Ambari学习笔记:以本地仓库自动搭建hadoop集群环境
测试平台:Ubuntu_server_16.04_x64
准备好一台虚拟机,安装vmtool以设置共享文件夹:
sudo mkdir /mnt/cdrom
mount -tro iso9660 /dev/cdrom /mnt/cdrom
sudo tar -vxzf /mnt/cdrom/VMwareTools
cd vmware-tools-distrib
./vmware-install.pl
rm -rf ../vmware-tools-distrib
ln -s /mnt/hgfs/shared_dir /home/daya/shared_dir(此句在重启后执行)创建好root账户:
sudo passwd root
Requirements
首先看下abmari的一些前置需求与兼容性,看是否满足:
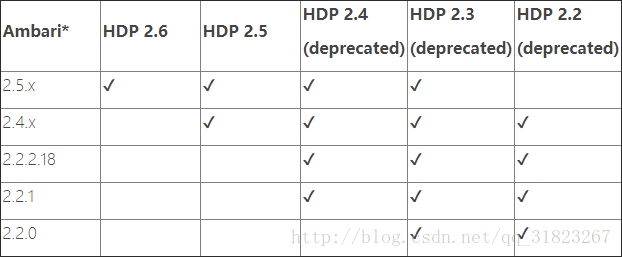
满足
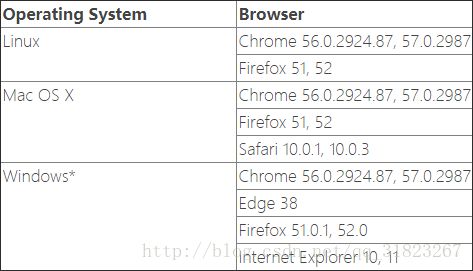
浏览器需要安装Ubuntu桌面,必要时再进行安装。

安装openssl:
sudo apt-get install openssh-server -y
安装Python2.7:
sudo apt-get install python2.7 -y

安装JDK:
cp /home/daya/shared_dir/jdk-8u144-linux-x64.tar.gz /usr/
tar -zxvf jdk-8u144-linux-x64.tar.gz
nano /etc/environment修改并更新环境变量。
Environment
配置无密登录与root登录:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
nano /etc/ssh/sshd_config
"PermitRootLogin yes"安装NTP服务同步时钟:
apt-get install ntp
update-rc.d ntp defaults复制虚拟机,并修改各机的/etc/hosts与/etc/hostname文件:
127.0.0.1 localhost
127.0.1.1 s3
192.168.200.105 s1
192.168.200.106 s2
192.168.200.107 s3
# The following lines are desirable for IPv6 capable hosts
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters 配置本地仓库
搭建web服务器
使用tomcat搭建web服务器,详见此文。之前搭建过tomcat的Ubuntu虚拟机磁盘不足了,选择在windows宿主机上使用tomcat搭建web服务器。windows上安装tomcat非常简单,直接解压然后设置CATALINA_HOME与JAVA_HOME即可。
下载本地tarball包
官方下载地址
将三个tarball包解压到tomcat的.\webapps\ROOT目录下,修改.\webapps\ROOT\ambari\ubuntu16\ambari.list与.\webapps\ROOT\HDP\ubuntu16\hdp.list,将url的hostname改为web服务器的ip地址:
http://192.168.1.103:8080/ambari/ubuntu16/
http://192.168.1.103:8080/HDP/ubuntu16/
http://192.168.1.103:8080/HDP-UTILS-1.1.0.21/repos/ubuntu16启动web服务器:
c:\DevProgram\apache-tomcat-9.0.0.M26\bin\startup.bat将修改的ambari.list复制到需要安装Ambari Server/Agent主机的/etc/apt/sources.list.d/目录下:
cp /home/daya/shared_dir/ambari.list /etc/apt/sources.list.d/
sudo apt-key adv --recv-keys --keyserver keyserver.ubuntu.com B9733A7A07513CAD
sudo apt-get updateAmbari Server/Agent安装与配置
Ambari Server(s1)
apt-get install ambari-server(SSD速度飞快)
ambari-server setup
ambari-server startAmbari Agent(s2,s3)
这步手动安装实属无奈,用web自动安装agent会报错,不知道怎么解决。
apt-get install ambari-agent
nano /etc/ambari-agent/conf/ambari-agent.ini修改”hostname=s1”,启动:
ambari-agent start自动配置hadoop集群
注意自定义JAVA_HOME:/usr/jdk1.8.0_144。
由于三台服务器未安装图形桌面,在windows宿主机中用浏览器进入Ambari管理页面进行hadoop集群安装:http://192.168.200.105:8080。
在HDP页面选择使用本地仓库,移除不需要的系统支持,修改Base URL:
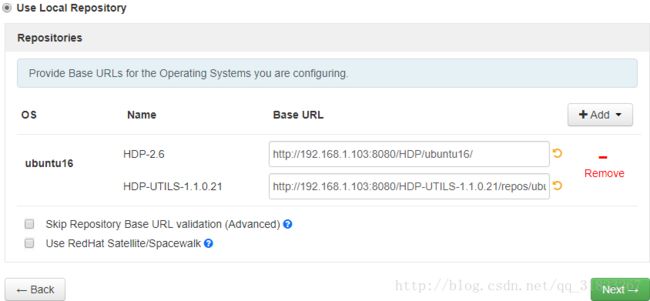
输入主机名:
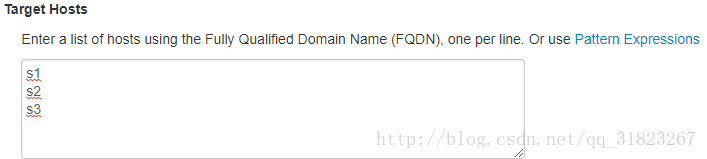
因为在windows浏览器中无法访问Ubuntu中的文件,我们手动将私钥信息复制到对话框:
cat /root/.ssh/id_rsa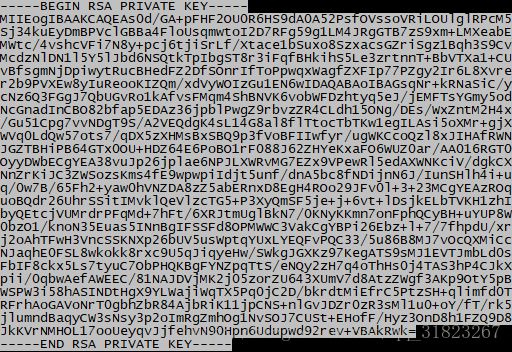
选择的组件与分配如下:

下一步正确输出所有配置信息后等待完成即可,速度挺慢的,很吃硬盘跟CPU:

错误信息
内存不足
等了好久结果启动出错,提示信息为内存不足,扩大虚拟机内存解决。
hosts错误
将虚拟机内存扩大后又出现错误,具体描述为:除了HDFS之外的服务均无法启动,其中Yarn的错误日志为”:50070:Connection refused”。在这块卡了好久,使用JPS命令看到namenode是启动的,端口50070也是处于监听状态,但是50070页面除了本机之外的另两台主机均无法访问。在网上搜索无果后,注意到一个细节,在使用netstat -l查看监听端口时发现:
![]()
50070端口被绑定到了127.0.1.1上去了!
将hosts文件中的127.0.1.1一行注释掉,解决!
HIVE2错误
s2报错:”returned 1. SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/hdp/2.6.1.0-129/hive2/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/hdp/2.6.1.0-129/hadoop/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]”
jar包重复,删除掉其中一个:
mv log4j-slf4j-impl-2.6.2.jar log4j-slf4j-impl-2.6.2.jar.baks2再次报错:”com.mysql.jdbc.exceptions.jdbc4.CommunicationsException : Communications link failure”,修改/etc/hive2/conf/下的hive-site.xml,并使web页面的配置与其保持一致:
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://localhost/hive?createDatabaseIfNotExist=truevalue>
<description>JDBC connect string for a JDBC metastoredescription>
property><property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
<description>Driver class name for a JDBC metastoredescription>
property>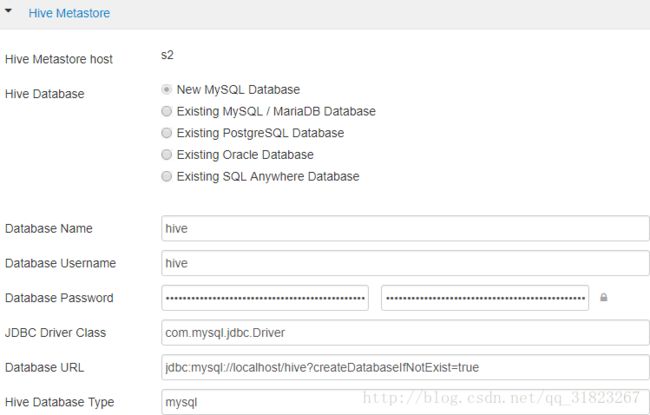
spark错误
“‘curl -sS -L -w ‘%{http_code}’ -X PUT –data-binary @/tmp/spark2/spark2-hdp-yarn-archive.tar.gz -H ‘Content-Type: application/octet-stream’ ‘http://s1:50070/webhdfs/v1/hdp/apps/2.6.1.0-129/spark2/spark2-hdp-yarn-archive.tar.gz?op=CREATE&user.name=hdfs&overwrite=True&permission=444’ 1>/tmp/tmpT4cIBk 2>/tmp/tmpEdq0e7’ returned 2. curl: option –data-binary: out of memory”
参考网站,暂未解决。
削减服务的集群
削减部分服务已验证ambari搭建hadoop集群的可行性:
