sql
sql有些生疏,特
对于满足SQL92标准的SQL语句
select foo,count(foo) from pokes where foo>10 group by foo having count(*)>5 order bu foo
from --> where --> group by--> having --> select --> order by
from计算关系
where就要指定条件对记录进行筛选
group by将数据划分为多个分组
having 筛选分组
select 产生查询结果
order by 对结果集进行排序
挥手建一个表
create table sb
(
id VARCHAR(50),
user VARCHAR(50)
);INSERT into sb(id,user) VALUES('node1','a+sqld');
INSERT into sb(id,user) VALUES('node1','a');
INSERT into sb(id,user) VALUES('node2','b+SQL');
INSERT into sb(id,user) VALUES('node2','b-SQL');
INSERT into sb(id,user) VALUES('node3','c+SQLd');
INSERT into sb(id,user) VALUES('node3','c-sqld');
INSERT into sb(id,user) VALUES('node4','d+SQL');
INSERT into sb(id,user) VALUES('node4','d-SQL');
INSERT into sb(id,user) VALUES('node4','DSQL');思路:以id进行分组,having筛选分组,查询分组后次数大于2的
select id from sb GROUP BY id HAVING COUNT(id)>2 ;思路:order by 进行排序 可取值desc asc
select id ,user from sb GROUP BY id HAVING COUNT(id)>2 ORDER BY user desc ;注意: 打印次数,必须给having后的字段起别名
select COUNT(id) idNum ,id,user from sb GROUP BY id HAVING idNum>2 ;注意:也不用关注查询数据的大小写
select * from sb WHERE user like '%sql%'(1)、找出字段中含有sqld的id
select id,user from sb where user like '%sqld%'(2)、在结果集中找sql出现次数多于1的id
注意:中间结果集作为一张表进行查询要起别名,select * from table
第一步:统计所有id以及id出现次数
select id, count(*) idCount ,user from sb where user like '%sql%' group by idselect id ,idCount,user from
(select id, count(*) idCount ,user from sb where user like '%sql%' group by id) a
where idCount>1


select id, user from (select id,user from sb where user like '%sqld%') group by id HAVING count(id)>1(3)、如果打印次数,要起别名,having 做统计用--(2)后者比较笨的办法了,不建议使用
select count(id) countId , id, user from (select id,user from sb where user like '%sqld%') as sqls group by id HAVING countId>1
如下图
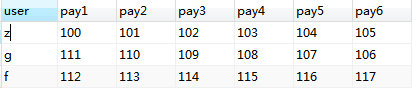
select *
from (
select user,month,pay_amount,
ROW_COUNT() over ( partition by user order by pay_amount) as pay_amount_rank
from(
select user,pay1 as pay_amount,1 as month from user_pay_log
union all
select user,pay2 as pay_amount,2 as month from user_pay_log
union all
select user,pay3 as pay_amount,3 as month from user_pay_log
union all
select user,pay4 as pay_amount,4 as month from user_pay_log
union all
select user,pay5 as pay_amount,5 as month from user_pay_log
union all
select user,pay6 as pay_amount,6 as month from user_pay_log
) t1
)t2
where pay_amount_rank=1;

