Hadoop集群搭建教程
环境:
centos 6.5 (ip:192.168.80.100、192.168.80.101)
jdk 1.7
hadoop 2.8.4
| ip |
进程 |
| 192.168.80.100(master) |
namenode |
| 192.168.80.101(slave) |
datanode |
创建hadoop用户(2个节点均要创建):
$ su -
# useradd -m hadoop
# passwd hadoop
#visudo
为hadoop添加hadoop权限,在root ALL=(ALL)ALL下添加一行:
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
切换回hadoop:
su hadoop
设置hosts,避免直接使用ip(两个节点均要设置):
在/etc/hosts修改如下:
127.0.0.1 master master
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.80.100 master master
192.168.80.101 slave1
为了方便,将三个节点分别设置如下hostname(重启会失效):
sudo hostname master
sudo hostname slave1
ssh免密登录设置(以下操作在master集器进行):
$ ssh-keygen //全部默认回车
$ ssh-copy-id -i ~/.ssh/id_rsa.pub 192.168.80.101 //https://jingyan.baidu.com/article/c74d6000b499160f6a595de6.html
然后在master节点使用以下测试是否成功:
$ ssh 192.168.80.101
安装JDK:
参考此文:https://blog.csdn.net/qq_28666081/article/details/81629764
安装hadoop:
先配置master 192.168.80.100,然后scp拷贝到slave。
$ cd
$ wget http://apache.fayea.com/hadoop/common/hadoop-2.8.4/hadoop-2.8.4.tar.gz
$ tar -zxvf hadoop-2.8.4.tar.gz
$ mv hadoop-2.8.4 hadoop
hadoop 的master节点配置:
需要配置六个文件(目录均在hadoop/etc/hadoop下):
core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、slaves、hadoop-env.sh
1 配置core-site.xml
fs.default.name
hdfs://192.168.80.100:9000
hadoop.tmp.dir
file:/home/hadoop/hadoop/tmp
2 配置hdfs-site.xml
dfs.replication
2
dfs.namenode.name.dir
file:/home/hadoop/hadoop/tmp/dfs/name
dfs.datanode.data.dir
file:/home/hadoop/hadoop/tmp/dfs/data
dfs.namenode.secondary.http-address
192.168.80.100:9001
dfs.namenode.datanode.registration.ip-hostname-check
false
3 配置mapred-site.xml
$ mv mapred-site.xml.template mapred-site.xml
mapreduce.framework.name
yarn
4 配置yarn-site.xml
yarn.resourcemanager.hostname
192.168.80.100
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
5 配置slaves
192.168.80.101
注:如果是多个,则添加多行ip。
6 配置hadoop-env.sh,修改java_home为对应地址
export JAVA_HOME=/usr/lib/java/jdk1.7.0_40
其他子节点slave配置:
此步依旧是在master节点操作
$ scp -r ~/hadoop [email protected]:~/
配置当前用户hadoop环境变量(每个节点都要配置):
$ vim ~/.bashrc
$ source ~/.bashrc
$ echo $HADOOP_HOME //输出看看是否生效
启动hadoop:
$ hdfs namenode -format //格式化hdfs
$ hadoop/sbin/start-all.sh
注:这里遇到一个错误,修改/etc/hosts的127.0.0.1 master master,本教程配置已经修复,参考链接是http://lihongchao87.iteye.com/blog/1998347。
在master节点输入jps
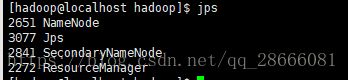
在slave1节点输入jps

然后输入http://192.168.80.100:50070/dfshealth.html#tab-overview:
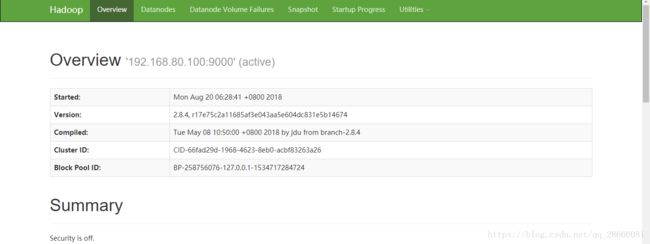
以上就安装成功了,如要测试则以下地址:https://blog.csdn.net/chenyuangege/article/details/45582831
注:如果遇到测试失败可删掉hadoop/tmp/dfs,然后重新格式化hdfs后再启动试试。
参考文档:
https://www.cnblogs.com/pcxie/p/7747317.html
https://blog.csdn.net/chenyuangege/article/details/45582831