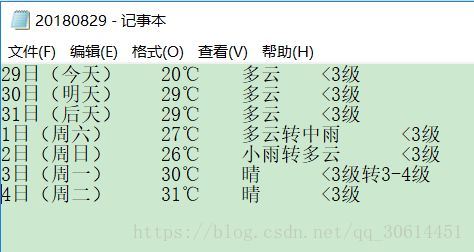
5.4 Scrapy爬虫实战之天气信息
1.切换到工程文件夹,利用scrapy startproject weather命令新加你一个scrapy工程;
D:\>cd D:\Python\ScrapyProject
D:\Python\ScrapyProject>scrapy startproject weather
New Scrapy project 'weather', using template directory 'd:\\python\\lib\\site-packages\\scrapy\\templates\\project', created in:
D:\Python\ScrapyProject\weather
You can start your first spider with:
cd weather
scrapy genspider example example.com2.将目录切换到weather目录下,使用命令scrapy genspider beiJingSpider 新建一个爬虫文件这里爬取北京一周天气,网址如下:
D:\Python\ScrapyProject>cd weather
D:\Python\ScrapyProject\weather>scrapy genspider beiJingSpider http://www.weather.com.cn/weather/101010100.shtml
Created spider 'beiJingSpider' using template 'basic' in module:
weather.spiders.beiJingSpider3.修改item.py
修改后的文件内容如下:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class WeatherItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
cityDate = scrapy.Field()
week = scrapy.Field()
img = scrapy.Field()
temperature = scrapy.Field()
weather = scrapy.Field()
wind = scrapy.Field()
item.py文件的作用就是确定需要爬取的内容有哪些,所以在这里就是把希望获取的项的名称按照示例格式填写出来。
4.修改Spider文件beiJingSpider.py
# -*- coding: utf-8 -*-
import scrapy
from weather.items import WeatherItem
class BeijingspiderSpider(scrapy.Spider):
name = 'beiJingSpider'
allowed_domains = ['weather.com.cn']
start_urls = ['http://www.weather.com.cn/weather/101010100.shtml']
def parse(self, response):
for sub in response.xpath('//*[@id="7d"]/ul/li'):
item = WeatherItem()
item['cityDate'] = sub.xpath('h1/text()').extract()
print(type(item['cityDate'][0]))
item['temperature'] = sub.xpath('p[@class="tem"]/span/text()').extract() + sub.xpath('p[@class="tem"]/i/text()').extract()
item['wind'] = sub.xpath('p[@class="win"]/i/text()').extract()
item['weather'] = sub.xpath('p[@class="wea"]/text()').extract()
yield item
5.修改pipelines.py文件
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import time
import os.path
import urllib2
class WeatherPipeline(object):
def process_item(self, item, spider):
today = time.strftime('%Y%m%d',time.localtime())
fileName = today + '.txt'
with open(fileName,'a') as fp:
fp.write(item['cityDate'][0].encode('utf8')+'\t')
fp.write(item['temperature'][0].encode('utf8')+'\t')
fp.write(item['weather'][0].encode('utf8')+'\t')
fp.write(item['wind'][0].encode('utf8')+'\t')
time.sleep(1)
return item
6.修改setting.py文件
# -*- coding: utf-8 -*-
# Scrapy settings for weather project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'weather'
SPIDER_MODULES = ['weather.spiders']
NEWSPIDER_MODULE = 'weather.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'weather (+http://www.yourdomain.com)'
# Obey robots.txt rules
#ROBOTSTXT_OBEY = True
ITEM_PIPELINES = {'weather.pipelines.WeatherPipeline':1}
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'weather.middlewares.WeatherSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'weather.middlewares.WeatherDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# 'weather.pipelines.WeatherPipeline': 300,
#}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
7.最后在命令框运行爬虫指令可以得到爬取文件
D:\>cd D:\\Python\ScrapyProject\weather