是说有些Stage是可以并行执行的。此处提到的并行执行就是指这些Stage的并行执行。相关参数如下:
--启用并行执行优化
set hive.exec.parallel=true;
--同一个sql允许最大并行度,默认为8
set hive.exec.parallel.thread.number=8; 严格模式
Hive可以通过设置某些参数防止危险操作:
1)分区表不使用分区过滤
将hive.strict.checks.no.partition.filter设置为true时,对于分区表,除非where语句中含有分区字段过滤条件来限制范围,否则不允许执行。换句话说,就是用户不允许扫描所有分区。进行这个限制的原因是,通常分区表都拥有非常大的数据集,而且数据增加迅速。没有进行分区限制的查询可能会消耗令人不可接受的巨大资源来处理这个表。
2)使用order by没有limit过滤
将hive.strict.checks.orderby.no.limit设置为true时,对于使用了order by语句的查询,要求必须使用limit语句。因为order by为了执行排序过程会将所有的结果数据分发到同一个Reduce中进行处理,强制要求用户增加这个limit语句可以防止Reduce额外执行很长一段时间(开启了limit可以在数据进入到Reduce之前就减少一部分数据)。
3)笛卡尔积
将hive.strict.checks.cartesian.product设置为true时,会限制笛卡尔积的查询。对关系型数据库非常了解的用户可能期望在执行JOIN查询的时候不使用ON语句而是使用where语句,这样关系数据库的执行优化器就可以高效地将WHERE语句转化成那个ON语句。不幸的是,Hive并不会执行这种优化,因此,如果表足够大,那么这个查询就会出现不可控的情况。
参考:
hive中 bucket mapjoin 与 SMB join(Sort-Merge-Bucket)区别_bucketmapjoin-CSDN博客Hive中的map join、left semi join和sort merge bucket join_left join mapjoin-CSDN博客
4.Spark和Hive的区别
正如 spark官网所说,“Apache spark is a unified analytics engine for large-scale data processing.”,spark是一个通用的处理大规模数据的分析引擎,即 spark 是一个计算引擎,而不是存储引擎,其本身并不负责数据存储。其分析处理数据的方式,可以使用sql,也可以使用java,scala, python甚至R等api;其分析处理数据的模式,既可以是批处理,也可以是流处理;而其分析处理的数据,可以通过插件的形式对接很多数据源,既可以是结构化的数据,也可以是半结构化甚至分结构化的数据,包括关系型数据库RDBMS,各种nosql数据库如hbase, mongodb, es等,也包括文件系统hdfs,对象存储oss, s3 等等。
再来看看hive,hive定位是数据仓库,同时又是查询引擎,Spark SQL只是取代的HIVE的查询引擎这一部分。
hive 官网有描述,“Apache Hive data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL.”,hive的定位是数据仓库,其提供了通过 sql 读写和管理分布式存储中的大规模的数据,即 hive即负责数据的存储和管理(其实依赖的是底层的hdfs文件系统或s3等对象存储系统),也负责通过 sql来处理和分析数据。所以说,hive只用来处理结构化数据,且只提供了sql的方式来进行分析处理。
1、hive on spark。在这种模式下,数据是以table的形式存储在hive中的,用户处理和分析数据,使用的是hive语法规范的 hql (hive sql)。 但这些hql,在用户提交执行时,底层会经过解析编译以spark作业的形式来运行。(事实上,hive早期只支持一种底层计算引擎,即mapreduce,后期在spark 因其快速高效占领大量市场后,hive社区才主动拥抱spark,通过改造自身代码,支持了spark作为其底层计算引擎。目前hive支持了三种底层计算引擎,即mr, tez和spark.用户可以通过set hive.execution.engine=mr/tez/spark来指定具体使用哪个底层计算引擎。
2、spark on hive。上文已经说到,spark本身只负责数据计算处理,并不负责数据存储。其计算处理的数据源,可以以插件的形式支持很多种数据源,这其中自然也包括hive。当我们使用spark来处理分析存储在hive中的数据时,这种模式就称为为 spark on hive. 这种模式下,用户可以使用spark的 java/scala/pyhon/r 等api,也可以使用spark语法规范的sql ,甚至也可以使用hive 语法规范的hql (之所以也能使用hql,是因为 spark 在推广面世之初,就主动拥抱了hive,通过改造自身代码提供了原生对hql包括hive udf的支持,这也是市场推广策略的一种吧)。
3、spark + spark hive catalog。这是spark和hive结合的一种新形势,随着数据湖相关技术的进一步发展,这种模式现在在市场上受到了越来越多用户的青睐。其本质是,数据以orc/parquet/delta lake等格式存储在分布式文件系统如hdfs或对象存储系统如s3中,然后通过使用spark计算引擎提供的scala/java/python等api或spark 语法规范的sql来进行处理。由于在处理分析时针对的对象是table, 而table的底层对应的才是hdfs/s3上的文件/对象,所以我们需要维护这种table到文件/对象的映射关系,而spark自身就提供了 spark hive catalog来维护这种table到文件/对象的映射关系。注意这里的spark hive catalog,其本质是使用了hive 的 metasore 相关 api来读写表到文件/对象的映射关系(以及一起其他的元数据信息)到 metasore db如mysql, postgresql等数据库中。(由于spark编译时可以把hive metastore api等相关代码一并打包到spark的二进制安装包中,所以使用这种模式,我们并不需要额外单独安装hive)。
参考:https://www.zhihu.com/question/329052025/answer/1827649633
5.数据倾斜几种解决方式
数据倾斜问题,通常是指参与计算的数据分布不均,即某个key或者某些key的数据量远超其他key,导致在shuffle阶段,大量相同key的数据被发往同一个Reduce,进而导致该Reduce所需的时间远超其他Reduce,成为整个任务的瓶颈。
Hive中的数据倾斜常出现在分组聚合和join操作的场景中,下面分别介绍在上述两种场景下的优化思路。
分组聚合导致的数据倾斜
Map-Side聚合
开启Map-Side聚合后,数据会现在Map端完成部分聚合工作。这样一来即便原始数据是倾斜的,经过Map端的初步聚合后,发往Reduce的数据也就不再倾斜了。最佳状态下,Map-端聚合能完全屏蔽数据倾斜问题。
hive中的map-side聚合是默认开启的
--启用map-side聚合
set hive.map.aggr=true;
--用于检测源表数据是否适合进行map-side聚合。检测的方法是:先对若干条数据进行map-side聚合,若聚合后的条数和聚合前的条数比值小于该值,则认为该表适合进行map-side聚合;否则,认为该表数据不适合进行map-side聚合,后续数据便不再进行map-side聚合。
set hive.map.aggr.hash.min.reduction=0.5;
--用于检测源表是否适合map-side聚合的条数。
set hive.groupby.mapaggr.checkinterval=100000;
--map-side聚合所用的hash table,占用map task堆内存的最大比例,若超出该值,则会对hash table进行一次flush。
set hive.map.aggr.hash.force.flush.memory.threshold=0.9;Skew-GroupBy优化
Skew-GroupBy的原理是启动两个MR任务,第一个MR按照随机数分区,将数据分散发送到Reduce,完成部分聚合,第二个MR按照分组字段分区,完成最终聚合。
--启用分组聚合数据倾斜优化
set hive.groupby.skewindata=true;Join导致的数据倾斜
未经优化的join操作,默认是使用common join算法,也就是通过一个MapReduce Job完成计算。Map端负责读取join操作所需表的数据,并按照关联字段进行分区,通过Shuffle,将其发送到Reduce端,相同key的数据在Reduce端完成最终的Join操作。
如果关联字段的值分布不均,就可能导致大量相同的key进入同一Reduce,从而导致数据倾斜问题。
由join导致的数据倾斜问题,有如下三种解决方案:
1)map join
使用map join算法,join操作仅在map端就能完成,没有shuffle操作,没有reduce阶段,自然不会产生reduce端的数据倾斜。
- 1)该方案适用于大表join小表时发生数据倾斜的场景。
- 2)只适合inner join。
- 3)hive中的map join自动转换是默认开启的。
--启动Map Join自动转换
set hive.auto.convert.join=true;
--一个Common Join operator转为Map Join operator的判断条件,若该Common Join相关的表中,存在n-1张表的大小总和<=该值,则生成一个Map Join计划,此时可能存在多种n-1张表的组合均满足该条件,则hive会为每种满足条件的组合均生成一个Map Join计划,同时还会保留原有的Common Join计划作为后备(back up)计划,实际运行时,优先执行Map Join计划,若不能执行成功,则启动Common Join后备计划。
set hive.mapjoin.smalltable.filesize=250000;
--开启无条件转Map Join
set hive.auto.convert.join.noconditionaltask=true;
--无条件转Map Join时的小表之和阈值,若一个Common Join operator相关的表中,存在n-1张表的大小总和<=该值,此时hive便不会再为每种n-1张表的组合均生成Map Join计划,同时也不会保留Common Join作为后备计划。而是只生成一个最优的Map Join计划。
set hive.auto.convert.join.noconditionaltask.size=10000000;2)skew join
skew join的原理是,为倾斜的大key单独启动一个map join任务进行计算,其余key进行正常的common join。
这种方案对参与join的源表大小没有要求,但是对两表中倾斜的key的数据量有要求,要求一张表中的倾斜key的数据量比较小(方便走mapjoin)。
原理图如下:

--启用skew join优化
set hive.optimize.skewjoin=true;
--触发skew join的阈值,若某个key的行数超过该参数值,则触发
set hive.skewjoin.key=100000;3)调整SQL语句
若参与join的两表均为大表,其中一张表的数据是倾斜的,此时也可通过以下方式对SQL语句进行相应的调整。
select
*
from(
select --打散操作
concat(id,'_',cast(rand()*2 as int)) id,
value
from A
)ta
join(
select --扩容操作
concat(id,'_',0) id,
value
from B
union all
select
concat(id,'_',1) id,
value
from B
)tb
on ta.id=tb.id;s6.数据如何清洗
数据清洗,是数据规范化的一个过程,主要包括
①过滤脏数据、无效数据
②数据格式进行统一
③缺省值处理
④去除重复数据等。
参考:https://wenku.csdn.net/answer/7cr9zmyzc8
7.说一下udf、udtf、udaf ,集成的类、接口,怎么写
UDF
- 输入一行,输出一行

/**
* A Generic User-defined function (GenericUDF) for the use with Hive.
*
* New GenericUDF classes need to inherit from this GenericUDF class.
*
* The GenericUDF are superior to normal UDFs in the following ways: 1. It can
* accept arguments of complex types, and return complex types. 2. It can accept
* variable length of arguments. 3. It can accept an infinite number of function
* signature - for example, it's easy to write a GenericUDF that accepts
* array, array> and so on (arbitrary levels of nesting). 4. It
* can do short-circuit evaluations using DeferedObject.
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
@UDFType(deterministic = true)
public abstract class GenericUDF implements Closeable {
/**
* Initialize this GenericUDF. This will be called once and only once per
* GenericUDF instance.
*
* @param arguments
* The ObjectInspector for the arguments
* @throws UDFArgumentException
* Thrown when arguments have wrong types, wrong length, etc.
* @return The ObjectInspector for the return value
*/
public abstract ObjectInspector initialize(ObjectInspector[] arguments)
throws UDFArgumentException;
/**
* Evaluate the GenericUDF with the arguments.
*
* @param arguments
* The arguments as DeferedObject, use DeferedObject.get() to get the
* actual argument Object. The Objects can be inspected by the
* ObjectInspectors passed in the initialize call.
* @return The
*/
public abstract Object evaluate(DeferredObject[] arguments)
throws HiveException;
/**
* Get the String to be displayed in explain.
*/
public abstract String getDisplayString(String[] children);
/**
* Close GenericUDF.
* This is only called in runtime of MapRedTask.
*/
@Override
public void close() throws IOException {
}
} UDTF
- 输入一行,输出多行
- 往往被lateral view explode + udf等替代实现,比直接用udtf会更简单、直接、更灵活一些。
/**
* A Generic User-defined Table Generating Function (UDTF)
*
* Generates a variable number of output rows for a single input row. Useful for
* explode(array)...
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public abstract class GenericUDTF {
Collector collector = null;
/**
* Initialize this GenericUDTF. This will be called only once per instance.
*
* @param argOIs
* An array of ObjectInspectors for the arguments
* @return A StructObjectInspector for output. The output struct represents a
* row of the table where the fields of the stuct are the columns. The
* field names are unimportant as they will be overridden by user
* supplied column aliases.
*/
@Deprecated
public StructObjectInspector initialize(ObjectInspector[] argOIs)
throws UDFArgumentException {
throw new IllegalStateException("Should not be called directly");
}
/**
* Give a set of arguments for the UDTF to process.
*
* @param args
* object array of arguments
*/
public abstract void process(Object[] args) throws HiveException;
/**
* Called to notify the UDTF that there are no more rows to process.
* Clean up code or additional forward() calls can be made here.
*/
public abstract void close() throws HiveException;
/**
* Passes an output row to the collector.
*
* @param o
* @throws HiveException
*/
protected final void forward(Object o) throws HiveException {
collector.collect(o);
}
}UDAF
- 输入多行,输出一行
- 四个阶段:PARTIAL1(Map阶段)、PARTIAL2(Map的Combiner阶段)、FINAL(Reduce 阶段)、COMPLETE(Map Only阶段)
- 五个方法:初始化init、遍历iterate、合并merge、终止terminatePartial、terminate

Mode详解
PARTIAL1:
* 读取原始数据,聚合部分数据,获得部分聚合结果
* 调用:iterate()、terminatePartial()
* 对应 Map 阶段(不包括Combiner)
PARTIAL2:
* 读取部分聚合结果,再做部分聚合,获得新的部分聚合结果
* 调用:merge()、terminatePartial()
* 对应 Map 的 Combiner 阶段
FINAL:
* 读取部分聚合结果,进行全局聚合,获得全局聚合结果
* 调用:merge()、terminate()
* 对应 Reduce 阶段
COMPLETE:
* 读取原始数据,直接进行全局聚合,获得全局聚合结果 and
* 调用:iterate()、terminate()
* 对应 Map Only 任务,只有 Map 阶段
public abstract class GenericUDAFEvaluator implements Closeable {
/**
* Mode.
*
*/
public static enum Mode {
/**
* PARTIAL1: from original data to partial aggregation data: iterate() and
* terminatePartial() will be called.
*/
PARTIAL1,
/**
* PARTIAL2: from partial aggregation data to partial aggregation data:
* merge() and terminatePartial() will be called.
*/
PARTIAL2,
/**
* FINAL: from partial aggregation to full aggregation: merge() and
* terminate() will be called.
*/
FINAL,
/**
* COMPLETE: from original data directly to full aggregation: iterate() and
* terminate() will be called.
*/
COMPLETE
};
/**
* Initialize the evaluator.
*
* @param m
* The mode of aggregation.
* @param parameters
* The ObjectInspector for the parameters: In PARTIAL1 and COMPLETE
* mode, the parameters are original data; In PARTIAL2 and FINAL
* mode, the parameters are just partial aggregations (in that case,
* the array will always have a single element).
* @return The ObjectInspector for the return value. In PARTIAL1 and PARTIAL2
* mode, the ObjectInspector for the return value of
* terminatePartial() call; In FINAL and COMPLETE mode, the
* ObjectInspector for the return value of terminate() call.
*
* NOTE: We need ObjectInspector[] (in addition to the TypeInfo[] in
* GenericUDAFResolver) for 2 reasons: 1. ObjectInspector contains
* more information than TypeInfo; and GenericUDAFEvaluator.init at
* execution time. 2. We call GenericUDAFResolver.getEvaluator at
* compilation time,
*/
public ObjectInspector init(Mode m, ObjectInspector[] parameters) throws HiveException {
// This function should be overriden in every sub class
// And the sub class should call super.init(m, parameters) to get mode set.
mode = m;
return null;
}
/**
* Get a new aggregation object.
*/
public abstract AggregationBuffer getNewAggregationBuffer() throws HiveException;
/**
* Reset the aggregation. This is useful if we want to reuse the same
* aggregation.
*/
public abstract void reset(AggregationBuffer agg) throws HiveException;
/**
* Iterate through original data.
*
* @param parameters
* The objects of parameters.
*/
public abstract void iterate(AggregationBuffer agg, Object[] parameters) throws HiveException;
/**
* Get partial aggregation result.
*
* @return partial aggregation result.
*/
public abstract Object terminatePartial(AggregationBuffer agg) throws HiveException;
/**
* Merge with partial aggregation result. NOTE: null might be passed in case
* there is no input data.
*
* @param partial
* The partial aggregation result.
*/
public abstract void merge(AggregationBuffer agg, Object partial) throws HiveException;
/**
* Get final aggregation result.
*
* @return final aggregation result.
*/
public abstract Object terminate(AggregationBuffer agg) throws HiveException;
}参考:UDF开发手册 - UDAF - 掘金
8.hive文件存储格式,对比
Hive支持的存储数据的格式主要有:
- 行式存储:TEXTFILE、SEQUENCEFILE
- 列式存储:RCFile、ORC、PARQUET
行存储的特点: 查询满足条件的一整行数据的时候,行存储只需要找到其中一个值,其余的值都在相邻地方。列存储则需要去每个聚集的字段找到对应的每个列的值,所以此时行存储查询的速度更快。
列存储的特点: 因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
TEXTFILE格式
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
AVRO格式
Avro依赖模式(Schema)来实现数据结构定义。可以把模式理解为Java的类,它定义每个实例的结构,可以包含哪些属性。可以根据类来产生任意多个实例对象。对实例序列化操作时必须需要知道它的基本结构,也就需要参考类的信息。这里,根据模式产生的Avro对象类似于类的实例对象。每次序列化/反序列化时都需要知道模式的具体结构。所以,在Avro可用的一些场景下,如文件存储或是网络通信,都需要模式与数据同时存在
Avro的模式主要由JSON对象来表示,它可能会有一些特定的属性,用来描述某种类型(Type)的不同形式。Avro支持八种基本类型(Primitive Type)和六种混合类型(Complex Type)。基本类型可以由JSON字符串来表示。每种不同的混合类型有不同的属性(Attribute)来定义,有些属性是必须的,有些是可选的,如果需要的话,可以用JSON数组来存放多个JSON对象定义。在这几种Avro定义的类型的支持下,可以由用户来创造出丰富的数据结构来,支持用户纷繁复杂的数据。
Avro支持两种序列化编码方式:二进制编码和JSON编码。使用二进制编码会高效序列化,并且序列化后得到的结果会比较小;而JSON一般用于调试系统或是基于WEB的应用。对Avro数据序列化/反序列化时都需要对模式以深度优先(Depth-First),从左到右(Left-to-Right)的遍历顺序来执行。基本类型的序列化容易解决,混合类型的序列化会有很多不同规则。对于基本类型和混合类型的二进制编码在文档中规定,按照模式的解析顺序依次排列字节。对于JSON编码,联合类型(Union Type)就与其它混合类型表现不一致。
Avro为了便于MapReduce的处理定义了一种容器文件格式(Container File Format)。这样的文件中只能有一种模式,所有需要存入这个文件的对象都需要按照这种模式以二进制编码的形式写入。对象在文件中以块(Block)来组织,并且这些对象都是可以被压缩的。块和块之间会存在同步标记符(Synchronization Marker),以便MapReduce方便地切割文件用于处理。
RcFile格式
需在建表是指定stored as rcfile,文件存储方式为二进制文件。以RcFile文件格式存储的表也会对数据进行压缩处理,在HDFS上以二进制格式存储,不可直接查看。
RCFILE是一种行列存储相结合的存储方式,该存储结构遵循的是“先水平划分,再垂直划分”的设计里面。首先,将数据按行分块形成行组,这样可以使同一行的数据在一个节点上。然后,把行组内的数据列式存储,将列维度的数据进行压缩,并提供了一种lazy解压技术。
Rcfile在进行数据读取时会顺序处理HDFS块中的每个行组,读取行组的元数据头部和给定查询需要的列,将其加载到内存中并进行解压,直到处理下一个行组。但是,rcfile不会解压所有的加载列,解压采用lazy解压技术,只有满足where条件的列才会被解压,减少了不必要的列解压。
在rcfile中每一个行组的大小是可变的,默认行组大小为4MB。行组变大可以提升数据的压缩效率,减少并发存储量,但是在读取数据时会占用更多的内存,可能影响查询效率和其他的并发查询。用户可根据具体机器和自身需要调整行组大小。
存储方式:行列混合的存储格式,将相近的行分块后,每块按列存储。
优势:基于列存储,压缩快且效率更高,;占用的磁盘存储空间小,读取记录时涉及的block少,IO小;查询列时,读取所需列只需读取列所在块的头部定义,读取速度快(在读取全量数据时,性能与Sequence没有明显区别);
劣势:无法可视化展示数据;导入数据时耗时较长;不能直接使用load命令对数据进行加载;自身的压缩算法占用一定空间,但比SequenceFile所占空间稍小;
ORC格式
Orc (Optimized Row Columnar)是hive 0.11版里引入的新的存储格式。
可以看到每个Orc文件由1个或多个stripe组成,每个stripe250MB大小,这个Stripe实际相当于RowGroup概念,不过大小由4MB->250MB,这样能提升顺序读的吞吐率。每个Stripe里有三部分组成,分别是Index Data,Row Data,Stripe Footer:
一个orc文件可以分为若干个Stripe
一个stripe可以分为三个部分
- indexData:某些列的索引数据
- rowData :真正的数据存储
- StripFooter:stripe的元数据信息
1)Index Data:一个轻量级的index,默认是每隔1W行做一个索引。这里做的索引只是记录某行的各字段在Row Data中的offset。
2)Row Data:存的是具体的数据,先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个Stream来存储。
3)Stripe Footer:存的是各个stripe的元数据信息
每个文件有一个File Footer,这里面存的是每个Stripe的行数,每个Column的数据类型信息等;每个文件的尾部是一个PostScript,这里面记录了整个文件的压缩类型以及FileFooter的长度信息等。在读取文件时,会seek到文件尾部读PostScript,从里面解析到File Footer长度,再读FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读。
PARQUET格式
Parquet是面向分析型业务的列式存储格式,由Twitter和Cloudera合作开发,2015年5月从Apache的孵化器里毕业成为Apache顶级项目。
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
通常情况下,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。Parquet文件的格式如下图所示。
上图展示了一个Parquet文件的内容,一个文件中可以存储多个行组,文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件,Footer length记录了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息和该文件存储数据的Schema信息。除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据,在Parquet中,有三种类型的页:数据页、字典页和索引页。数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引,目前Parquet中还不支持索引页。
9.内外表区别
内部表&外部表:
未被external修饰的是内部表(managed table),被external修饰的为外部表(external table);
区别:
内部表数据由Hive自身管理,外部表数据由HDFS管理;
内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse),外部表数据的存储位置由自己制定(如果没有LOCATION,Hive将在HDFS上的/user/hive/warehouse文件夹下以外部表的表名创建一个文件夹,并将属于这个表的数据存放在这里);
删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除;对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复。
10.hive执行的job数是怎么确定的
1.通过explain可以清晰的看到stage划分。常见的是各个算子(join groupby orderby 等有shuffle)或者是一些filter where等。
2.基于上面的1就可以划分出stage。但是有些stage并不会执行,或者说经过优化器后的filter where会在其他stage里进行。这样,有些stage就是空的stage。
3.基于stage划分,如何确定job数量(总数就是stage数量)。主要是看哪些stage会执行。只有需要执行的stage才会提交yarn,生成具体的job application ,在日志里就可以看到有很多job并没有执行。
原理
最近面试时我被问到 Hive 是如何划分 stage (阶段)的。
简明扼要的讲,就是以执行这个 Operator 时,它所依赖的数据是否已经“就绪”为标准。
一个 Hive 任务会包含一个或多个 stage,不同的 stage 间会存在着依赖关系,越复杂的查询通常会引入越多的 stage (而 stage 越多就需要越多的时间时间来完成)。
用户提交的 Hive QL 经过词法、语法解析后得到 AST 。语义分析器遍历 AST 抽象出 QueryBlock 。逻辑计划生成器遍历 QueryBlock ,将它们翻译为 Operator(这些 Operator 就是 Hive 对计算抽象出来的算子)生成 OperatorTree 。逻辑计划优化器对 OperatorTree 进行变换,得到优化后的 OperatorTree (即重写了逻辑执行计划)。物理计划生成器遍历 OperatorTree ,翻译为用计算引擎作业任务描述的物理执行计划 TaskTree 。物理计划优化器再对 TaskTree 进行变换,生成最终物理执行计划,以提交给计算引擎执行。
(总结:通过语法解析得到AST,再语义分析得到QueryBlock,再经过逻辑计划生成器得到OperatorTree,最后再经过物理执行计划生成器得到TaskTree,最后再交给计算引擎进行执行)
Hive 支持 MapReduce、Tez 、Spark 等计算引擎,可以将逻辑算子转换成对应计算引擎的物理任务。
stage 的划分发生在物理计划生成器将 OperatorTree 转化为 TaskTree 的阶段。基本上是按深度优先遍历 OperatorTree ,根据计算引擎的 Compiler 的规则,生成相应的 Task 。
一个 stage 可以是一个 MapReduce 任务(或者一个 Map Reduce Local Work),也可以是一个抽样阶段,或者一个合并阶段,还可以是一个 limit 阶段,以及 Hive 需要的其他某个任务的一个阶段。默认情况下,Hive 会一次只执行一个 stage ,当然如果使用了并行执行,也可以同时执行几个没有依赖关系的 stage 。
并不是所有列在 explain 计划里的 stage 都会真正执行的,有些 stage 经过优化器优化后实际上是空的 stage 。观察执行日志,经常可以发现如 "Stage-3 is filtered out by condition resolver" 之类的记录。
参考:
Hive 如何划分 Stage
Hive stage划分_hive job划分的区别-CSDN博客
hive stage job等划分_hive执行的job数是怎么确定的-CSDN博客
调优
Hive产生的MR Job默认是顺序执行的,如果Job之间无依赖可以并行执行,比如最外层是UNION ALL连接的SQL。
set hive.exec.parallel=true;参考:大数据开发之Hive优化篇8-Hive Job优化 - 知乎
11.cube、grouping sets、grouping__id
WITH CUBE
根据GROUP BY的维度的所有组合进行聚合。
以group by user_id, city_id with rollup为例,其使用的组合为:all、(user_id)、(city_id)、(user_id, city_id)
WITH data AS
(
SELECT 1 AS user_id
,1 AS city_id
,'2023-02-01' AS `time`
UNION ALL
SELECT 1 AS user_id
,2 AS city_id
,'2023-11-01' AS `time`
UNION ALL
SELECT 2 AS user_id
,3 AS city_id
,'2023-10-31' AS `time`
UNION ALL
SELECT 2 AS user_id
,2 AS city_id
,'2023-11-02' AS `time`
UNION ALL
SELECT 2 AS user_id
,3 AS city_id
,'2023-11-01' AS `time`
)
SELECT user_id
,city_id
,COUNT(1) AS cnt
FROM data
GROUP BY user_id
,city_id
WITH CUBE
;
WITH ROLLUP
为CUBE的子集,以最左侧的维度为主,从该维度进行层级聚合。
以group by user_id, city_id with rollup为例,其使用的组合为:all、(user_id)、(user_id, city_id)
WITH data AS
(
SELECT 1 AS user_id
,1 AS city_id
,'2023-02-01' AS `time`
UNION ALL
SELECT 1 AS user_id
,2 AS city_id
,'2023-11-01' AS `time`
UNION ALL
SELECT 2 AS user_id
,3 AS city_id
,'2023-10-31' AS `time`
UNION ALL
SELECT 2 AS user_id
,2 AS city_id
,'2023-11-02' AS `time`
UNION ALL
SELECT 2 AS user_id
,3 AS city_id
,'2023-11-01' AS `time`
)
SELECT user_id
,city_id
,COUNT(1) AS cnt
FROM data
GROUP BY user_id
,city_id
WITH ROLLUP
;
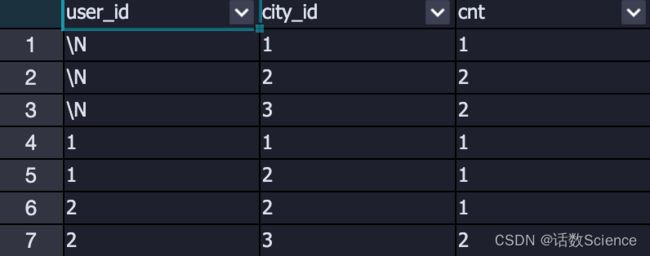
GROUPING SETS
- 在一个GROUP BY查询中,根据不同的维度组合进行聚合,等价于将不同维度的GROUP BY结果集进行UNION ALL,grouping_sets是一种将多个group by 逻辑写在一个sql语句中的便利写法。
- GROUPING__ID,表示结果属于哪一个分组集合。
WITH data AS
(
SELECT 1 AS user_id
,1 AS city_id
,'2023-02-01' AS `time`
UNION ALL
SELECT 1 AS user_id
,2 AS city_id
,'2023-11-01' AS `time`
UNION ALL
SELECT 2 AS user_id
,3 AS city_id
,'2023-10-31' AS `time`
UNION ALL
SELECT 2 AS user_id
,2 AS city_id
,'2023-11-02' AS `time`
UNION ALL
SELECT 2 AS user_id
,3 AS city_id
,'2023-11-01' AS `time`
)
SELECT user_id
,city_id
,COUNT(1) AS cnt
FROM data
GROUP BY user_id
,city_id
GROUPING SETS ((city_id),(user_id,city_id))
;
grouping__id
SET odps.sql.hive.compatible = true
;
WITH data AS
(
SELECT 1 AS user_id
,1 AS city_id
,'2023-02-01' AS `time`
UNION ALL
SELECT 1 AS user_id
,2 AS city_id
,'2023-11-01' AS `time`
UNION ALL
SELECT 2 AS user_id
,3 AS city_id
,'2023-10-31' AS `time`
UNION ALL
SELECT 2 AS user_id
,2 AS city_id
,'2023-11-02' AS `time`
UNION ALL
SELECT 2 AS user_id
,3 AS city_id
,'2023-11-01' AS `time`
)
SELECT GROUPING__ID
,user_id
,city_id
,COUNT(1) AS cnt
FROM data
GROUP BY user_id
,city_id
GROUPING SETS ((city_id),(user_id,city_id))
;
grouping_id计算方法
grouping sets 中的每一种粒度,都对应唯一的 grouping__id 值,其计算公式与 group by 的顺序、当前粒度的字段有关。
具体计算方法如下:
- 将 group by 的所有字段 倒序 排列。
- 对于每个字段,如果该字段出现在了当前粒度中,则该字段位置赋值为1,否则为0。
- 这样就形成了一个二进制数,这个二进制数转为十进制,即为当前粒度对应的 grouping__id。
举例grouping sets class, sex, (class, sex) 的3种粒度的统计结果为例:
group by 的所有字段倒序排列为:sex class
对于 3 种 grouping sets,分别对应的二进制数为:
序号 grouping set 给倒序排列的字段(sex class)赋值 对应的十进制(grouping__id 的值)
1 class 01 1
2 sex 10 2
3 class,sex 11 3
示例:group by c1,c2,c3 grouping sets(c1,c2,c3)
grouping__id:
0: ()
1:(c1)
2:(c2)
3:(c1,c2)
4:(c3)
5:(c1,c3)
6:(c2,c3)
7:(c1,c2,c3)
通过实践,每种组合的id已注定,不受grouping sets()中先后影响,但会受group by中key的先后影响,把c1与c2调换位置,那么结果中的grouping__id也会改变。
12. Order by、Sort by、Distribute by、Cluster by的区别
- Order by 只会产生一个reducer,全局排序。
- Sort by只保证每个reducer内部是有序的,并不保证全局有序。
- Distribute by需要结合Sort By来使用按照指定的字段把数据分散到不同的reduce里面去,相当于进行了partition分区只不过生成的是不同的文件而不是目录。
- Cluster by是Distribute by 加 Sort By的简写,并且Distribute by 加 Sort By是同一个key,且只支持升序。
13.小文件如何优化?
小文件产生的场景
- 动态分区插入数据的时候,会产生大量的小文件;
- 数据源本身就包含有大量的小文件;
- 做增量导入,比如Sqoop数据导入,一些增量insert等;
- 分桶表,分桶表通常也会遇到小文件,本质上还是增量导入的问题;
- 可以修改的表,这种Hive表是可以进行修改的,通过配置
stored as orc TBLPROPERTIES ("transactional"="true"),这种表最坑,每天都会有一个快照,到后面10G大小的数据,表文件体积可以达到600G,时间越长越大;
小文件的危害
- 从Hive的角度看,小文件会开很多map,一个map开一个JVM去执行,所以这些任务的初始化,启动,执行会浪费大量的资源,严重影响性能。
- 在HDFS中,每个小文件对象约占150byte,如果小文件过多会占用大量内存。这样NameNode内存容量严重制约了集群的稳定性。
动态分区产生小文件
采用动态分区参数设置和减少map和reduce数量并且加上使用distribute by cast(rand()*N as int) 随机分发的策略很好的解决集群小文件问题,起到了优化的作用。
对于使用SparkSQL的用户来说,SparkSQL提供了repartition算子来解决这一问题,在这里其实repartition和distribute by的作用一致
参考:
解决Hive动态分区小文件过多问题_hive文件分区多导致cpu不足-CSDN博客
彻底解决Hive小文件问题 - 知乎【精选】Hive Distribute by 应用之动态分区小文件过多问题优化_动态分区为什么会产生小文件_莫叫石榴姐的博客-CSDN博客