vivo 推荐算法、机器学习面经整理
一面
1:简单叙述卷积神经网络前向传播和反向传播过程
卷积、激活函数、池化、全连接
2:deep&wide网络结构,结合项目说(实习项目)
推荐系统在电商等平台使用广泛,这里讨论wide&deep推荐模型,初始是由google推出的,主要用于app的推荐。
- 概念理解
Wide & Deep模型,旨在使得训练得到的模型能够同时获得记忆(memorization)和泛化(generalization)能力:
记忆(memorization)即从历史数据中发现item或者特征之间的相关性。
泛化(generalization)即相关性的传递,发现在历史数据中很少或者没有出现的新的特征组合。
具体到模型定义角度,wide是指广义线性模型(Wide Linear Model)deep是指深度神经网络(Deep Netural Network)
模型结构图如下:

两者区别:
Memorization趋向于更加保守,推荐用户之前有过行为的items。相比之下,generalization更加趋向于提高推荐系统的多样性(diversity)。
Wide & Deep包括两部分:线性模型 + DNN部分。结合上面两者的优点,平衡memorization和generalization。
- 模型训练
训练方法是用mini-batch stochastic optimization。
Wide部分是用FTRL(Follow-the-regularized-leader) + L1正则化学习。
Deep部分是用AdaGrad来学习
- Embedding维度大小
在Deep模型中需要将稀疏矩阵进行embedding,Wide&Deep的作者指出,从经验上来讲Embedding层的维度大小可以用公式来确定:
n是原始维度上特征不同取值的个数;k是一个常数,通常小于10.
3:有监督和无监督算法都有哪些,大概讲讲
有监督:linear model、logisit model、决策树、随机森林、朴素贝叶斯、KNN、SVM
无监督:kmeans、PCA
4:做两个算法题,手写图的最短路径,自己设计结构;手写heapsort;
图的最短路径:dijkstra
#include
#include
#include
using namespace std;
const int N = 501;
const int inf = 0x7fffffff;
int edge[501][501], disp[501];
bool vst[501];
int main() {
fill(edge[0], edge[0] + N*N, inf);
fill(disp, disp + N, inf);
fill(vst, vst + N, false);
int n, m, s, d;
cin >> n >> m >> s >> d;
for (int i = 0; i int a, b, c; cin >> a >> b >> c; edge[a][b] = edge[b][a] = c; } disp[s] = 0; for (int i = 0; i int u = -1, min = inf; for (int j = 0; j if (disp[j] < min && vst[j] == false) { min = disp[j]; u = j; } } if (u == -1) break; vst[u] = true; for (int v = 0; v if(edge[u][v] != inf){//这句一定要保证 if (disp[v] > disp[u] + edge[u][v] && vst[v] == false) { disp[v] = disp[u] + edge[u][v]; } } } } printf("%d", disp[d]); return 0; } 手写heapsort #include using namespace std; void shift(int arr[],int low,int high){ int i=low,j=2*i; int temp = arr[i]; while(j<=high){ while(j < high && arr[j+1]>arr[j]) j++; if(temp < arr[j]){ arr[i] = arr[j]; i = j; j = 2*i; }else break; } arr[i] = temp; } void heapSort(int arr[],int n){ for(int i=n/2;i>=1;i--)//建堆 shift(arr,i,n); for(int i=n;i>=2;i--){ int temp = arr[1]; arr[1] = arr[i]; arr[i] = temp; shift(arr,1,i-1); } } int main(){ int arr[] = {0,43,65,6,43,78,342,78,34};//从下标一开始 heapSort(arr,8); for(int i=1;i<=8;i++) cout< return 0; } 5:做过nlp相关的项目吗? 用词嵌入做心情预测demo vivo面试经历-一面+二面-推荐算法工程师 社招 https://blog.csdn.net/a1066196847/article/details/86549572 vivo人工智能推荐算法岗提前批面试 卷积、池化、激活函数、全连接层 3.深度学习项目中过拟合的问题?怎么解决?样本不平衡问题?怎么解决? 解决过拟合: L1、L2正则化,droupOut随机失活,early stopping,数据集扩增(Data augmentation) 1. 采样 采样方法是通过对训练集进行处理使其从不平衡的数据集变成平衡的数据集,在大部分情况下会对最终的结果带来提升。采样分为过采样和欠采样,过采样是把小众类复制多份,欠采样是从大众类中剔除一些样本,或者说只从大众类中选取部分样本。 随机采样最大的优点是简单,但缺点也很明显。过采样后的数据集中会反复出现一些样本,训练出来的模型会有一定的过拟合;而欠采样的缺点显而易见,那就是最终的训练集丢失了数据,模型只学到了总体模式的一部分。 二叉树层次遍历: /* struct TreeNode { int val; struct TreeNode *left; struct TreeNode *right; TreeNode(int x) : val(x), left(NULL), right(NULL) { } };*/ class Solution { public: vector vector if(root == nullptr) return res; queue que.push(root); while(!que.empty()){ TreeNode *cur = que.front(); res.push_back(cur->val); que.pop(); if(cur->left != nullptr) que.push(cur->left); if(cur->right != nullptr)//注意是if que.push(cur->right); } return res; } }; 二叉树分层遍历: /* struct TreeNode { int val; struct TreeNode *left; struct TreeNode *right; TreeNode(int x) : val(x), left(NULL), right(NULL) { } }; */ class Solution { public: vector vector if(pRoot == nullptr) return res; stack s1.push(pRoot); while(!s1.empty() || !s2.empty()){ vector if(!s1.empty()){ while(!s1.empty()){ TreeNode *p = s1.top(); vec.push_back(p->val); s1.pop(); if(p->left != nullptr) s2.push(p->left); if(p->right != nullptr) s2.push(p->right); } res.push_back(vec); }else if(!s2.empty()){ while(!s2.empty()){ TreeNode *p = s2.top(); vec.push_back(p->val); s2.pop(); if(p->right != nullptr)//注意这里是先指向right s1.push(p->right); if(p->left != nullptr) s1.push(p->left); } res.push_back(vec); } } return res; } }; 0-1背包问题 递归定义最优解的值 根据上述分析的最优解的结构递归地定义问题最优解。设c[i,w]表示背包容量为w时,i个物品导致的最优解的总价值,得到下式。显然要求c[n,w]。 //knapsack.cpp : 定义控制台应用程序的入口点 #include #include #include using namespace std; /* 0-1 背包问题(迭代版) 输入: products_count:商品的数量 capacity:背包的容量 weight_array:商品重量数组 value_array:商品价格数组 result:结果数组 */ int knapsack(int products_count,int capacity,vector for(int i=1;i<=products_count;i++){//i个物品 for(int j=1;j<=capacity;j++){//背包容量为j if(weights[i] > j){//当前背包的容量 j 放不下第 i 件商品时 res[i][j] = res[i-1][j]; }else { res[i][j] = max( res[i-1][j-weights[i]] + values[i] , res[i-1][j]); } } } return res[products_count][capacity]; } int main(){ int products_count,capacity; cout << "please input products count and knapsack's capacity: " << endl; // 输入商品数量和背包容量 cin>>products_count>>capacity; vector vector cout << "please input weight array for " << products_count << " products" << endl; for(int i=1;i<=products_count;i++) cin>>weights[i]; cout << "please input value array for " << products_count << " products" << endl; for(int i=1;i<=products_count;i++) cin>>values[i]; vector knapsack(products_count,capacity,weights,values,res); cout << "knapsack result is " << res[products_count][capacity] << endl; return 0; } 3.算法题:如何判断单链表中是否有环? 用快慢指针 typedef struct LNode{ int data; struct LNode *next; }LNode; LNode *HasCircal(LNode *head){ if(head == nullptr || head->next == nullptr) return nullptr; LNode *slow,*fast; slow = head->next; fast = head->next->next; while(slow != nullptr && fast != nullptr){ if(slow == fast) return slow; slow = slow->next; if(fast->next == nullptr) return nullptr; fast = fast->next->next; } return nullptr; } LNode *FindEnter(LNode *head){ LNode *node = HasCircal(head);//相交的点 if(node == nullptr) return nullptr; LNode *slow,*fast; slow = head; fast = node; while(slow != fast){ slow = slow->next; fast = fast->next; } return slow; } 4.机器学习中L1和L2范数各有什么特点以及相应的原因? 机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作-norm和-norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数。 原文:https://blog.csdn.net/rocling/article/details/90290576 L1范数是指向量中各个元素绝对值之和 L2范数是指向量各元素的平方和然后求平方根 L1范数可以进行特征选择,即让特征的系数变为0. L2范数可以防止过拟合,提升模型的泛化能力,有助于处理 condition number不好下的矩阵(数据变化很小矩阵求解后结果变化很大) (核心:L2对大数,对outlier离群点更敏感!) 下降速度:最小化权值参数L1比L2变化的快 模型空间的限制:L1会产生稀疏 L2不会。 L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。 vivo 人工智能工程师面经 1.bp算法介绍,梯度弥散问题。 https://blog.csdn.net/LHWorldBlog/article/details/80822741 梯度弥散: (一)初始化权重使用he_initialization (二)使用不饱和激活函数解决单边抑制:Relu、Leaky Relu (三)利用Batch Normalization 2.lr与线性回归的区别 https://blog.csdn.net/qq_38328378/article/details/81349922 线性回归与逻辑回归是机器学习中比较基础又很常用的内容。线性回归主要用来解决连续值预测的问题,逻辑回归用来解决分类的问题,输出的属于某个类别的概率,工业界经常会用逻辑回归来做排序。 LR和SVM的联系: 都是监督的分类算法 都是线性分类方法 (不考虑核函数时) 都是判别模型 判别模型和生成模型是两个相对应的模型。 判别模型是直接生成一个表示或者的判别函数(或预测模型) 生成模型是先计算联合概率分布然后通过贝叶斯公式转化为条件概率。 LR和SVM的不同: 1、损失函数的不同 LR是cross entropy SVM的损失函数是最大化间隔距离 逻辑回归方法基于概率理论,假设样本为1的概率可以用sigmoid函数来表示,然后通过极大似然估计的方法估计出参数的值 支持向量机基于几何间隔最大化原理,认为存在最大几何间隔的分类面为最优分类面 Xgboost、Random Forest、Linear Regression、CART 4.如果要预测房价,并且知道一个房间的房型信息,如何构建模型 5.sigmoid 函数的应用有哪些,为什么? 6.列举十种常用的神经网络模型 GoogleNet、ResNet、LSTM 机器学习的基础问题,比如梯度消失和弥散,由于在梯度消失问题中聊到了resNet,所以就根据resNet聊了起来 https://blog.csdn.net/a1066196847/article/details/86549572 如何画roc曲线?为什么使用Roc和Auc评价分类器? 针对一个二分类问题,将实例分成正类(postive)或者负类(negative)。但是实际中分类时,会出现四种情况. (1)若一个实例是正类并且被预测为正类,即为真正类(True Postive TP) (2)若一个实例是正类,但是被预测成为负类,即为假负类(False Negative FN) (3)若一个实例是负类,但是被预测成为正类,即为假正类(False Postive FP) (4)若一个实例是负类,但是被预测成为负类,即为真负类(True Negative TN) TP:正确的肯定数目 FN:漏报,没有找到正确匹配的数目 FP:误报,没有的匹配不正确 TN:正确拒绝的非匹配数目 列联表如下,1代表正类,0代表负类: vivo-AI算法-19内推面试 vivo 一面 自我介绍 1.算法题:Top k 有哪些算法,时间复杂度分别是多少 2.对于树模型的理解? (1)决策树: 基于信息增益,对应ID3算法。选择信息增益最大的属性值 基于信息增益比,对应C4.5算法。 (2)随机森林 (3)CART (4)GBDT 3.GBDT和Xgboost的区别
主要的面试问题有:
1.RNN的正向传播公式 
2.CNN的正向传播公式
4.二叉树层次遍历,分层遍历。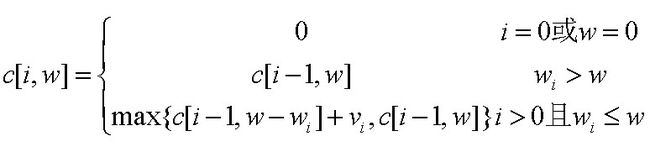
vivo机器学习算法工程师视频一、二面面经
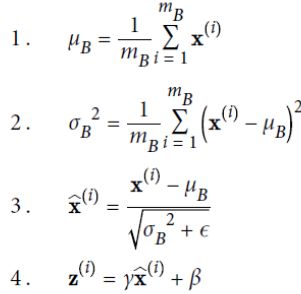
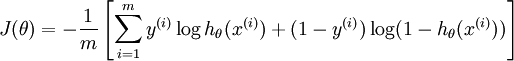
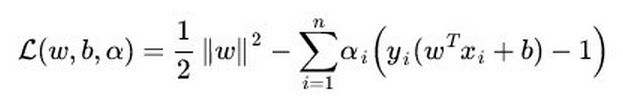
vivo面试经历-一面+二面-推荐算法工程师 社招
