SSD目标检测:tensorflow 版本调试以及出现错误的解决方法
这里分享一下我在进行复现目标检测算法 SSD-Tensorflow 版本的调试经验。
首先贴上论文链接:SSD: Single Shot MultiBoxDetector
Tensorflow 版本的Code Link:SSD-TF版
1 调试过程
1.1 明确代码结构
这里使用的 SSD-Tensorflow 版本有明晰的结构,在github的ReadMe部分也可以清晰的看懂但是有一些细节需要提示一下。【注意:全文均在Linux上进行程序实验,如果是Windows系统也可以借鉴一般来讲Window系统跑程序比在Linux简单,主要我们熟悉】
首先来看下下载的代码结构:
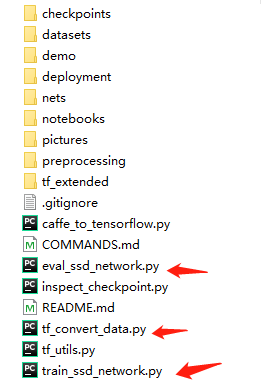
由以上结构可以很明显的看清楚每个文件夹是做什么的,这里我们主要进行调试的部分是红色箭头指的部分。当然还有一些数据预处理部分。
1.1.1 数据格式
数据要转变为 Pascal VOC 数据的格式,因为程序里已经写好了VOC数据对应的预处理代码,我们就可以直接对我们自己的数据进行转化为 VOC 数据格式,具体可以看下图:

一个原生的数据集如何变成这样的格式,可以自行搜索,其实很简单,主要是搞清楚这个格式每个文件夹以及文件有什么用处【如上图,我有标注,有不懂的,欢迎讨论】。
1.1.2 数据转换为 TFRecord 格式
这个步骤主要是对应代码中的 【tf_convert_data.py】在转换格式的时候。
1 我们首先要改变【pascalvoc_common.py】中的一些代码,改变如下:

有人会比较疑惑,我的数据集是 *.jpg 后缀结尾的,这里需不需要改,答案是不需要,因为在TFRecord
生成图像数据的时候只可以解码 JPEG, PNG, GIF, or BMP格式的, *.jpg结尾的属于JPEG格式,所以这里不用改。 
2 然后再说一下 【pascalvoc_2012.py】和 【pascalvoc_2007.py】这两个代码打开后发现其实是类似的,不同的是,VOC2012 和 VOC2007 的 VOC_LABELS 和 VOC_NUM不同,作者可能将测试的数据放入了,【pascalvoc_2007.py】,在我们进行处理的时候,可以在任意一个文件下建立我们的数据字典。我的实验就是放在 2012下做的。将里面的 TRAIN/TEST_STATISTICS 对应生成自己的就行。然后再修改一下 NUM_CLASSES。
3 最后在SSD-Tensorflow-master文件夹下创建tf_conver_data.sh,文件写入内容如下:
DATASET_DIR=./Your Dataset_Dir/ #数据保存的文件夹(保持与VOC的目录格式相同)
OUTPUT_DIR=./tfrecords #自己建立的保存tfrecords数据的文件夹
python ./tf_convert_data.py \
--dataset_name=pascalvoc \
--dataset_dir=${DATASET_DIR} \
--output_name=*_train \ #这里可以自定义为自己的训练数据名字
--output_dir=${OUTPUT_DIR}
4 然后修改 sh 文件的可执行权限 chmod a+x tf_conver_data.sh, 运行 ./tf_conver_data.sh 就可以得到 tfrecord 格式的数据。

1.2 开始训练
1.2.1 修改 train_ssd_network.py


其他的可以结合自己情况酌情修改,
另外还有在 ssd_vgg_*.py 中的参数部分要将 num_classes,以及 no_annotation_label 改为种类数+1
只修改这两处就可以跑起来程序。
1.2.2 建立 train_ssd_network.sh
DATASET_DIR=./tfrecords/
TRAIN_DIR=./train_model/
CHECKPOINT_PATH=./checkpoints/vgg_16.ckpt
python ./train_ssd_network.py \
--train_dir=./train_model/ \ #训练生成模型的存放路径
--dataset_dir=./tfrecords_/ \ #数据存放路径
--dataset_name=pascalvoc_2012 \ #数据名的前缀
--dataset_split_name=train \
--model_name=ssd_300_vgg \ #加载的模型的名字
--checkpoint_path=./checkpoints/vgg_16.ckpt \ #所加载模型的路径
--checkpoint_model_scope=vgg_16 \ #所加载模型里面的作用域名
--checkpoint_exclude_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box \
--trainable_scopes=ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box \
--save_summaries_secs=60 \ #每60s保存一下日志
--save_interval_secs=600 \ #每600s保存一下模型
--weight_decay=0.0005 \ #正则化的权值衰减的系数
--optimizer=adam \ #选取的最优化函数
--learning_rate=0.001 \ #学习率
--learning_rate_decay_factor=0.94 \ #学习率的衰减因子
--batch_size=24 \
--gpu_memory_fraction=0.9 #指定占用gpu内存的百分比
然后 修改 sh 文件的可执行权限 chmod a+x train_ssd_network.sh
就可以运行起来:
调试异常以及解决方案
1 InvalidArgumentError (see above for traceback): Default MaxPoolingOp only supports NHWC on device type CPU[[Node: ssd_300_vgg/pool1/MaxPool = MaxPoolT=DT_FLOAT, data_format=“NCHW”, ksize=[1, 1, 2, 2], padding=“SAME”, strides=[1, 1, 2, 2], _device="/job:localhost/replica:0/task:0/device:CPU:0"]]
解决方法:you can modify the code ‘NCHW’ as ‘NHWC’
参考链接:https://github.com/balancap/SSD-Tensorflow/issues/226
2 SSD输出mAP时出现TypeError: Can not convert a tuple into a Tensor or Operation
解决方法为在eval_ssd_network.py文件中添加下面一个函数:
def flatten(x):
result = []
for el in x:
if isinstance(el, tuple):
result.extend(flatten(el))
else:
result.append(el)
return result
然后修改两行代码:
将 eval_op=list(names_to_updates.values())
改为 eval_op=flatten(list(names_to_updates.values()))
注意:共有两行!
3 ssd测试mAP的时候出现tensorflow版本问题,问题 _variable_v2_call() got an unexpected keyword argument ‘collections’
这个问题是Tensorflow 版本太高导致的,我原来使用的 1.13.1 的版本不行,换成了 1.10.1就可以了
4 All bounding box coordinates must be in [0.0, 1.0]: 1.13308
这个很明显是我们的 xml 文件标注有问题。要么就是左上角坐标大于了右上角坐标,要么就是坐标超出了图片的大小。可以使用以下程序进行检测数据集中的问题数据。
def detecXML(xmlPath):
file_list=os.listdir(xmlPath)
count=0
out_img_wrongCount=0
lb_b_tr_wrongCount=0
for file in file_list:
xml_name=os.path.join(xmlPath,file)
img_file_path = os.path.join(imgPath, file.split('.')[0] + '.jpg')
if os.path.exists(xml_name):
count+=1
tree = et.parse(xml_name)
root = tree.getroot()
for size in root.findall('size'):
width = float(size.find('width').text)
height = float(size.find('height').text)
depth = float(size.find('depth').text)
for obj in root.findall('object'):
bbox = obj.find('bndbox')
bbox_x1 = float(bbox.find('xmin').text)
bbox_y1 = float(bbox.find('ymin').text)
bbox_x2 = float(bbox.find('xmax').text)
bbox_y2 = float(bbox.find('ymax').text)
if bbox_x1<0 or bbox_x2>width or bbox_y1<0 or bbox_y2>height:
print("-"*20)
print("out the img the wrong xml_file is ",xml_name)
print("="*20)
out_img_wrongCount+=1
break
if bbox_x1>bbox_x2 or bbox_y1>bbox_y2:
print("-" * 20)
print("lb beyond tr the wrong xml_file is ", xml_name)
print("=" * 20)
lb_b_tr_wrongCount += 1
break**
5 assertion failed: [Unable to decode bytes as JPEG, PNG, GIF, or BMP]
这是因为图像数据集出了问题,虽然数据集中图片的后缀都是 .jpg 但是有些图片本质上不是 JPEG(或者 PNG, GIF, or BMP)格式的数据造成的,所以这就需要我们把数据的格式统一,这里我是把数据统一为 JPEG格式,下面的代码是检测不合格格式的图片和改写为JPEG格式的脚本。
import imghdr
import cv2
import os
def detectJPEG(path):
img_list=os.listdir(path)
num=0
count=0
start=time.time()
for img_file in img_list:
img_path=os.path.join(path,img_file)
if os.path.exists(img_path):
count+=1
file_type=imghdr.what(img_path)
# print(file_type)
if file_type!='jpeg':
num+=1
print(num,"the wrong jpg:",img_path,"the wrong type:",file_type)
#将不合格的图片读取再写回就行了
img = cv2.imread(img_path)
cv2.imwrite(
os.path.join(path,img_file),
img)
print("succcess writing",num)
print("total count:",count,"the wrong:",num,"the time :",time.time()-start)
以上就是我的 SSD-Tensoflow 版本的调试过程,有问题欢迎指出!谢谢!!