【语义分割系列:一】DeepLab v1 / v2 论文阅读翻译笔记
【语义分割系列:六】DeepLab v3 / v3+ 论文阅读翻译笔记
DeepLab v1
2015 ICLR
Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
0、Introduce
Abstract
- 当前的图像分割CNN是根据classification、object detection这种high-level semantics改编的,但CNN有invariance特点,故会丢失localization信息,即无法对像素点精确定位语义(low-level semantics)。然而我们需要的是精确地定位而不是抽象的空间细节。而本文提出的model,是CNN和PGM(概率图模型)的结合,对CNN最后一层加上fully connected CRFs,使得分割更精确。
- 在DCNN中重复最大池化和下采样带来的分辨率下降问题,分辨率的下降会丢失细节。DeepLab是采用的atrous(带孔)算法扩展感受野,获取更多的上下文信息。
- end-to-end
Method
DeepLab 是结合了深度卷积神经网络(DCNNs)和概率图模型(DenseCRFs)的方法
- 深度卷积神经网络(DCNNs)
第一步仍然采用了FCN得到 coarse score map并插值到原图像大小
使用Atrous convolution得到更dense且感受野不变的feature map - 概率图模型(DenseCRFs)
第二步借用fully connected CRF对从FCN得到的分割结果进行细节上的refine。
Problem
-
signal down-sampling
- 问题:DCNNs每一层重复执行下采样 (如max-pooling和downsampling),导致signal分辨率降低。
- 将stride改小,能得到更加dense的feature map,可是却也带来了另外一个问题即receptive field(RF)变小的问题。
- 将Hole(Atrous convolution)算法应用到DCNNs模型上来扩展感受野,获取更多的上下文信息。
-
spatial “insensitivity”(invariance)
- 问题:以获取图像中物体为核心的决策(High Level Vision Task,如图片分类、目标检测任务)需要空间不变性,即DCNNs的high-level的平移不变性(invariance),导致DCNNs做语义分割时定位精准度不够。
- 比如对于同一张图片进行空间变换(如平移、旋转),其图片分类结果是不变的。
- 对于图像分割等Low-Level Vision Task,对于一张图片进行空间变换后,其结果是改变的。
- 将DCNNs层的响应和 完全连接条件随机场(Fully Connected CRFs)结合(DeepLab是由两个非常成熟的模块(DCNN和CRFs)级联而成)
- 问题:以获取图像中物体为核心的决策(High Level Vision Task,如图片分类、目标检测任务)需要空间不变性,即DCNNs的high-level的平移不变性(invariance),导致DCNNs做语义分割时定位精准度不够。
High-Level & Low-level vision task
CNN适合于Hight-Level Vision Task(如图像分类),不太适合于Low-Level Vision Task(如图像分割、姿态估计)。
- lower level feature 通常是一些pattern
包括边缘检测,角点检测,颜色之类的对细节敏感、抽象度比较低的任务。
- high level feature 通常有更多的语义信息
目标检测、图像分类等对细节信息不敏感、抽象度比较高的任务。
CRF
to combine class scores computed by multi-way classifiers with the low-level information captured by the local interactions of pixels and edges or superpixels.
(将多路分类器计算的类得分 与 像素和边缘或超像素的局部交互捕获的低层信息结合起来)
我们的方法将每个像素看做CRF节点,利用长期依赖关系,并使用CRF推理直接优化 DCNN-driven cost
function。我们注意到传统的图像分割/边缘检测任务,对于完全连接的CRF,推理可以非常有效,特别是在语义分割的上下文中。
1、Architecture
空洞卷积 hole Atrous 原理+图解析+应用
1.1 Hole

由来
- deeplab仍然采用了FCN来得到score map
- 在ImageNet上预训练的VGG16权重上做finetune
- VGG16的全连接层转为卷积(此时 stride =32 ,不 dense)
stride = 输入尺寸/输出特征尺寸 - 得到更加dense的score map
- FCN 粗糙的处理方式
把一张500x500的输入图像,直接在第一个卷积层上conv1_1来了一个100的大padding来得到更加dense的score map - deeplab更加优雅的处理方式
- 1.为了更dense(stride =8),最后的两个池化层去掉了下采样:将VGG网络的pool4和pool5层的stride由原来的2改为了1。
减小stride导致了receptive field(RF)变小,对semantic info不利 - 2.pooling后的卷积层的卷积核改为了空洞卷积(Hole算法 ),扩大感受野,解决感受野变小问题。
- 1.为了更dense(stride =8),最后的两个池化层去掉了下采样:将VGG网络的pool4和pool5层的stride由原来的2改为了1。
- FCN 粗糙的处理方式
Hole
(Both large feature map & receptive field)
-
hole algorithm:up-sample the original filter by a factor of the strides(rate=2)
efficient dense sliding window feature extraction- standard convolution : responses at only 1/4 of the image positions
- convolve image with a filter “with holes”:responses at all image positions
-
RF and stride

按照公式,stride变小,要想保持receptive field不变,那么,就应该增大kernel size。于是就有了接下来的hole算法。
Example:
pooling layer stride = 2,convolution layer kernel size = 2,convolution layer第一个点的receptive field是{1,2,3,4},size为4.

为了得到更加dense的feature map,将pooling layer stride改为1,如果这个时候保持convolution layer的kernel size不变的话,可以看到,虽然是更dense了,可是感受野RF变小了 = {1,2,3}, size为3.

采用hole算法,在kernel里面增加“hole”,kernel size变大,相当于卷积的时候跨过stride减小额外带来的像素,就可以得到我们想要的RF.
卷积核直观上可以以通过对原卷积核填充0得到,不过在具体实现上填0会带来额外的计算量,所以实际上是通过 im2col函数(caffe)调整像素的位置实现的。

这样通过hole算法,我们就得到了一个8s(stride)的feature map,比起FCN的32s已经dense很多了,并且RF不变。
**conclusion:**感受野要在一个合理的区间,在语义与位置信息中谋求平衡,并辅之以dilated conv,扩大感受野、保持大的feature map的同时减少参数。
训练信息
- 损失函数:输出的特征图与ground truth下采样8倍做交叉熵和。
- 训练数据label:对原始Ground Truth进行下采样8倍,得到训练label。
- 预测数据label:对预测结果进行双线性上采样8倍,得到预测结果。
network

-
把最后的全连接层FC6、7、8改造成卷积层
-
pool4的stride由2变为1,则紧接着的conv5_1, conv5_2和conv5_3中hole size为2。
-
接着pool5由2变为1, 则后面的fc6中hole size为4。
-
fc7,8为标准卷积
-
由于Hole算法让feature map更加dense,所以网络直接用差值升采样就能获得很好的结果,而不用去学习升采样的参数了(FCN中采用了de-convolution)
1.2 CRF
localization challenge
-
DCNN的预测物体的位置是粗略的,没有确切的轮廓。
-
图像输入CNN是一个被逐步抽象的过程,原来的位置信息会随着深度而减少甚至消失。
Example:FCN-based model因为经过层层下采样和上采样(参数多,感受野大且重合),而丢失大量位置信息,最后的分类结果如下图所示,十分smooth(平滑),但我们需要的是sharp segmentation。

-
解决问题方向:
- 第一种是利用卷积网络中多层的信息预估边界
- 第二种是采样超像素表示,实质上是将定位任务交给低级的分割方法
CRFs for accurate localization
- CRF在传统图像处理上主要做平滑处理。
就是在决定一个位置的像素值时,会考虑周围邻居的像素值,这样能抹除一些噪音。 - 但对于CNN来说,short-range CRFs可能会起到反作用,因为我们的目标是恢复局部信息,而不是进一步平滑图像。
- 引入fully connected CRF来考虑全局的信息。
使用dilated conv,还避开了层层上采样,直接用bilinear interpolation(双线性插值)恢复到原状,然后进行fully-connected conditional random fields 通过邻域之间的锐化,得到最终分割结果。

CRF 计算公式
- E(x):整个模型的能量函数

- x:对全局pixels的概率预测分布
- xi:其中一个pixel的概率预测分布
- θi:一元势函数 unary potential function

- θij:二元势函数

K : Kernel数量 w : 权重
本文采用高斯核,并且任意两个像素点都有此项,故称为fully connected CRFs.
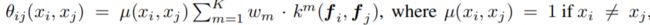
1.3 multi-scale prediction
- 多尺寸预测,希望获得更好的边界信息。
- 引入:与FCN skip layer类似。
- 实现:
- 在输入图片与前四个max pooling后添加MLP(多层感知机,第一层是128个3×33×3卷积,第二层是128个1×11×1卷积),得到预测结果。
- 最终输出的特征映射送到模型的最后一层辅助预测,合起来模型最后的softmax层输入特征多了5×128=6405×128=640个通道
- 效果不如dense CRF,但也有一定提高。最终模型是结合了Dense CRF与Multi-scale Prediction。

Experiment
测试细节:
| item | set |
|---|---|
| 数据集 | PASCAL VOC 2012 segmentation benchmark |
| DCNN模型 | 权重采用预训练的VGG16 |
| DCNN损失函数 | 交叉熵 |
| 训练器 | SGD,batch=20 |
| 学习率 | 初始为0.001,最后的分类层是0.01。每2000次迭代乘0.1 |
| 权重 | 0.9的动量, 0.0005的衰减 |
- DeepLab由DCNN和CRF组成,训练策略是分段训练,即DCNN的输出是CRF的一元势函数,在训练CRF时是固定的。
- 在对DCNN做了fine-tune后,对CRF做交叉验证。这里使用 ω2=3 和 σγ=3 在小的交叉验证集上寻找最佳的 ω1,σα,σβ
References
DeepLab系列
[Paper Reading] DeepLab v1 & v2
论文阅读笔记:图像分割方法deeplab以及Hole算法解析
精读深度学习论文(20) DeepLab V1
Conditional Random Fields as Recurrent Neural Networks
网络结构
DeepLab v2
2016 CVPR
DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
❤ kazuto1011/deeplab-pytorch :PyTorch implementation of DeepLab v2 on COCO-Stuff / PASCAL VOC
isht7/pytorch-deeplab-resnet :DeepLab resnet v2 model in pytorch
Introduce
DeepLabv1 在三个方向努力解决,但是问题依然存在:
特征分辨率的降低、物体存在多尺度,DCNN 的平移不变性。
特点:
-
atrous convolution
-
ASPP ( atrous spatial pyramid pooling) 用多尺度获得更好的分割效果
-
合并深度卷积网络和概率图模型方法,增强对物体边界的定位。
-
基础层由VGG16转为ResNet
和v1不同:
- 通过多尺度输入处理或者多孔空间金字塔池化,可以更好地分割物体。
- DeepLab采用最新的ResNet图像分类深度卷积神经网络构建,与原来基于VGG-16的网络相比,取得了更好的语义分割性能。
Astrous conv

(a)sparse feature extraction
采用标准卷积的稀疏特征提取。
input feature 是由 stride=2 的 maxpooling 产生的,分辨率低
(b)Dense feature extradction
input feature 是由 stride=1 的 maxpooling 产生的,和标准卷积比,感受野小。为了和标准卷积感受野一样大,使用空洞卷积来增加kernal size来增加感受野
计算:
1-D input signal x[i]
filter w[k] of length K
速率参数 r 对应于采样输入信号的步长(标准卷积是速率r = 1的特例,上图空洞卷积 r=2)
the output y[i] : 
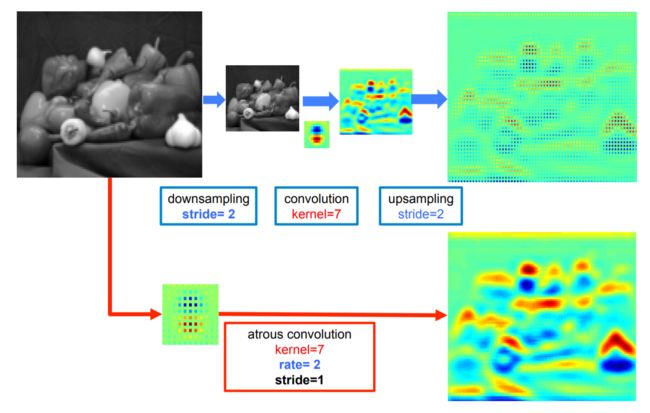
- 低分辨率输入 feature map的标准卷积 sparse feature extraction
FCN等网络重复使用max-pooling和striding会显著降低生成的feature map的空间分辨率(32倍),他们的解决措施是上采样以及反卷积,但这需要额外的内存和时间。
下采样 - 卷积 - 上采样
- 高分辨率输入 feature map的空洞卷积 r=2 Dense feature extraction
即本文提倡的无采样卷积
- 第一种是插入空洞(零元素)或者对输入特征地图同等稀疏地采样,来对滤波器进行上采样。
- 第二种方法,通过一个等于atrous convolution rate r的因子对输入特征图进行子采样,对每个 r×r 可能的偏移,消除隔行扫描生成一个  降低的分辨率图。
接下来对这些中间特征图使用标准卷积,隔行扫描生成原始图像分辨率。
ASPP
使用多个不同采样率上的多个并行多孔卷积层。每个采样率上提取的特征再用单独的分支处理,融合生成最后的结果。

多孔空间金字塔池化(ASPP)。为了分类中间像素(橙色),ASPP用不同采样率的多个并行滤波器开发了多尺度特征。视野有效区用不同的颜色表示。

(a)DeepLab-LargeFOV 使用 rate=12的空洞卷积
(b)DeepLab-ASPP 使用 不同 rate 的多个 filter 在 multiple scales 获得物体和内容,有不小的提升。
CRF
全连接条件随机场 用于精确边界恢复
Model

- 一个深度卷积神经网络,比如VGG-16或ResNet-101,采用全卷积的方式,用多孔卷积减少信号降采样的程度(从32x降到8x)。
- 在双线性内插值阶段,增大特征地图到原始图像分辨率。
- 用条件随机场优化分割结果,更好的抓取物体边缘。
References
DeepLab v2 翻译 好!