Web自动化测试(全网最给力自动化教程)
http://www.cnblogs.com/zidonghua/p/7430083.html
python+selenium自动化软件测试(第2章):WebDriver API
欢迎您来阅读和练手!您将会从本章的详细讲解中,获取很大的收获!开始学习吧!
正文
2.1 操作元素基本方法
前言
前面已经把环境搭建好了,从这篇开始,正式学习selenium的webdriver框架。我们平常说的 selenium自动化,其实它并不是类似于QTP之类的有GUI界面的可视化工具,我们要学的是webdriver框架的API。
本篇主要讲如何用Python调用webdriver框架的API,对浏览器做一些常规的操作,如打开、前进、后退、刷新、设置窗口大小、截屏、退出等操作。
2.1.1 打开网页
1.从selenium里面导入webdriver模块
2.打开Firefox浏览器(Ie和Chrome对应下面的)
3.打开百度网址

2.1.2 设置休眠
1.由于打开百度网址后,页面加载需要几秒钟,所以最好等到页面加载完成后再继续下一步操作
2.导入time模块,time模块是Python自带的,所以无需下载
3.设置等待时间,单位是秒(s),时间值可以是小数也可以是整数

2.1.3 页面刷新
1.有时候页面操作后,数据可能没及时同步,需要重新刷新
2.这里可以模拟刷新页面操作,相当于浏览器输入框后面的刷新按钮

2.1.4 页面切换
1.当在一个浏览器打开两个页面后,想返回上一页面,相当于浏览器左上角的左箭头按钮。
2.返回到上一页面后,也可以切换到下一页,相当于浏览器左上角的右箭头按钮。

2.1.5 设置窗口大小
1.可以设置浏览器窗口大小,如设置窗口大小为手机分辨率540*960
2.也可以最大化窗口

2.1.6 截屏
1. 打开网站之后,也可以对屏幕截屏
2.截屏后设置指定的保存路径+文件名称+后缀

2.1.7 退出
1.退出有两种方式,一种是close;另外一种是quit。
2.close用于关闭当前窗口,当打开的窗口较多时,就可以用close关闭部分窗口。
3.quit用于结束进程,关闭所有的窗口。
4.最后结束测试,要用quit。quit可以回收c盘的临时文件。

掌握了浏览器的基本操作后,接下来就可以开始学习元素定位了,元素定位需要有一定的html基础。没有基础的可以按下浏览器的F12快捷键先看下html的布局,先了解一些就可以了。
2.1.8 加载浏览器配置
启动浏览器后,发现右上角安装的插件不见了,这是因为webdriver启动浏览器时候,是开的一个虚拟线程,跟手工点开是有区别的,selenium的一切操作都是模拟人工(不完全等于人工操作)。
加载Firefox配置
有小伙伴在用脚本启动浏览器时候发现原来下载的插件不见了,无法用firebug在打开的页面上继续定位页面元素,调试起来不方便 。加载浏览器配置,需要用FirefoxProfile(profile_directory)这个类来加载,profile_directory既为浏览器配置文件的路径地址。
一、遇到问题
1.在使用脚本打开浏览器时候,发现右上角原来下载的插件firebug不见了,到底去哪了呢?
2.用脚本去打开浏览器时候,其实是重新打开了一个进程,跟手动打开浏览器不是一个进程。
所以没主动加载插件,不过selenium里面其实提供了对应的方法去打开,只是很少有人用到。

二、FirefoxProfile
1.要想了解selenium里面API的用法,最好先看下相关的帮助文档打开cmd窗口,
输入如下信息:
->python
->from selenium import webdriver
->help(webdriver.FirefoxProfile)

Help on class FirefoxProfile in module
selenium.webdriver.firefox.firefox_profile:
class FirefoxProfile(builtin.object)
| Methods defined here:
|
| init(self, profile_directory=None)
| Initialises a new instance of a Firefox Profile
|
| :args:
| - profile_directory: Directory of profile that you want to use.
| This defaults to None and will create a new
| directory when object is created.
2.翻译过来大概意思是说,这里需要profile_directory这个配置文件路径的参数
3.profile_directory=None,如果没有路径,默认为None,启动的是一个新的,有的话就加载指定的路径。
三、profile_directory
1.问题来了:Firefox的配置文件地址如何找到呢?
2.打开Firefox点右上角设置>?(帮助)>故障排除信息>显示文件夹

3.打开后把路径复制下来就可以了:
C:\Users\xxx\AppData\Roaming\Mozilla\Firefox\Profiles\1x41j9of.default

四、启动配置文件
1.由于文件路径存在字符:\ ,反斜杠在代码里是转义字符,这个有点代码基础的应该都知道。
不懂什么叫转义字符的,自己翻书补下基础吧!
2.遇到转义字符,为了不让转义,有两种处理方式:
第一种:\ (前面再加一个反斜杠)
第二种:r”\"(字符串前面加r,使用字符串原型)

五、参考代码:
# coding=utf-8 from selenium import webdriver # 配置文件地址 profile_directory = r'C:\Users\xxx\AppData\Roaming\Mozilla\Firefox\Profiles\1x41j9of.default' # 加载配置配置 profile = webdriver.FirefoxProfile(profile_directory) # 启动浏览器配置 driver = webdriver.Firefox(profile)
其实很简单,在调用浏览器的前面,多加2行代码而已,主要是要弄清楚原理。
2.2 常用8种元素定位(Firebug和firepath)
前言
元素定位在firefox上可以安装Firebug和firepath辅助工具进行元素定位。
2.2.1 环境准备
1.浏览器选择:Firefox
2.安装插件:Firebug和FirePath(设置》附加组件》搜索:输入插件名称》下载安装后重启浏览器)
3.安装完成后,页面右上角有个小爬虫图标
4.快速查看xpath插件:XPath Checker这个可下载,也可以不用下载
5.插件安装完成后,点开附加组件》扩展,如下图所示

2.2.2 查看页面元素
以百度搜索框为例,先打开百度网页
1.点右上角爬虫按钮
2.点左下角箭头
3.将箭头移动到百度搜索输入框上,输入框高亮状态
4.下方红色区域就是单位到输入框的属性:
<input id="kw" class="s_ipt" type="text" autocomplete="off" maxlength="100" name="wd">

2.2.3 find_element_by_id()
1.从上面定位到的元素属性中,可以看到有个id属性:id="kw",这里可以通过它的id属性定位到这个元素。
2.定位到搜索框后,用send_keys()方法,输入文本。

2.2.4 find_element_by_name()
1.从上面定位到的元素属性中,可以看到有个name属性:name="wd",这里可以通过它的name属性单位到这个元素。
说明:这里运行后会报错,说明这个搜索框的name属性不是唯一的,无法通过name属性直接定位到输入框

2.2.5 find_element_by_class_name()
1.从上面定位到的元素属性中,可以看到有个class属性:class="s_ipt",这里可以通过它的class属性定位到这个元素。

2.2.6 find_element_by_tag_name()
1.从上面定位到的元素属性中,可以看到每个元素都有tag(标签)属性,如搜索框的标签属性,就是最前面的input。
2.很明显,在一个页面中,相同的标签有很多,所以一般不用标签来定位。以下例子,仅供参考和理解,运行肯定报错。

2.2.7 find_element_by_link_text()
1.定位百度页面上"hao123"这个按钮

查看页面元素:
<a class="mnav" target="_blank" href="http://www.hao123.com">hao123a>
2.从元素属性可以分析出,有个href = "http://www.hao123.com
说明它是个超链接,对于这种元素,可以用以下方法:

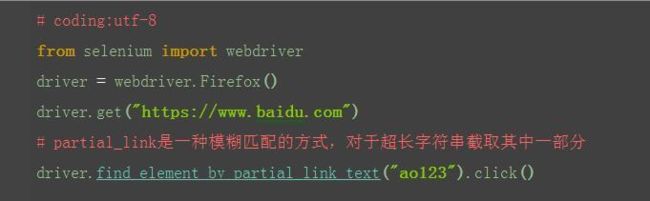
2.2.8 find_element_by_partial_link_text()
1.有时候一个超链接它的字符串可能比较长,如果输入全称的话,会显示很长,这时候可以用一模糊匹配方式,截取其中一部分字符串就可以了
2.如“hao123”,只需输入“ao123”也可以定位到
2.2.9 find_element_by_xpath()
1.以上定位方式都是通过元素的某个属性来定位的,如果一个元素它既没有id、name、class属性也不是超链接,这么办呢?或者说它的属性很多重复的。这个时候就可以用xpath解决。
2.xpath是一种路径语言,跟上面的定位原理不太一样,首先第一步要先学会用工具查看一个元素的xpath。

3.按照上图的步骤,在FirePath插件里copy对应的xpath地址。

2.2.10 find_element_by_css_selector()
1.css是另外一种语法,比xpath更为简洁,但是不太好理解。这里先学会如何用工具查看,后续的教程再深入讲解
2.打开FirePath插件选择css
3.定位到后如下图红色区域显示

总结:
selenium的webdriver提供了18种(注意是18种,不是8种)的元素定位方法,前面8种是通过元素的属性来直接定位的,后面的xpath和css定位更加灵活,需要重点掌握其中一个。
前八种是大家都熟悉的,经常会用到的:
1.id定位:find_element_by_id(self, id_) 2.name定位:find_element_by_name(self, name) 3.class定位:find_element_by_class_name(self, name) 4.tag定位:find_element_by_tag_name(self, name) 5.link定位:find_element_by_link_text(self, link_text) 6.partial_link定位find_element_by_partial_link_text(self, link_text) 7.xpath定位:find_element_by_xpath(self, xpath) 8.css定位:find_element_by_css_selector(self, css_selector)
这八种是复数形式(2.8和2.27章节有介绍)
9.id复数定位find_elements_by_id(self, id_) 10.name复数定位find_elements_by_name(self, name) 11.class复数定位find_elements_by_class_name(self, name) 12.tag复数定位find_elements_by_tag_name(self, name) 13.link复数定位find_elements_by_link_text(self, text) 14.partial_link复数定位find_elements_by_partial_link_text(self, link_text) 15.xpath复数定位find_elements_by_xpath(self, xpath) 16.css复数定位find_elements_by_css_selector(self, css_selector
这两种是参数化的方法,会在以后搭建框架的时候,会经常用到PO模式,才会用到这个参数化的方法(将会在4.2有具体介绍)
17.find_element(self, by='id', value=None) 18.find_elements(self, by='id', value=None)
2.3 xpath定位
前言
在上一篇简单的介绍了用工具查看目标元素的xpath地址,工具查看比较死板,不够灵活,有时候直接复制粘贴会定位不到。这个时候就需要自己手动的去写xpath了,这一篇详细讲解xpath的一些语法。
什么是xpath呢?
官方介绍:XPath即为XML路径语言,它是一种用来确定XML文档中某部分位置的语言。反正小编看这个介绍是云里雾里的,通俗一点讲就是通过元素的路径来查找到这个元素的。
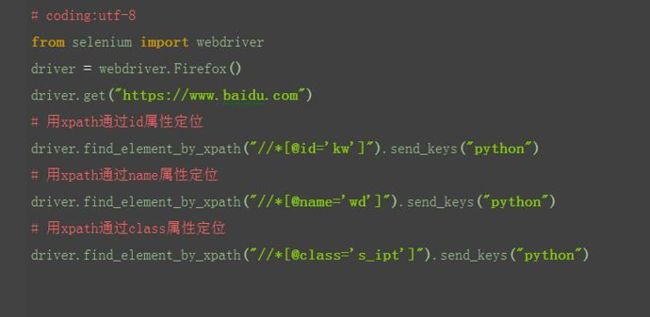
2.3.1 xpath:属性定位
1.xptah也可以通过元素的id、name、class这些属性定位,如下图:

2.于是可以用以下xpath方法定位
2.3.2 xpath:其它属性
1.如果一个元素id、name、class属性都没有,这时候也可以通过其它属性定位到
2.3.3 xpath:标签
1.有时候同一个属性,同名的比较多,这时候可以通过标签筛选下,定位更准一点
2.如果不想制定标签名称,可以用*号表示任意标签
3.如果想制定具体某个标签,就可以直接写标签名称

2.3.4 xpath:层级
1.如果一个元素,它的属性不是很明显,无法直接定位到,这时候我们可以先找它老爸(父元素)。
2.找到它老爸后,再找下个层级就能定位到了。

3.如上图所示,要定位的是input这个标签,它的老爸的id=s_kw_wrap。
4.要是它老爸的属性也不是很明显,就找它爷爷id=form。
5.于是就可以通过层级关系定位到。

2.3.5 xpath:索引
1.如果一个元素它的兄弟元素跟它的标签一样,这时候无法通过层级定位到。因为都是一个父亲生的,多胞胎兄弟。
2.虽然双胞胎兄弟很难识别,但是出生是有先后的,于是可以通过它在家里的排行老几定位到。
3.如下图三胞胎兄弟。

4.用xpath定位老大、老二和老三(这里索引是从1开始算起的,跟Python的索引不一样)。

2.3.6 xpath:逻辑运算
1.xpath还有一个比较强的功能,是可以多个属性逻辑运算的,可以支持与(and)、或(or)、非(not)
2.一般用的比较多的是and运算,同时满足两个属性

2.3.7 xpath:模糊匹配
1.xpath还有一个非常强大的功能,模糊匹配。
2.掌握了模糊匹配功能,基本上没有定位不到的。
3.比如我要定位百度页面的超链接“hao123”,在上一篇中讲过可以通过by_link,也可以通过by_partial_link,模糊匹配定位到。当然xpath也可以有同样的功能,并且更为强大。

可以把xpath看成是元素定位界的屠龙刀。武林至尊,宝刀xpath,css不出,谁与争锋?下节课将亮出倚天剑css定位。
2.4 CSS定位
前言
大部分人在使用selenium定位元素时,用的是xpath定位,因为xpath基本能解决定位的需求。css定位往往被忽略掉了,其实css定位也有它的价值,css定位更快,语法更简洁。
这一篇css的定位方法,主要是对比上一篇的xpath来的,基本上xpath能完成的,css也可以做到。两篇对比学习,更容易理解。
2.4.1 css:属性定位
1.css可以通过元素的id、class、标签这三个常规属性直接定位到
2.如下是百度输入框的的html代码:
<input id="kw" class="s_ipt" type="text" autocomplete="off" maxlength="100" name="wd"/>
3.css用#号表示id属性,如:#kw
4.css用.表示class属性,如:.s_ipt
5.css直接用标签名称,无任何标示符,如:input

2.4.2 css:其它属性
1.css除了可以通过标签、class、id这三个常规属性定位外,也可以通过其它属性定位
2.以下是定位其它属性的格式

2.4.3 css:标签
1.css页可以通过标签与属性的组合来定位元素

2.4.4 css:层级关系
1.在前面一篇xpath中讲到层级关系定位,这里css也可以达到同样的效果
2.如xpath:
//form[@id='form']/span/input和
//form[@class='fm']/span/input也可以用css实现

2.4.5 css:索引
1.以下图为例,跟上一篇一样:

2.css也可以通过索引option:nth-child(1)来定位子元素,这点与xpath写法用很大差异,其实很好理解,直接翻译过来就是第几个小孩。

2.4.6 css:逻辑运算
1.css同样也可以实现逻辑运算,同时匹配两个属性,这里跟xpath不一样,无需写and关键字

2.4.7 css:模糊匹配
1.css的模糊匹配contains('xxx'),网上虽然用各种资料显示能用,但是小编亲自试验了下,一直报错。
2.在各种百度后找到了答案:you can't do this withCSS selectors, because there is no such thing as:contains() in CSS. It was a proposal that was abandoned years ago.
非常遗憾,这个语法已经被抛弃了,所以这里就不用管这个语法了。
css语法远远不止上面提到的,还有更多更强大定位策略,有兴趣的可以继续深入研究。官方说法,css定位更快,语法更简洁,但是xpath更直观,更好理解一些。
2.5 SeleniumBuilder辅助定位元素
前言
对于用火狐浏览器的小伙伴们,你还在为定位元素而烦恼嘛?
上古神器Selenium Builder来啦,哪里不会点哪里,妈妈再也不用担心我的定位元素问题啦!(但是也不是万能,基本上都能覆盖到)
2.5.1 安装Selenium Builder
在火狐浏览器的附加组件中搜索添加Selenium Builder即可。安装好后如下图所示:

2.5.2 直接运用
1.打开你要测试的URL或者打开插件后输入你要测试的URL,如下图

2.点击后弹出一个弹窗,如下图:
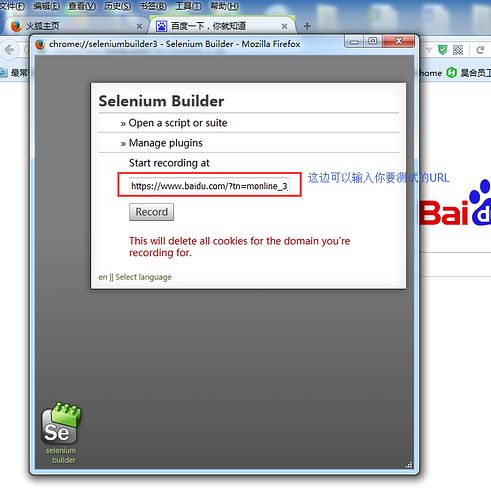
注:如果你是直接在你要测的网页页面打开这个插件时,selenium builder会直接获取你要测的URL
3.点击record:

然后你就可以哪里不会点哪里了。这里举个例子:
2.5.3 实践案例
1.百度首页,点击百度一下,然后点击登录,再一次点击账号和密码输入框,让我们来看看结果。

2.这里没有展开,点击展开后可以发现定位该元素的多种方法

直接选择你想要的方法复制粘贴即可,不用的话直接关掉弹窗即可。
2.6 操作元素(键盘和鼠标事件)
前言
在前面的几篇中重点介绍了一些元素的定位方法,定位到元素后,接下来就是需要操作元素了。本篇总结了web页面常用的一些操作元素方法,可以统称为行为事件
有些web界面的选项菜单需要鼠标悬停在某个元素上才能显示出来(如百度页面的设置按钮)。
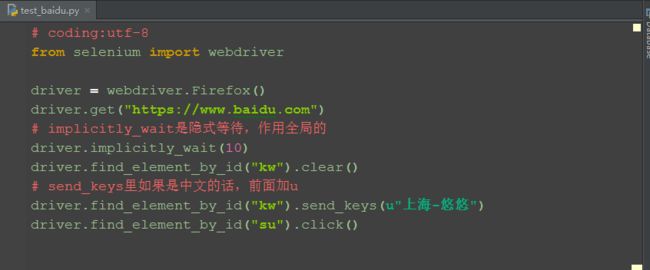
2.6.1 简单操作
1.点击(鼠标左键)页面按钮:click()
2.清空输入框:clear()
3.输入字符串:send_keys()
4.send_keys()如果是发送中文的,前面需加u,如:u"中文",因为这里是输入到windows系统了,windows系统是GBK编码,我们的脚本是utf-8,需要转码为Unicode国际编码,这样才能识别到。
2.6.2 submit提交表单
1.在前面百度搜索案例中,输入关键字后,可以直接按回车键搜索,也可以点搜索按钮搜索。
2.submit()一般用于模拟回车键。

2.6.3 键盘操作
1.selenium提供了一整套的模拟键盘操作事件,前面submit()方法如果不行的话,可以试试模拟键盘事件
2.模拟键盘的操作需要先导入键盘模块:from selenium.webdriver.common.keysimport Keys
3.模拟enter键,可以用send_keys(Keys.ENTER)

4.其它常见的键盘操作:
键盘F1到F12:send_keys(Keys.F1)把F1改成对应的快捷键:
复制Ctrl+C:send_keys(Keys.CONTROL,'c')
粘贴Ctrl+V:send_keys(Keys.CONTROL,'v')
全选Ctrl+A:send_keys(Keys.CONTROL,'a')
剪切Ctrl+X:send_keys(Keys.CONTROL,'x')
制表键Tab: send_keys(Keys.TAB)
这里只是列了一些常用的,当然除了键盘事件,也有鼠标事件。
2.6.4 鼠标悬停事件
1.鼠标不仅仅可以点击(click),鼠标还有其它的操作,如:鼠标悬停在某个元素上,鼠标右击,鼠标按住某个按钮拖到
2.鼠标事件需要先导入模块:from selenium.webdriver.common.action_chainsimport ActionChains
perform() 执行所有ActionChains中的行为;
move_to_element() 鼠标悬停。
3.这里以百度页面设置按钮为例:

4.除了常用的鼠标悬停事件外,还有
右击鼠标:context_click()
双击鼠标:double_click()
依葫芦画瓢,替换上面案例中对应的鼠标事件就可以了
selenium提供了一整套完整的鼠标和键盘行为事件,功能还是蛮强大滴。下一篇介绍多窗口的情况下如何处理。
2.7 多窗口、句柄(handle)
前言
有些页面的链接打开后,会重新打开一个窗口,对于这种情况,想在新页面上操作,就得先切换窗口了。获取窗口的唯一标识用句柄表示,所以只需要切换句柄,我们就能在多个页面上灵活自如的操作了。
一、认识多窗口
1.打开赶集网:http://bj.ganji.com/,点击招聘求职按钮会发现右边多了一个窗口标签

2.我们用代码去执行点击的时候,发现界面上出现两个窗口,如下图这种情况就是多窗口了。

3.到这里估计有小伙伴纳闷了,手工点击是2个标签,怎么脚本点击就变成2个窗口了,这个在2.1里面讲过,脚本执行是不加载配置的,手工点击是浏览器默认设置了新窗口打开方式为标签,这里用鼠标按住点二个标签,拖拽出来,也就变成2个标签了,是一回事。

二、获取当前窗口句柄
1.元素有属性,浏览器的窗口其实也有属性的,只是你看不到,浏览器窗口的属性用句柄(handle)来识别。
2.人为操作的话,可以通过眼睛看,识别不同的窗口点击切换。但是脚本没长眼睛,它不知道你要操作哪个窗口,这时候只能句柄来判断了。
3.获取当前页面的句柄:driver.current_window_handle

三、获取所有句柄
1.定位赶集网招聘求职按钮,并点击
2.点击后,获取当前所有的句柄:window_handles

四、切换句柄
网上大部分教程都是些的第一种方法,小编这里新增一个更简单的方法,直接从获取所有的句柄list里面取值。
方法一(不推荐):
1.循环判断是否与首页句柄相等
2.如果不等,说明是新页面的句柄
3.获取的新页面句柄后,可以切换到新打开的页面上
4.打印新页面的title,看是否切换成功
方法二:
1.直接获取all_h这个list数据里面第二个hand的值:all_h[1]

五、关闭新窗口,切回主页
1.close是关闭当前窗口,因为此时有两个窗口,用close可以关闭其中一个,quit是退出整个进程(如果当前有两个窗口,会一起关闭)。
2.切换到首页句柄:h
3.打印当前页面的title,看是否切换到首页了

六、参考代码
# coding:utf-8 from selenium import webdriver driver = webdriver.Firefox() driver.get("http://bj.ganji.com/") h = driver.current_window_handle print h # 打印首页句柄 driver.find_element_by_link_text("招聘求职").click() all_h = driver.window_handles print all_h # 打印所有的句柄 # 方法一:判断句柄,不等于首页就切换(不推荐此方法,太繁琐) # for i in all_h: # if i != h: # driver.switch_to.window(i) # print driver.title # 方法二:获取list里面第二个直接切换 driver.switch_to.window(all_h[1]) print driver.title # 关闭新窗口 driver.close() # 切换到首页句柄 driver.switch_to.window(h) # 打印当前的title print driver.title
2.8 定位一组元素elements
前言
前面的几篇都是讲如何定位一个元素,有时候一个页面上有多个对象需要操作,如果一个个去定位的话,比较繁琐,这时候就可以定位一组对象。
webdriver 提供了定位一组元素的方法,跟前面八种定位方式其实一样,只是前面是单数,这里是复数形式:find_elements
本篇拿百度搜索作为案例,从搜索结果中随机选择一条搜索结果,然后点击查看。
一、定位搜索结果
1.在百度搜索框输入关键字“测试部落”后,用firebug查看页面元素,可以看到这些搜索结果有共同的属性。

2.从搜索的结果可以看到,他们的父元素一样:
3.标签都一样,且target属性也一样:
4.于是这里可以用css定位(当然用xpath也是可以的)

二、确认定位结果
1.前面的定位策略只是一种猜想,并不一定真正获取到自己想要的对象的,也行会定位到一些不想要的对象。
2.于是可以获取对象的属性,来验证下是不是定位准确了。这里可以获取href属性,打印出url地址。
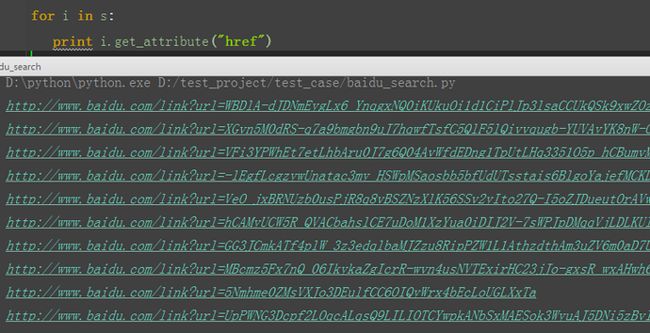
三、随机函数
1.搜索结果有10条,从这10条中随机取一个就ok了
2.先导入随机函数:import random
3.设置随机值范围为0~9:a=random.randint(0~9)

四、随机打开url
1.从返回结果中随机取一个url地址
2.通过get方法打卡url
3.其实这种方式是接口测试了,不属于UI自动化,这里只是开阔下思维,不建议用这种方法

五、通过click点击打开
1.前面那种方法,是直接访问url地址,算是接口测试的范畴了,真正模拟用户点击行为,得用click的方法
# coding:utf-8 from selenium import webdriver import random driver = webdriver.Firefox() driver.get("https://www.baidu.com") driver.implicitly_wait(10) driver.find_element_by_id("kw").send_keys(u"测试部落") driver.find_element_by_id("kw").submit() s = driver.find_elements_by_css_selector("h3.t>a") # 设置随机值 t = random.randint(0, 9) # 随机取一个结果点击鼠标 s[t].click()
不知道有小伙伴有没注意一个细节,前面在搜索框输入关键字后,我并没有去点击搜索按钮,而是用的submit的方法,submit相当于回车键。
具体的操作对象方法,下篇详细介绍。本篇主要学会定位一组对象,然后随机操作其中的一个。
2.9 iframe
一、frame和iframe区别
Frame与Iframe两者可以实现的功能基本相同,不过Iframe比Frame具有更多的灵活性。 frame是整个页面的框架,iframe是内嵌的网页元素,也可以说是内嵌的框架
Iframe标记又叫浮动帧标记,可以用它将一个HTML文档嵌入在一个HTML中显示。它和Frame标记的最大区别是在网页中嵌入 的所包含的内容与整个页面是一个整体,而< /Frame>所包含的内容是一个独立的个体,是可以独立显示的。另外,应用Iframe还可以在同一个页面中多次显示同一内容,而不必重复这段内 容的代码。
二、案例操作:163登录界面
1.打开http://mail.163.com/登录页面
2.用firebug定位登录框
3.鼠标停留在左下角(定位到iframe位置)时,右上角整个登录框显示灰色,说明iframe区域是整个登录框区域
4.左下角箭头位置显示iframe属性 三、切换iframe 四、如果iframe没有id怎么办? 五、释放iframe 六、如何判断元素是否在iframe上? 七、如何解决switch_to_frame上的横线呢? 2.python的脚本上面划一横线,是说这个语法已经过时了(也可以继续用,只是有部分人有强迫症)。上面文档介绍说官方已经不推荐上面的写法了,用这个写法就好了driver.switch_to.frame() 本篇以百度设置下拉选项框为案例,详细介绍select下拉框相关的操作方法。 一、认识select 2.箭头所指位置,就是select选项框,打开页面元素定位,下方红色框框区域,可以看到select标签属性: 3.选项有三个。 二、二次定位 4.还有另外一种写法也是可以的,把最下面两步合并成为一步: 三、直接定位 3.然后自己写xpath定位或者css,一次性直接定位到option上的内容。(不会自己手写的,回头看前面的元素定位内容) 四、Select模块(index) 1.除了上面介绍的两种简单的方法定位到select选项,selenium还提供了更高级的玩法,导入Select模块。直接根据属性或索引定位。 五、Select模块(value) 1.Select模块里面除了index的方法,还有一个方法,通过选项的value值来定位。每个选项,都有对应的value值,如 2.第二个选项对应的value值就是"20":select_by_value("20") 六、Select模块(text) 七、Select模块其它方法 select_by_index() :通过索引定位 first_selected_option() :返回第一个选项 八、整理代码如下: 前言 一、认识alert\confirm\prompt 2.html源码如下(有兴趣的可以copy出来,复制到txt文本里,后缀改成html就可以了,然后用浏览器打开): 二、alert操作 1.先用switch_to_alert()方法切换到alert弹出框上 三、confirm操作 四、prompt操作 五、select遇到的坑 六、最终代码 这一篇应该比较简单,alert相关的内容比较少,虽然有一些页面也有弹窗,但不是所有的弹窗都叫alert。 alert的弹出框界面比较简洁,调用的是Windows系统弹窗警告框,没花里胡哨的东西,还是很容易区分的。 本篇主要介绍单选框和复选框的操作 2.各位小伙伴看清楚哦,上面的单选框是圆的;下图复选框是方的,这个是业界的标准,要是开发小伙伴把图标弄错了,可以先抽他了。 三、单选:radio 2.定位id,点击图标就可以了,代码如下(获取url地址方法:把上面源码粘贴到文本保存为.html后缀后用浏览器打开,在浏览器url地址栏复制出地址就可以了) 四、复选框:checkbox 2.那么问题来了:如果想全部勾选上呢? 五、全部勾选: 2.这里注意,敲黑板做笔记了:find_elements是不能直接点击的,它是复数的,所以只能先获取到所有的checkbox对象,然后通过for循环去一个个点击操作 七、参考代码: 前言 2.源码如下:(用txt文本保存,后缀改成html) 二、table特征 三、xpath定位table 2.这里定位的格式是固定的,只需改tr和td后面的数字就可以了.如第二行第一列tr[2]td[1]. 五、参考代码: 补充说明:有些小伙伴可能会遇到table在ifame上的情况,这时候就需要先切换iframe了。 一、加载Chrome配置 二、Wap测试 前言 二、打开编辑界面 三、iframe切换 (关于iframe不懂的可以看前面这篇:
1.由于登录按钮是在iframe上,所以第一步需要把定位器切换到iframe上
2.用switch_to_frame方法切换,此处有id属性,可以直接用id定位切换
1.这里iframe的切换是默认支持id和name的方法的,当然实际情况中会遇到没有id属性和name属性为空的情况,这时候就需要先定位iframe元素对象
2.定位元素还是之前的八种方法同样适用,这里我可以通过tag先定位到,也能达到同样效果
1.当iframe上的操作完后,想重新回到主页面上操作元素,这时候,就可以用switch_to_default_content()方法返回到主页面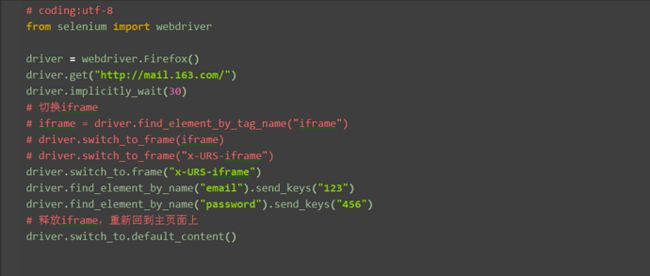
1.定位到元素后,切换到firepath界面
2.看firebug工具左上角,如果显示Top Window说明没有iframe
3.如果显示iframe#xxx这样的,说明在iframe上,#后面就是它的id
1.先找到官放的文档介绍
八、参考代码如下:![]()
# coding:utf-8
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://mail.163.com/")
driver.implicitly_wait(30)
# 切换iframe
# iframe = driver.find_element_by_tag_name("iframe")
# driver.switch_to_frame(iframe)
# driver.switch_to_frame("x-URS-iframe")
driver.switch_to.frame("x-URS-iframe")
driver.find_element_by_name("email").send_keys("123")
driver.find_element_by_name("password").send_keys("456")
# 释放iframe,重新回到主页面上
driver.switch_to.default_content()
![]()
2.10 select下拉框
1.打开百度-设置-搜索设置界面,如下图所示
<select id="nr" name="NR">
<option selected="" value="10">每页显示10条option>
<option value="20">每页显示20条option>
<option value="50">每页显示50条option>
1.定位select里的选项有多种方式,这里先介绍一种简单的方法:二次定位
2.基本思路,先定位select框,再定位select里的选项
3.代码如下:
driver.find_element_by_id("nr").find_element_by_xpath("//option[@value='50']").click()
1.有很多小伙伴说firebug只能定位到select框,不能定位到里面的选项,其实是工具掌握的不太熟练。小编接下来教大家如何定位里面的选项。
2.用firebug定位到select后,下方查看元素属性地方,点select标签前面的+号,就可以展开里面的选项内容了。

2.先要导入select方法:
from selenium.webdriver.support.select import Select
3.然后通过select选项的索引来定位选择对应选项(从0开始计数),如选择第三个选项:select_by_index(2)
<select id="nr" name="NR">
<option selected="" value="10">每页显示10条option>
<option value="20">每页显示20条option>
<option value="50">每页显示50条option>
select>

1.Select模块里面还有一个更加高级的功能,可以直接通过选项的文本内容来定位。
2.定位“每页显示50条”:select_by_visible_text("每页显示50条")
1.select里面方法除了上面介绍的三种,还有更多的功能如下:
select_by_value() :通过value值定位
select_by_visible_text() :通过文本值定位
deselect_all() :取消所有选项
deselect_by_index() :取消对应index选项
deselect_by_value() :取消对应value选项
deselect_by_visible_text() :取消对应文本选项
all_selected_options() :返回所有的选项![]()
# coding:utf-8
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.select import Select
driver = webdriver.Firefox()
url = "https://www.baidu.com"
driver.get(url)
driver.implicitly_wait(20)
# 鼠标移动到“设置”按钮
mouse = driver.find_element_by_link_text("设置")
ActionChains(driver).move_to_element(mouse).perform()
driver.find_element_by_link_text("搜索设置").click()
# 通过text:select_by_visible_text()
s = driver.find_element_by_id("nr")
Select(s).select_by_visible_text("每页显示50条")
# # 分两步:先定位下拉框,再点击选项s = driver.find_element_by_id("nr")s.find_element_by_xpath("//option[@value='50']").click()
# # 另外一种写法
driver.find_element_by_id("nr").find_element_by_xpath("//option[@value='50']").click()
# # 直接通过xpath定位
driver.find_element_by_xpath(".//*[@id='nr']/option[2]").click()
# # 通过索引:select_by_index()
s = driver.find_element_by_id("nr")
Select(s).select_by_index(2)
# # 通过value:select_by_value()
s = driver.find_element_by_id("nr")
Select(s).select_by_value("20")
![]()
2.11 alert\confirm\prompt
不是所有的弹出框都叫alert,在使用alert方法前,先要识别出到底是不是alert。先认清楚alert长什么样子,下次碰到了,就可以用对应方法解决。
alert\confirm\prompt弹出框操作主要方法有:
text:获取文本值
accept() :点击"确认"
dismiss() :点击"取消"或者叉掉对话框
send_keys() :输入文本值 --仅限于prompt,在alert和confirm上没有输入框
1.如下图,从上到下依次为alert\confirm\prompt,先认清楚长什么样子,以后遇到了就知道如何操作了。
![]()
<html>
<head>
<title>Alerttitle>
head>
<body>
<input id = "alert" value = "alert" type = "button" onclick = "alert('您关注了yoyoketang吗?');"/>
<input id = "confirm" value = "confirm" type = "button" onclick = "confirm('确定关注微信公众号:yoyoketang?');"/>
<input
id = "prompt" value = "prompt" type = "button" onclick = "var name =
prompt('请输入微信公众号:','yoyoketang'); document.write(name) "/>
body>
html>
![]()
2.可以用text方法获取弹出的文本 信息
3.accept()点击确认按钮
4.dismiss()相当于点右上角x,取消弹出框
(url的路径,直接复制浏览器打开的路径)
1.先用switch_to_alert()方法切换到alert弹出框上
2.可以用text方法获取弹出的文本 信息
3.accept()点击确认按钮
4.dismiss()相当于点取消按钮或点右上角x,取消弹出框
(url的路径,直接复制浏览器打开的路径)
1.先用switch_to_alert()方法切换到alert弹出框上
2.可以用text方法获取弹出的文本 信息
3.accept()点击确认按钮
4.dismiss()相当于点右上角x,取消弹出框
5.send_keys()这里多个输入框,可以用send_keys()方法输入文本内容
(url的路径,直接复制浏览器打开的路径)
1.在操作百度设置里面,点击“保存设置”按钮时,alert弹出框没有弹出来。(Ie浏览器是可以的)
2.分析原因:经过慢慢调试后发现,在点击"保存设置"按钮时,由于前面的select操作后,失去了焦点
3.解决办法:在select操作后,做个click()点击操作
s = driver.find_element_by_id("nr")
Select(s).select_by_visible_text("每页显示20条")
time.sleep(3)
s.click()
![]()
# coding:utf-8
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.select import Select
import time
driver = webdriver.Firefox()
url = "https://www.baidu.com"
driver.get(url)
driver.implicitly_wait(20)
# 鼠标移动到“设置”按钮
mouse = driver.find_element_by_link_text("设置")
ActionChains(driver).move_to_element(mouse).perform()
driver.find_element_by_link_text("搜索设置").click()
# 通过text:select_by_visible_text()
s = driver.find_element_by_id("nr")
Select(s).select_by_visible_text("每页显示20条")
time.sleep(3)
s.click()
driver.find_element_by_link_text("保存设置").click()
time.sleep(5)
# 获取alert弹框
t = driver.switch_to_alert()
print t.text
t.accept()
![]()
2.12 单选框和复选框(radiobox、checkbox)
一、认识单选框和复选框
1.先认清楚单选框和复选框长什么样
二、radio和checkbox源码
1.上图的html源码如下,把下面这段复制下来,写到文本里,后缀改成.html就可以了。![]()
<html>
<head>
<meta http-equiv="content-type" content="text/html;charset=utf-8"/>
<title>单选和复选title>
head>
<body>
<h4>单选:性别h4>
<form>
<label value="radio">男label>
<input name="sex" value="male"id="boy" type="radio"><br>
<label value="radio1">女label>
<input name="sex" value="female"id="girl" type="radio">
form>
<h4>微信公众号:从零开始学自动化测试h4>
<form>
<input id="c1"type="checkbox">selenium<br>
<input id="c2"type="checkbox">python<br>
<input id="c3"type="checkbox">appium<br>
body>
html>
![]()
1.首先是定位选择框的位置
3.先点击boy后,等十秒再点击girl,观察页面变化
1.勾选单个框,比如勾选selenium这个,可以根据它的id=c1直接定位到点击就可以了。
1.全部勾选,可以用到定位一组元素,从上面源码可以看出,复选框的type=checkbox,这里可以用xpath语法:.//*[@type='checkbox']
六、判断是否选中:is_selected()
1.有时候这个选项框,本身就是选中状态,如果我再点击一下,它就反选了,这可不是我期望的结果,那么可不可以当它是没选中的时候,我去点击下;当它已经是选中状态,我就不点击呢?那么问题来了:如何判断选项框是选中状态?
2.判断元素是否选中这一步才是本文的核心内容,点击选项框对于大家来说没什么难度。获取元素是否为选中状态,打印结果如下图。
3.返回结果为bool类型,没点击时候返回False,点击后返回True,接下来就很容易判断了,既可以作为操作前的判断,也可以作为测试结果的判断。
![]()
# coding:utf-8
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("file:///C:/Users/Gloria/Desktop/checkbox.html")
# 没点击操作前,判断选项框状态
s = driver.find_element_by_id("boy").is_selected()
print s
driver.find_element_by_id("boy").click()
# 点击后,判断元素是否为选中状态
r = driver.find_element_by_id("boy").is_selected()
print r
# 复选框单选
driver.find_element_by_id("c1").click()
# 复选框全选
checkboxs = driver.find_elements_by_xpath(".//*[@type='checkbox']")
for i in checkboxs:
i.click()
![]()
2.13 table表格定位
在web页面中经常会遇到table表格,特别是后台操作页面比较常见。本篇详细讲解table表格如何定位。
一、认识table
1.首先看下table长什么样,如下图,这种网状表格的都是table
![]()
DOCTYPE html>
<meta charset="UTF-8">
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<html>
<head>
<title>Table测试模板title>
head>
<body>
<table border="1" id="myTable">
<tr>
<th>QQ群th>
<th>QQ号th>
<th>群主th>
tr>
<tr>
<td>selenium自动化td>
<td>232607095td>
<td>YOYOtd>
tr>
<tr>
<td>appium自动化td>
<td>512200893td>
<td>YOYOtd>
tr>
table>
body>
html>
![]()
1.table页面查看源码一般有这几个明显的标签:table、tr、th、td
2.标示一个表格
3.标示这个表格中间的一个行
4. 定义表头单元格
5. 定义单元格标签,一组标签将将建立一个单元格, 标签必须放在 标签内
1.举个例子:我想定位表格里面的“selenium自动化”元素,这里可以用xpath定位:.//*[@id='myTable']/tbody/tr[2]/td[1]
对xpath语法不熟悉的可以看这篇Selenium2+python自动化7-xpath定位
四、打印表格内容
1.定位到表格内文本值,打印出来,脚本如下:
![]()
# coding:utf-8
from selenium import webdriver
import time
url = 'file:///C:/Users/Gloria/Desktop/table.html'
driver = webdriver.Firefox()
driver.get(url)
time.sleep(3)
t = driver.find_element_by_xpath(".//*[@id='myTable']/tbody/tr[2]/td[1]")
print t.text
![]()
2.14 加载Firefox配置(略,已在2.1.8讲过,请查阅2.1.8节课)
2.14-1 加载Chrome配置
chrome加载配置方法,只需改下面一个地方,username改成你电脑的名字(别用中文!!!)![]()
'--user-data-dir=C:\Users\username\AppData\Local\Google\Chrome\User Data'
# coding:utf-8
from selenium import webdriver
# 加载Chrome配置
option = webdriver.ChromeOptions()
option.add_argument('--user-data-dir=C:\Users\Gloria\AppData\Local\Google\Chrome\User Data')
driver = webdriver.Chrome(chrome_options=option)
driver.implicitly_wait(30)
driver.get("http://www.cnblogs.com/yoyoketang/")
![]()
1.做Wap测试的可以试下,伪装成手机访问淘宝,会出现触屏版
![]()
# coding:utf-8
from selenium import webdriver
option = webdriver.ChromeOptions()
# 伪装iphone登录
# option.add_argument('--user-agent=iphone')
# 伪装android
option.add_argument('--user-agent=android')
driver = webdriver.Chrome(chrome_options=option)
driver.get('http://www.taobao.com/')
![]()
2.15 富文本(richtext)
富文本编辑框是做web自动化最常见的场景,有很多小伙伴不知从何下手,本篇以博客园的编辑器为例,解决如何定位富文本,输入文本内容
一、加载配置
1.打开博客园写随笔,首先需要登录,这里为了避免透露个人账户信息,我直接加载配置文件,免登录了。

1.博客首页地址:bolgurl = "http://www.cnblogs.com/"
2.我的博客园地址:yoyobolg = bolgurl + "yoyoketang"
3.点击“新随笔”按钮,id=blog_nav_newpost
1.打开编辑界面后先不要急着输入内容,先sleep几秒钟
2.输入标题,这里直接通过id就可以定位到,没什么难点
3.接下来就是重点要讲的富文本的编辑,这里编辑框有个iframe,所以需要先切换