《高性能mysql》之查询性能优化(第六章)
①请求了多余数据:
-- 查出全部结果集:若数据库有1000行数据,但
仅需10行,决解办法
LIMIT 10
-- 取出所有列:取数据时取出不必要列
SELECT * FROM test;
X
SELECT id,name FROM test; 对,假设仅需执行获取id和name
-- 查询重复数据:如用户头像需多次取出,此时应将数据缓存起来
②重构查询方式:
-- 复杂查询切换为简单查询
-- 切分查询:

注:将大量数据
删除分批次,
减小对服务器的
压力(如:删除过期账号的存储过程如何编写)
-- 分解关联查询:

优势:
缓存效率更高,单个查询减少
锁的竞争,查询
效率提升,减少
冗余查询记录,易实现
哈希
③查询执行基础:

④查询优化器局限性:
-- 关联子查询:
IN()用于子查询性能特别糟,要么分解,要么改EXISTS 如下:

-- UNION的限制:合并多个结果集
-- 索引合并优化:多个独立索引自动合并成联合索引
-- 等值传递:非常大的IN()列表会带来额外的消耗
-- 并行执行:mysql无法利用多核来并行执行查询
-- 哈希关联:自定义的哈希关联
-- 松散索引扫面:mysql5.6后版本支持
-- 最大值和最小值优化:
优化后:

注:这个策略尽可能少的扫面数目
-- 在同一表上查询更新:mysql不允许在同一表上同时查询和更新
⑤查询优化器提示:
-- HIGH_PRORITY、LOW_PRIORITY:调整sql语句优先级
-- DELAYED:日志系统-用于大量写入且客户端不需要等待单条I/O完成
-- STRAIGHT_JOIN:减少优化器的搜索时间
-- SQL_SMALL_RESULT、SQL_BIG_RESULT:告诉优化器对group by、distinct使用内存临时表/磁盘临时表
-- SQL_BUFFER_RESULT:结果放在临时表并尽快释放,服务器需要更多内存
-- SQL_CACHE、SQL_NO_CACHE:结果是否存在查询缓存
-- FOR UPDATE、LOCK IN SHARE MODE:排它锁、共享锁
-- USE INDEX、IGNORE INDEX、FORCE INDEX:使用或不使用哪些索引
注:对于新版本(5.5及以上)的mysql有相关优化策略,往往自己随意使用会导致相关优化策略
失效
⑥优化特定类型的查询:
-- 优化COUNT():
简单优化:
SELECT COUNT(*) FROM world where id>5; 改为--->
SELECT (SELECT COUNT(*) FROM world) - COUNT(*) FROM world where id<=5;
查询多个总数:
SELECT COUNT(color='red' OR NULL) as red, COUNT(color='blue' OR NULL) as blue
FROM world;
-- 优化关联查询:
无特殊要求,仅在关联查询的第二个表中间索引
关联查询中在GROUP BY、ORDER BY最好仅涉及一个表的列
-- 优化子查询:子查询尽可能用关联查询替代
-- 优化GROUP BY、DISTINCT:
使用关联查询时仅使用表标识分组效率更高
·

-- 优化LIMIT分页:偏移量大时,limit分页会进行全表扫描
针对limit,延迟关联:
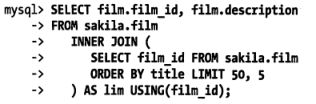
将limit改为between:
记录上次查询标识,然后加入where