论文阅读笔记《Ranking Sentences for Extractive Summarization with Reinforcement Learning》
文章目录
- 0 摘要
- 1 介绍
- 2 通过句子排序进行自动摘要
- 2.1 句子编码器(sentence encoder)
- 2.2 文档编码器(document encoder)
- 2.3 句子抽取器(sentence extractor)
- 3 交叉熵损失的陷阱
- 4 使用强化学习进行句子排序
- 4.1 策略学习(Policy Learning)
- 4.2 使用高概率样本进行训练
- 5 实验
- 5.1 摘要数据集
- 5.2 实现细节
- 6 结果
- 7 相关工作
- 8 结论
转载请注明原文出处
0 摘要
此文将抽取式单文档摘要概念化为句子排序任务并且提出了一种新颖的训练算法:通过强化学习对ROUGE度量进行全局优化, 使用这个算法训练了一个在CNN/Daily Mail数据集上的抽取式摘要模型。
这个模型通过自动验证与人工验证,达到了2018年的state-of-the-art
1 介绍
自动文摘是个应用化很广泛潜力很大的方向,得益于许多应用场景,例如:
帮助用户导航和消化网页内容(新闻,社交媒体,产品评论等), 问题回答, 个性化推荐引擎
而单文档摘要是自动文摘领域最基本的任务
单文档摘要的现代化方法是数据驱动的,得益于神经网络的学习连续特征能力的强大,无需使用预处理工具或语言注释等步骤
生成式摘要:包括各种文本重写操作(例如替换,删除,重新排序), 并且最近被构造为seq2seq问题
最近两年许多模型的中心思想都是用RNN建模一个编码-解码架构: 编码器将源序列读入连续空间表示的列表,解码器从该列表生成目标序列, 而且在解码时经常使用注意力机制
抽取式摘要:最近两年的论文大多把它做成序列标注任务,用神经网络来导出文档的含义表示,再用这个来标注句子是否应该被保留。这些模型通常使用交叉熵损失函数以最大化得出训练标注结果的可能性,不过因为它们缺少对句子重要程度排名的目标,它们没有对句子按重要性程度进行排序(个人不同意这句话,至少SummaRuNNer的作者就做了这个工作)
此文作者观点是对于抽取式摘要,以交叉熵作为损失函数不是最佳选择,作者认为这个损失函数容易造成信息冗余,生成过长的摘要
作者提出解决办法是让模型学习对句子排序,通过强化学习目标来对ROUGE度量进行全局优化,这个神经网络摘要模型由分层文档编码器(encoder)和分层句子提取器(extractor)组成。在训练期间,它将最大似然交叉熵损失与policy gradient强化学习的奖励相结合,直接优化与摘要任务相关的评估指标。
结果显示在CNN/Daily Mail新闻重点数据集上,就ROUGE度量而言,此模型达到新的state-of-the-art(超越以前的抽取式与生成式模型的最优结果)
作者的人工评估方法很有意思,他们有两个人工评估步骤:
a) 参与者更喜欢哪种类型的摘要结果(比较抽取式、生成式)
b) 参与者觉得摘要中保留了原文里多少关键信息
此文的三个贡献:
- 一个新颖的强化学习应用方法: 强化学习作用于句子排序来做抽取式自动摘要
- 分析与实验结果证实,交叉熵不太适用于自动摘要任务
- 大规模用户研究表明,目前最先进的摘要式系统落后于最先进的抽取式系统
2 通过句子排序进行自动摘要
文档 D D D由句子序列 ( s 1 , s 2 , ⋯ , s n ) (s_1, s_2, \cdots, s_n) (s1,s2,⋯,sn)组成, 抽取式系统的目标是通过从 D D D中选择 m m m个句子( m < n m<n m<n)生成摘要 S S S: 对于每个句子 s i ∈ D s_i \in D si∈D, 生成一个预测标注 y i ∈ { 0 , 1 } y_i \in \{0, 1\} yi∈{0,1}。这里 y i y_i yi为1代表句子被保留在摘要中,为0代表不保留。通过 p ( y i ∣ s i , D , θ ) p(y_i | s_i, D, \theta) p(yi∣si,D,θ)来定量 s i s_i si要保留到摘要中这件事的相关度。
如果 s i s_i si的相关性比 s j s_j sj的相关性更高,这个模型对这两个句子的分配分数就会是 p ( 1 ∣ s i , D , θ ) > p ( 1 ∣ s j , D , θ ) p(1 | s_i, D, \theta) > p(1 | s_j, D, \theta) p(1∣si,D,θ)>p(1∣sj,D,θ), θ \theta θ表示模型参数。这个模型会把得分最高的 m m m个句子保留下来作为摘要 S S S。
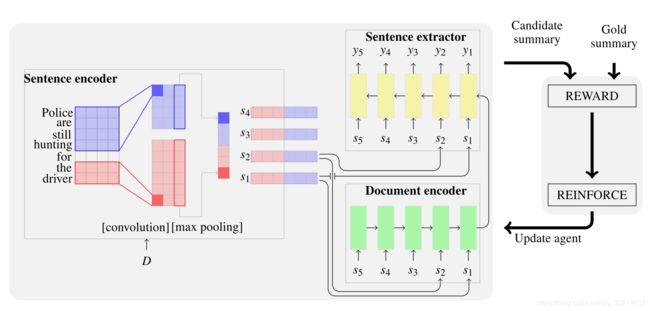
模型组成: 句子编码器(sentence encoder),文档编码器(document encoder),句子提取器(sentence extractor)
2.1 句子编码器(sentence encoder)
最近几年,CNN(Convolutional Neural Network)被证实适用于多种NLP任务,因为CNN识别显著的输入模式牛逼。比如在自动文摘的案例中,CNN可以识别与人工生成的摘要相关的命名实体识别和事件。
模型使用temporal narrow convolution(大名鼎鼎的TCN):一个宽度为 h h h的kernel filter K K K(它用一个大小为 h h h个词的窗口,从句子 s s s中去提取特征)。
这个filter会产生一个feature map: f ∈ R k − h + 1 f \in R^{k-h+1} f∈Rk−h+1, 这里 k k k是句子 s s s的长度(准确点说是句子的词数)
然后加一个max-pooling到feature map上去,将最大值作为特定滤波器的特征。
作者使用多个kernel,每个kernel扫描多次来构建句子的表示。
在下图中,大小为2的红色的kernel与大小为4的蓝色的kernel每个都被应用了3次。
max-pooling随着时间的推移产生两个特征列表 f K 2 , f K 4 ∈ R 3 f^{K_2}, f^{K_4} \in \bold{R}^3 fK2,fK4∈R3。
最终的句子嵌入拥有6个维度。
2.2 文档编码器(document encoder)
文档编码器说白了就是组合句子序列来获得文档的表示。通常训练长序列时,用LSTM网络来避免梯度消失问题。
给定由句子序列 ( s 1 , s 2 , ⋯ , s n ) (s_1, s_2, \cdots, s_n) (s1,s2,⋯,sn)组成的文档 D D D,作者遵循通常的处理办法,用相反的顺序将句子送入模型中。通过这种办法可以确保这个网络一直在考虑着文档中对于摘要特别重要的句子。
2.3 句子抽取器(sentence extractor)
句子抽取器用0或1序列化地标注文档中的每个句子,通过带softmax层的LSTM网络实现。在时刻 t i t_i ti, 它读入句子 s i s_i si并且通过从文档编码器获得的文档表示以及之前的被标注地句子综合考虑,做出一个二分类预测。通过这种方式,句子抽取器能识别文档中的局部重要句及全局重要句。再对句子抽取器中的softmax层分配的置信分数 p ( y i = 1 ∣ s i , D , θ ) p(y_i=1 | s_i, D, \theta) p(yi=1∣si,D,θ)进行排序。
作者通过强化学习框架对句子进行排序,直接优化最终的评估度量: ROUGE
在作者描述我们的训练算法之前,他想先在第3部分详细说明为什么最大似然交叉熵目标可能不足以对摘要的句子进行排序,然后在第4部分定义强化学习的目标函数,并且表明他们的训练方式将允许模型更好地区分句子,即如果句子经常出现在高得分的摘要中,则句子将在选择中的排名更高。
整个模型架构如下图:
3 交叉熵损失的陷阱
之前的工作通过最大化 p ( y ∣ D , θ ) = ∏ i = 1 n p ( y i ∣ s i , D , θ ) p(y|D,\theta) = \prod_{i=1}^n p(y_i | s_i, D, \theta) p(y∣D,θ)=∏i=1np(yi∣si,D,θ) ,即给定文档 D D D与模型参数 θ \theta θ, 最大化句子序列 ( s 1 , s 2 , ⋯ , s n ) (s_1, s_2, \cdots, s_n) (s1,s2,⋯,sn)的训练标注 y = ( y 1 , y 2 , ⋯ , y n ) y = (y_1, y_2, \cdots, y_n) y=(y1,y2,⋯,yn)的似然。
这个目标可以通过最小化每个解码步骤的交叉熵损失达成:
(1) L ( θ ) = − ∑ i = 1 n log p ( y i ∣ s i , D , θ ) L(\theta) = -\sum_{i=1}^n\log p(y_i | s_i, D, \theta) \tag{1} L(θ)=−i=1∑nlogp(yi∣si,D,θ)(1)
交叉熵训练导致模型中出现两种 不符合(discrepancies) :
- 第一个不符合源自任务定义与训练目标的脱节(disconnect):公式(1)中的最大似然估计旨在最大化ground truth的似然,然而模型的任务是 a) 对句子进行排名以生成摘要 和 b)在测试时刻使用ROUGE进行评估
- 第二个不符合来源于对ground truth标签的依赖:用于训练摘要系统的文档集合不会自然地包含标签(暗示某个句子是否应该被保留),相反,它们通常都是人工生成的摘要中进行推断得出的 (这个理由,个人真的觉得很有见地,不应该对标签过度依赖):
Cheng和Lapata(2016)遵循Woodsend和Lapata(2010)采用基于规则的方法,根据与人工生成的摘要的语义对应,分别为文档中的每个句子分配标签。
另一种方法是(Svore et al., 2007; Cao et al., 2016; Nallapati et al., 2017)采用的方法: 识别能达到最高的ROUGE度量的句子集合(collectively),这个集合中的句子被标为1,其余的标为0。
单独标记句子通常会产生太多的为1的标签,导致模型过度拟合数据。举例,下表中的文档(一共31句话,只显示了头10句)竟然有12个被标为正的句子。集体标签(collective labels) 提供了更好的选择,因为它们仅涉及被认为最适合形成摘要的少数句子。然而,一个使用交叉熵在集体标签上训练出来的模型会欠拟合(under-fit),因为它们只会最大化在集合中的句子的概率并忽略所有其它的句子。其实在训练过程中有许多合适的句子会取得比较高的ROUGE分数,这些候选句也应该被考虑到。
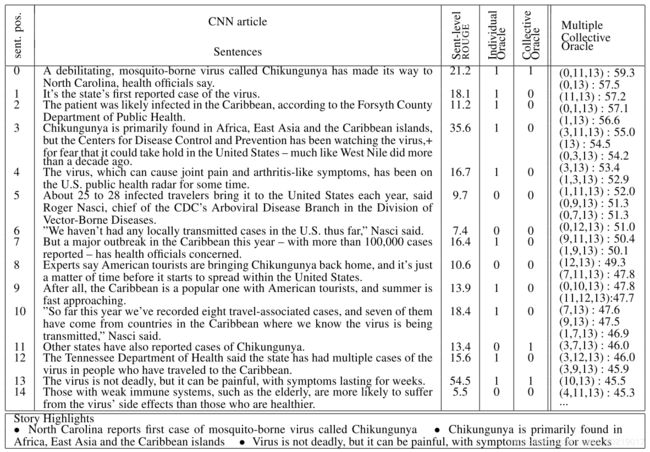
上表中的最后一列显示了句子的排名(根据ROUGE-1,ROUGE-2,ROUGE-L F1的平均值)。有意思的是,可以发现,排名高的句子拥有合理的高ROUGE分数
这些不符合的地方让模型针对抽取式摘要进行句子排序的时候不是那么有效,作者采用的训练策略不是最大化ground truth的似然,而是训练模型对文档中的每个句子去预测单一的ROUGE分数,然后再选择分数最高的m个句子组成摘要。不过高ROUGE分数的句子不一定导致高分数的摘要,例如某些句子会包括重叠的内容并形成冗长和冗余的摘要。举例,上面的句子3,拥有比较高的ROUGE 分数:35.6%,但是前5个高分摘要中都没有它。接下来作者介绍如何使用强化学习解决这个问题。
4 使用强化学习进行句子排序
强化学习被提出作为一个训练系列-序列生成模型的方法,为了直接优化使用在测试阶段的度量(如BLEU或ROUGE)。作者提出了一个组合了最大似然交叉熵与policy gradient强化学习中的奖励的目标函数来全局优化ROUGE。
这个训练算法允许探索可能的摘要空间,使得模型对于没见过的数据更加robust
总而言之,强化学习帮助抽取式摘要主要体现在两个方面:
a) 直接优化验证时的度量目标而不是最大化ground-truth标签的似然
b) 更好地对句子进行判别,一个句子如果经常出现在高分的摘要中,它的排名才会高
4.1 策略学习(Policy Learning)
将上图的抽取式神经网络模型转换为一个强化学习范例。因此,该模型可以被视为一个和文档组成的环境(environment)交互的代理(agent)。首先,代理被随机初始化,读入文档 D D D再对每个句子 s i ∈ D s_i \in D si∈D使用策略(policy)—— p ( y i ∣ s i , D , θ ) p(y_i|s_i,D,\theta) p(yi∣si,D,θ)来预测相关分数(relevance score)。
一旦代理读完一篇文档,一个带有标签 y ^ \hat{y} y^ 的摘要就会从排名的句子中抽取出来,然后给代理一个"奖励"——这个抽取摘要与标注摘要有多像。作者使用ROUGE-1,ROUGE-2, ROUGE-L的平均值的F1 score作为"奖励": r r r。Unigram和bigram重叠(ROUGE-1和ROUGE-2)用于评估信息量,而最长的共同子序列(ROUGE-L)用于评估语句流畅度。
公式化:
(2) L ( θ ) = − E y ^ ∼ p θ [ r ( y ^ ) ] L(\theta) = - \Bbb E_{\hat{y} \sim p_\theta}[r(\hat{y})] \tag{2} L(θ)=−Ey^∼pθ[r(y^)](2)
以上 p θ p_\theta pθ代表 p ( y ∣ D , θ ) p(y|D,\theta) p(y∣D,θ), 作者最小化这个公式即达到训练目标。
强化学习算法是基于这个观察(observation): 不可微分的奖励函数(这里指ROUGE)的期望梯度可以被以下公式计算出来:
(3) ∇ L ( θ ) = − E y ^ ∼ p θ [ r ( y ^ ) ∇ log p ( y ^ ∣ D , θ ) ] \nabla L(\theta) = - \Bbb E_{\hat{y} \sim p_\theta}[r(\hat y) \nabla\log p(\hat y | D, \theta)] \tag{3} ∇L(θ)=−Ey^∼pθ[r(y^)∇logp(y^∣D,θ)](3)
公式(1)旨在最大化训练数据的似然 ,然而公式(2)的目标在于通过在高分摘要中出现的频率来学习区分句子(是否应该在摘要中出现)
4.2 使用高概率样本进行训练
计算公式(3)中的期望项很困难,因为可能的抽取方式太多了。在实践中,作者采用来自 p θ p_\theta pθ中的单一样本 y ^ \hat y y^来作为一个训练batch中的期望梯度的近似,即:
(4) ∇ L ( θ ) ≈ − r ( y ^ ) ∇ log p ( y ^ ∣ D , θ ) ≈ − r ( y ^ ) ∑ i = 1 n ∇ log p ( y ^ i ∣ s i , D , θ ) \begin{aligned} \nabla L(\theta) & \approx -r(\hat y) \nabla \log p(\hat y | D, \theta) \\ & \approx -r(\hat y)\sum_{i=1}^n \nabla \log p(\hat y_i | s_i, D, \theta) \end{aligned} \tag{4} ∇L(θ)≈−r(y^)∇logp(y^∣D,θ)≈−r(y^)i=1∑n∇logp(y^i∣si,D,θ)(4)
强化学习算法可以通过随机策略(random policy)开始学习, 它的优点是能够挑战复杂任务, 比如这个从非常大量的候选句子摘要中进行选择的任务。
作者将等式(4)中 y ^ \hat y y^的搜索空间限制为最大概率样本集合: Y ^ \hat \Bbb Y Y^, 并使用获得最高分的 k k k 次抽取结果来作为 Y ^ \hat \Bbb Y Y^的近似。更具体地说,他们通过首先从文档中选择 p p p 个句子来有效地组合候选摘要,而这些句子本身具有比较高的ROUGE分数。然后在满足最大长度 m m m 的情况下生成 p p p 个句子的所有组合,并且用人工摘要进行验证。所有的这些摘要将按照ROUGE-1,ROUGE-2和ROUGE-L的平均值的F1 score进行排序。 Y ^ \hat \Bbb Y Y^包括了top k k k个候选摘要, 在训练过程中,将从 Y ^ \hat \Bbb Y Y^而非 p ( y ^ ∣ D , θ ) p(\hat y | D, \theta) p(y^∣D,θ)中进行采样。
Ranzato et al. (2015)提出了另一种强化学习方案:MIXER(混合增量交叉熵增强),首次使用ground truth标签进行带交叉熵损失模型的预训练,然后遵循课程学习(curriculum learning) 策略(Bengio et al., 2015)逐步教导模型自己生成稳定的预测。作者的实验结果显示MIXER比Nallapati et al. (2017)仅在集体标签上训练的模型表现更差。作者猜想这是由于他们的排名问题的无穷性(unbounded nature)。回顾一下,作者的模型将相关性分数分配给句子而不是分配给单词。与其它使用固定词汇表的预测任务(Li et al., 2016; Paulus et al., 2017; Zhang and Lapata, 2017)相比,句子表示的空间是巨大的并且相当不受约束。此外,作者对梯度的近似将会使模型更快地收敛到最优策略。另一个有利的地方是此方法不需要在线奖励预估器(online reward estimator), 通过预计算 Y ^ \hat \Bbb Y Y^,对比MIXER及相关训练的模式来说有着显著的加速效果。
5 实验
作者介绍了用于评估模型性能的实验装置,作者将其称为REFRESH,作为基于加强学习的抽取式摘要的简写。作者描述了他们的数据集,讨论了实现细节,他们的验证协议(evaluation protocol)以及用于比较的系统。
5.1 摘要数据集
CNN/Daily Mail数据集, 使用Hermann et al. (2015)中的标准数据集切分
5.2 实现细节
对于CNN数据集,抽取3个句子( m = 3 m=3 m=3)
对于Daily Mail数据集,抽取4个句子( m = 4 m=4 m=4)
这是因为CNN/Daily Mail验证集中的gold highlights句子长度比为2.6 / 4.2
对这两个数据集作者使用具有最高分的10个文档句子序列( p = 10 p=10 p=10)来估计高分抽取
通过调整,作者发现当在CNN数据集上 k = 5 k=5 k=5时,在Daily Mail上 k = 15 k=15 k=15时模型表现最好
使用One Billion Word Benchmark 语料 (Chelba et al., 2013),skip-gram模型(Mikolov et al., 2013) (上下文窗口大小为6, 负采样大小10, 分层softmax 1)来训练词嵌入, 对已知词的嵌入维度200,对未知词的初始嵌入维度为0,不过在训练时,句子将增加0到长度100
其余的略。。。真心不想肝了,反正不太重要,作者原文也写得挺详细的。
6 结果
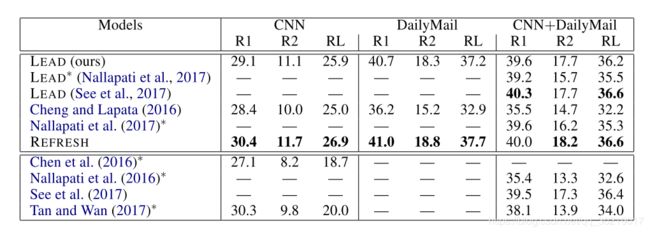

一顿操作,证明自己达到state-of-the-art
7 相关工作
介绍了很多以前的工作,并说作者没听说过以前有用强化学习训练句子排名来做抽取式摘要的尝试工作。
8 结论
在这项工作中,作者开发了一个抽取式摘要模型,该模型通过优化ROUGE评估指标进行全局训练。 训练算法探索候选摘要的空间,同时学习优化与手头任务相关的奖励功能。 实验结果表明,强化学习提供了一种很好的方法来引导他们的模型,以生成信息丰富,流畅,简洁的摘要,优于CNN和DailyMail数据集上最先进的抽取式和生成式系统。 在未来,作者希望关注较小的话语单元(discourse unit)(Mann和Thompson,1988),而不是单独的句子,建模压缩和联合抽取