ElasticSearch入门笔记 1 —— 初识与本机环境配置
1 入门必知
Elasticsearch是一个实时分布式搜索和分析引擎。它让你以前所未有的速度处理大数据成为可能。
它用于全文搜索、结构化搜索、分析以及将这三者混合使用:
-
维基百科使用Elasticsearch提供全文搜索并高亮关键字,以及输入实时搜索(search-as-you-type)和搜索纠错(did-you-mean)等搜索建议功能。
-
英国卫报使用Elasticsearch结合用户日志和社交网络数据提供给他们的编辑以实时的反馈,以便及时了解公众对新发表的文章的回应。
-
StackOverflow结合全文搜索与地理位置查询,以及more-like-this功能来找到相关的问题和答案。
- Github使用Elasticsearch检索1300亿行的代码。
但是Elasticsearch不仅用于大型企业,它还让像DataDog以及Klout这样的创业公司将最初的想法变成可扩展的解决方案。Elasticsearch可以在你的笔记本上运行,也可以在数以百计的服务器上处理PB级别的数据。
Elasticsearch所涉及到的每一项技术都不是创新或者革命性的,全文搜索,分析系统以及分布式数据库这些早就已经存在了。它的革命性在于将这些独立且有用的技术整合成一个一体化的、实时的应用。它对新用户的门槛很低,当然它也会跟上你技能和需求增长的步伐。
如果你打算看这本书,说明你已经有数据了,但光有数据是不够的,除非你能对这些数据做些什么事情。
很不幸,现在大部分数据库在提取可用知识方面显得异常无能。的确,它们能够通过时间戳或者精确匹配做过滤,但是它们能够进行全文搜索,处理同义词和根据相关性给文档打分吗?它们能根据同一份数据生成分析和聚合的结果吗?最重要的是,它们在没有大量工作进程(线程)的情况下能做到对数据的实时处理吗?
这就是Elasticsearch存在的理由:Elasticsearch鼓励你浏览并利用你的数据,而不是让它烂在数据库里,因为在数据库里实在太难查询了。
2 ES的定位
Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎。无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
但是,Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
不过,Elasticsearch不仅仅是Lucene和全文搜索,我们还能这样去描述它:
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 分布式的实时分析搜索引擎
- 可以扩展到上百台服务器,处理PB级结构化或非结构化数据
而且,所有的这些功能被集成到一个服务里面,你的应用可以通过简单的RESTful API、各种语言的客户端甚至命令行与之交互。
上手Elasticsearch非常容易。它提供了许多合理的缺省值,并对初学者隐藏了复杂的搜索引擎理论。它开箱即用(安装即可使用),只需很少的学习既可在生产环境中使用。
Elasticsearch在Apache 2 license下许可使用,可以免费下载、使用和修改。
随着你对Elasticsearch的理解加深,你可以根据不同的问题领域定制Elasticsearch的高级特性,这一切都是可配置的,并且配置非常灵活。
3 配置标准
Elasticsearch 是一个需要不停调参数的庞然大物 , 从其自身的设置到 JVM 层面, 有着无数的参数需要根据业务的变化进行调整。最近采用 3 台 AWS r3.2xlarge , 32GB, 4 核, 构建了一套日均日志量过亿的 EFK 套件。经过不停地查阅文档进行调整优化 , 目前日常 CPU 占用只在 30% , 大部分 Kibana 内的查询都能在 5s ~ 15s 内完成。
CPU
- 多核胜过高性能单核 CPU
- 实践中发现, 在高写入低查询的场景下, 日常状态时 , CPU 还能基本应付, 一旦进行 kibana 上的查询或者 force merge 时, CPU 会瞬间飙高, 从而导致写入变慢, 进而引发需要很长一段实践 cpu 才能降下来。
Mem
- Elasticsearch 需要使用大量的堆内存, 而 Lucene 则也需要消耗大量 非堆内存 (off-heap)。推荐给 es 设置本机内存的一半, 如 32G 内存的机器上, 设置 -Xmx16g -Xms16g 剩下的内存会被 Lucene 占用。
- 如果你不需要对分词字符串做聚合计算(例如,不需要 fielddata )可以考虑降低堆内存。堆内存越小,Elasticsearch(更快的 GC)和 Lucene(更多的内存用于缓存)的性能越好。
- 由于 JVM 的一些机制 , 内存并不是越大越好, 推荐最大只设置到 31 GB 。
- 禁用 swap
sudo swapoff -a
4 安装与插件配置
4.1 tar.gz 安装包安装 Elasticsearch
首先打开官网下载页 https://www.elastic.co/downloads/elasticsearch ,下载对应的 elasticsearch-5.3.0.tar.gz 文件。然后在文件的当前目录,通过 tar 命令解压安装包完成安装。
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.3.0.tar.gz
tar -xzf elasticsearch-5.3.0.tar.gz
cd elasticsearch-5.3.0/4.2 配置文件
在启动运行前,我们介绍下 Elasticsearch 配置文件,即 config/elasticsearch.yml。这里我们需要在配置中增加以下配置,为了允许 elasticsearch-head 运行时的跨域:
# allow origin
http.cors.enabled: true
http.cors.allow-origin: "*"(其他具体配置见官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/settings.html )
4.3 运行与关闭
一般在后台起守护线程启动 Elasticsearch,在命令行加入 -d 指定。自然,也可以加入 -p ,可将进程 ID 记录到文件中。
命令行前台执行:
./bin/elasticsearchcmd后台执行:
./bin/elasticsearch -d后台执行的关闭
ps -ef | grep 'pwd'
ps aux | grep elasticsearch #两种方法都能找到对应进程的pid
kill -7
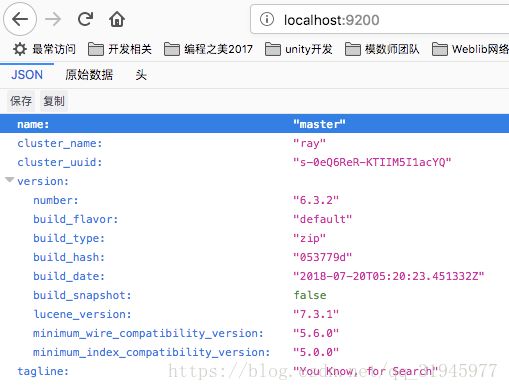
访问默认配置下的 http://localhost:9200/ ,可以看到成功运行的案例,返回的 JSON 页面:
二、可视化插件 elasticsearch-head 安装
官方 GitHub 地址:https://github.com/mobz/elasticsearch-head。安装也很简单,安装 README 步骤走就好了。
下载 master 分支项目,然后在项目当前目录通过 npm 安装,再通过 npm 运行启动该项目即可。
git clone git://github.com/mobz/elasticsearch-head.git
cd elasticsearch-head
npm install
npm run start
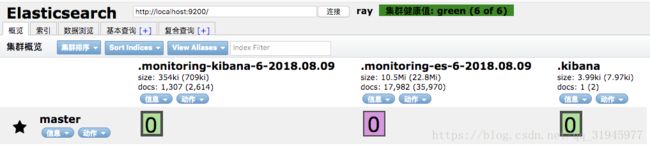
访问 http://localhost:9100/ ,右上角表示连接上了上小节启动的 Elasticsearch。如图