基于华为云DLI服务和MLS服务的房价预测任务
基于华为云DLI服务和MLS服务的房价预测任务
参考:
华为云AI+大数据学习营DLI服务高阶课程
1. DLI服务与MLS服务说明
DLI官网地址:https://support.huaweicloud.com/productdesc-dli/dli_07_0001.html ,数据湖探索(Data Lake Insight,DLI)是完全托管的大数据处理分析服务。用户不需要管理任何服务器,即开即用。支持标准SQL,兼容SparkSQL,支持多种接入方式,并兼容主流数据格式。数据无需复杂的抽取、转换、加载,使用SQL或Spark程序就可以对华为云上CloudTable、RDS、DWS等异构数据进行探索。
根据我的实验了解,DLI服务提供了一种简单的数据库连接功能,使得开发者可以快速的访问存在云上的数据,同时兼备数据转换功能,比如从OBS上的CSV导入到数据库再导出。
MLS官网地址:https://support.huaweicloud.com/productdesc-mls/zh-cn_topic_user_guide.html ,机器学习服务(Machine Learning Service,简称MLS)是一项数据挖掘分析平台服务,旨在帮助用户通过机器学习技术发现已有数据中的规律,从而创建机器学习模型,并基于机器学习模型处理新的数据,为业务应用生成预测结果。
机器学习服务可降低机器学习使用门槛,提供可视化的操作界面来编排机器学习模型的训练、评估和预测过程,无缝衔接数据分析和预测应用,降低机器学习模型的生命周期管理难度,为用户的数据挖掘分析业务提供易用、高效、高性能的平台服务。
我的理解是MLS服务给非机器学习专业人士提供了一种简单易使用的图形化操作的平台,首先封装好了各种机器学习算法,以图形化节点的形式给出,用户仅需要添加各种节点(输入,输出,模型,数据处理等)就可以完成模型训练以及预测任务。
2. 任务分析
任务来源于Kaggle入门 房价预测比赛,任务描述很简单,我们需要根据给出的许多属性来预测这个房子的售价,关于属性的具体描述,需要去官网查看,这里就不多说了。
我们基于华为云完成这个比赛的流程是:
- 获取数据;
- 使用Python对数据进行初步清洗;
- 上传数据至华为云OBS进行存储;
- 使用DLI SQL将数据导入到DLI;
- 使用DLI SQL对数据进行进一步分析筛选;
- 导出筛选后的数据;
- 使用MLS服务创建房价预测模型;
- 使用MLS销售预测模型训练数据;
- 使用MLS销售预测模型预测数据。
3. 数据源及初步处理
首先从kaggle上下载数据集,解压后会得到4个文件,分别是data_description.txt,sample_submission.csv,test.csv,train.csv。第一个文件是对数据集中的各种属性特征的描述,第二个文件是上传结果的样本,后面的是需要预测的数据集和训练数据集,测试集比训练集少一列房屋售价SalePrice。我们暂时不做上传结果的这部分,仅将训练集划分出一部分数据作为验证集。
得到数据集后,用Python读取并分析
首先使用Pandas加载数据集,用head查看前10条记录
import pandas as pd
df = pd.read_csv('./train.csv')
df.head(10)
大致情况如下,由于总计有81列,所以显示不完整,但基本了解了数据构成,第一列是Id,最后一列是SalePrice,中间部分列的数据类型是数字和字符串,还有很多NaN空数据。

接下来需要清除脏数据,一般来说脏数据包括空数据,错误存储的数据以及没有意义的数据,错误存储指的是属性值错误(一般较少),没有意义的数据指的是如果大部分数据该列都是一样的值,那么这一列是毫无意义的,我们这里仅对空数据进行处理,空数据的处理方式有多种,比如直接删除带有空数据的记录,或者按照平均值赋给空数据,这里我选择简单的删除空数据记录。在删除记录前还需要进行特征筛选,及删除NaN出现次数过多的特征列。
na_series = df.isnull().sum()
for col_name in na_series.index:
if na_series[col_name] > 200:
df = df.drop(columns=col_name, axis=1)
print(col_name)
通过df.isnull().sum()可以获得所有列中空数据的个数,做一个简单判断,若空数据个数超过200,那么删除此列,最终删除了LotFrontage,Alley,FireplaceQu,PoolQC,Fence,MiscFeature,但是还是有很多列有几十个空数据,那么简单的把这些记录删除
df_without_na = df.dropna(axis=0)
df_without_na.describe()
最终我们的总记录数为1338,比原始1460仅少了一百多个,下图仅显示出数值特征的数据统计,也就是说在剩余的75列中有37列数值,剩下的都是字符串特征

保存结果
df_without_na.to_csv('./result.csv', index=False)
4. 上传至OBS并使用DLI筛选
将result.csv文件上传至OBS,再打开DLI服务创建数据库,数据队列,按照下图方式生成数据表house_price_result

这里有75列,如果用SQL语句要写一会,我直接导入列信息,而且暂时所有特征都按照string类型处理,表建好后,使用SQL语句查看一下数据
SELECT * FROM house_price_result
大致结果如下,且数据记录条数与上面相对应
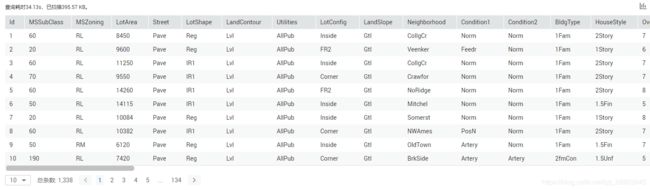
然后建一个空表用于保存我们希望筛选出的数据,这里我遇到了一些问题,比如DLI SQL语句似乎不支持DROP COLUMN删除指定列的操作,以及后面在MLS服务中会遇到特征名不能以数字开头,因此我就简单的把所有数值特征列筛选出来,放弃字符串特征,同时修改几个特征的名称1stFlrSF 2ndFlrSF 3SsnPorch修改为FirstFlrSF SecondFlrSF ThSsnPorch,而且Id列没有意义,因此也删除。
空表建立参照上一步
INSERT INTO house_price_output
SELECT MSSubClass,LotArea,OverallQual,OverallCond,YearBuilt,
YearRemodAdd,MasVnrArea,BsmtFinSF1,BsmtFinSF2,BsmtUnfSF,
TotalBsmtSF,1stFlrSF AS FirstFlrSF,2ndFlrSF AS SecondFlrSF,LowQualFinSF,GrLivArea,
BsmtFullBath,BsmtHalfBath,FullBath,HalfBath,BedroomAbvGr,
KitchenAbvGr,TotRmsAbvGrd,Fireplaces,GarageYrBlt,GarageCars,
GarageArea,WoodDeckSF,OpenPorchSF,EnclosedPorch,3SsnPorch AS ThSsnPorch,
ScreenPorch,PoolArea,MiscVal,MoSold,YrSold,SalePrice
FROM house_price_result
再查看一下筛选后的数据
SELECT * FROM house_price_output

然后将筛选得到的数据导出到本地并重命名为train_data.csv,再手动将其中随机选择10条数据保存到另一个文件test_data.csv。
5. 使用MLS服务训练及预测
购买MLS实例,创建项目mls_house_price,模板为销售预测,在文件系统上上传上面生成的两个csv文件,一个用于训练,另一个作为验证,然后开始工作流配置。
5.1 读取训练数据
这里选中表头
5.2 修改元数据
先删除默认的几个,然后会自动生成元数据类型,我们将最后一个SalePrice改为Target,这里其实可以自行更正,但是属性太多了,我就不改了,一般需要判断是否为连续值和离散值,离散值又分为有序和无序

5.3 数据拆分

没有做修改
5.4 模型选择
默认是随机森林,可以运行成功,但是后来我选了XGBoost,保存模型时失败,最后又选了线性模型,可以成功
5.5 模型保存及应用
模型保存需要命名,应用选择回归任务。
最后运行成功会得到一个模型文件,根据文件配置预测任务
5.6 读取预测模型
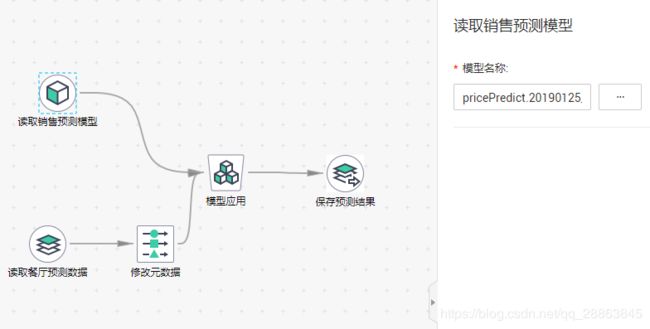
5.7 读取预测数据
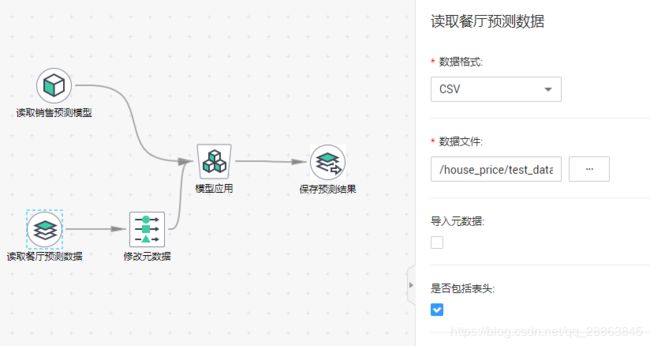
5.8 定义元数据
同上面的训练数据,类型判断错误没关系,可以输出结果

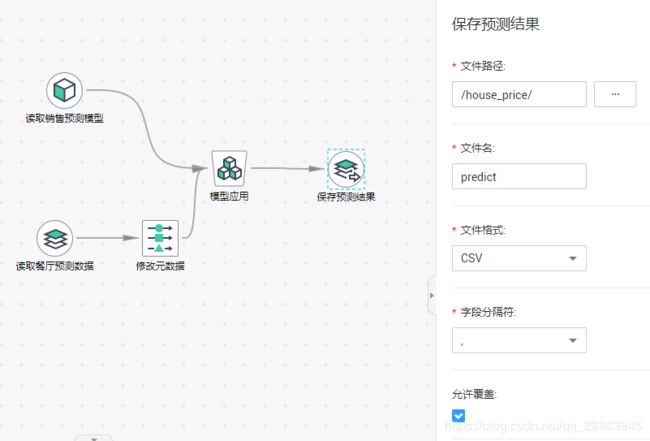
5.9 保存预测结果
6. 结果及分析
验证集
60,13005,7,7,1980,1980,278,692,0,153,845,1153,1200,0,2353,1,0,2,1,4,1,10,1,1983,2,484,288,195,0,0,0,0,0,8,2009,260000
60,9000,8,5,2006,2006,0,0,0,1088,1088,1088,871,0,1959,0,0,2,1,3,1,8,1,2006,3,1025,208,46,0,0,0,0,0,12,2007,270000
60,9900,7,5,1993,1993,256,987,0,360,1347,1372,1274,0,2646,1,0,2,1,4,1,9,1,1993,3,656,340,60,144,0,0,0,0,4,2009,260000
80,14115,7,5,1980,1980,225,1036,0,336,1372,1472,0,0,1472,1,0,2,0,3,1,6,2,1980,2,588,233,48,0,0,0,0,0,6,2009,187500
60,16259,9,5,2006,2006,370,0,0,1249,1249,1249,1347,0,2596,0,0,3,1,4,1,9,0,2006,3,840,240,154,0,0,0,0,0,9,2006,342643
线性回归结果
60,16259,9,5,2006,2006,370,0,0,1249,1249,1249,1347,0,2596,0,0,3,1,4,1,9,0,2006,3,840,240,154,0,0,0,0,0,9,2006,342643,-3921777.404949966
60,13005,7,7,1980,1980,278,692,0,153,845,1153,1200,0,2353,1,0,2,1,4,1,10,1,1983,2,484,288,195,0,0,0,0,0,8,2009,260000,-3698731.5733633195
60,9000,8,5,2006,2006,0,0,0,1088,1088,1088,871,0,1959,0,0,2,1,3,1,8,1,2006,3,1025,208,46,0,0,0,0,0,12,2007,270000,-3014153.4134126855
60,10380,7,5,1986,1987,172,28,1474,0,1502,1553,1177,0,2730,1,0,2,1,4,1,8,1,1987,2,576,201,96,0,0,0,0,0,8,2007,301000,-3464773.5649124403
80,14115,7,5,1980,1980,225,1036,0,336,1372,1472,0,0,1472,1,0,2,0,3,1,6,2,1980,2,588,233,48,0,0,0,0,0,6,2009,187500,-973062.4298654792
这里产生了负数,真的是搞笑,这个模型可能出了很大的问题
随机森林结果
60,16259,9,5,2006,2006,370,0,0,1249,1249,1249,1347,0,2596,0,0,3,1,4,1,9,0,2006,3,840,240,154,0,0,0,0,0,9,2006,342643,369091.7578908035
60,13005,7,7,1980,1980,278,692,0,153,845,1153,1200,0,2353,1,0,2,1,4,1,10,1,1983,2,484,288,195,0,0,0,0,0,8,2009,260000,226257.40506458003
60,9000,8,5,2006,2006,0,0,0,1088,1088,1088,871,0,1959,0,0,2,1,3,1,8,1,2006,3,1025,208,46,0,0,0,0,0,12,2007,270000,263466.3077210762
60,10380,7,5,1986,1987,172,28,1474,0,1502,1553,1177,0,2730,1,0,2,1,4,1,8,1,1987,2,576,201,96,0,0,0,0,0,8,2007,301000,243418.1221194175
80,14115,7,5,1980,1980,225,1036,0,336,1372,1472,0,0,1472,1,0,2,0,3,1,6,2,1980,2,588,233,48,0,0,0,0,0,6,2009,187500,196635.50777727485
随机森林的结果为正数,但是与验证数据对比,差距还是很大,分析原因,首先我们没有使用任何字符串属性,因此损失了相当一部分信息,另一个是对数值属性的分类,仅依靠自动化分,有些属性应该是需要被作为连续值处理,或者离散值,但是没有检查,因此最终效果非常不好。
虽然这一次预测结果并不是很令人满意,但是从另一方面也发现了使用华为云服务可以进行kaggle部分比赛,比较适合没有大量计算资源的学生党吧,而且在实验过程中,能够分析出更进一步完善此项目的方法,后期可能会对这个实验进行完善以达到一个相对较好的结果。