【机器学习】主元分析(PCA)以及与SVD的区别联系
参考文章:如何理解主元分析(PCA)?
主元分析的目的是降低数据的维度。主元分析也就是PCA,主要用于数据降维。
1 什么是降维?
比如说有如下的房价数据:
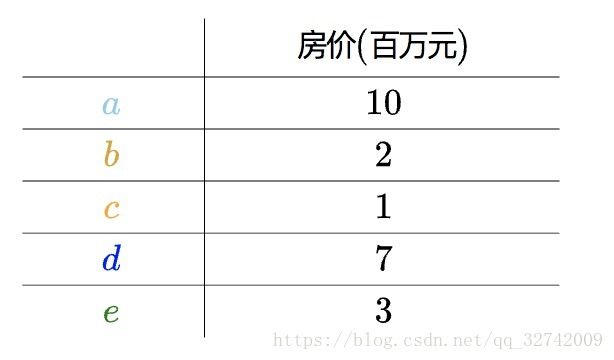
这种一维数据可以直接放在实数轴上:
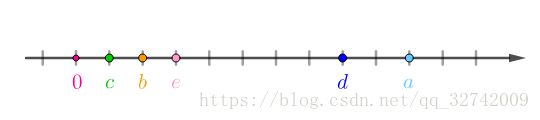
不过数据还需要处理下,假设房价样本用![]() 表示,那么均值为:
表示,那么均值为:
![]()
然后平移到以均值![]() 为原点:
为原点:

以![]() 为原点的意思是,以
为原点的意思是,以![]() 为0,那么上述表格的数字就需要修改下:
为0,那么上述表格的数字就需要修改下:

这个过程称为“中心化”。“中心化”处理的原因是,这些数字后继会参与统计运算,比如求样本方差,中间就包含了![]() :
:
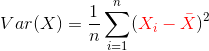
说明下,虽然样本方差的分母应该是![]() ,这里分母采用
,这里分母采用![]() 是因为这样算出来的样本方差
是因为这样算出来的样本方差![]() 为一致估计量,不会太影响计算结果并且可以减少运算负担。
为一致估计量,不会太影响计算结果并且可以减少运算负担。
用“中心化”后的数据就可以直接算出“房价”的样本方差:
![]()
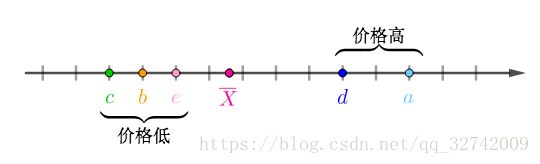
“中心化”之后可以看出数据大概可以分为两类:
现在新采集了房屋的面积,可以看出两者完全正相关,有一列其实是多余的:

求出房屋样本、面积样本的均值,分别对房屋样本、面积样本进行“中心化”后得到:

房价(![]() )和面积(
)和面积(![]() )的样本协方差是这样的(这里也是用的一致估计量):
)的样本协方差是这样的(这里也是用的一致估计量):

可见“中心化”后的数据可以简化上面这个公式,这点后面还会看到具体应用。
把这个二维数据画在坐标轴上,横纵坐标分别为“房价”、“面积”,可以看出它们排列为一条直线:
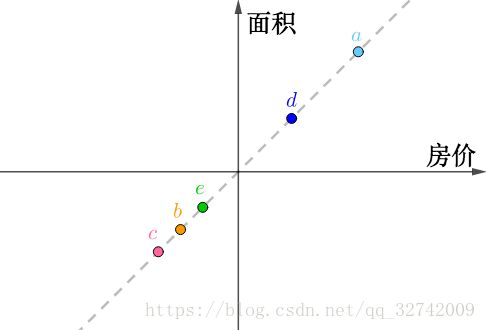
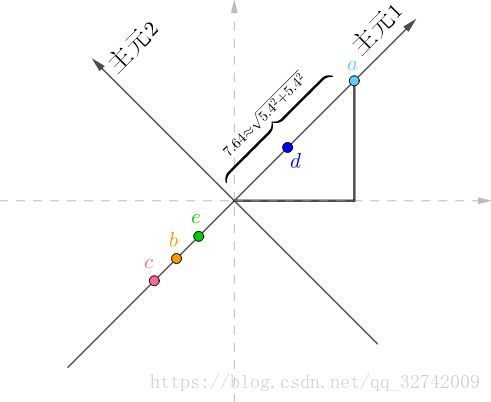
如果旋转坐标系,让横坐标和这条直线重合:

旋转后的坐标系,横纵坐标不再代表“房价”、“面积”了,而是两者的混合(术语是线性组合),这里把它们称作“主元1”、“主元2”,坐标值很容易用勾股定理计算出来,比如![]() 在“主元1”的坐标值为:
在“主元1”的坐标值为:
很显然![]() 在“主元2”上的坐标为0,把所有的房间换算到新的坐标系上:
在“主元2”上的坐标为0,把所有的房间换算到新的坐标系上:
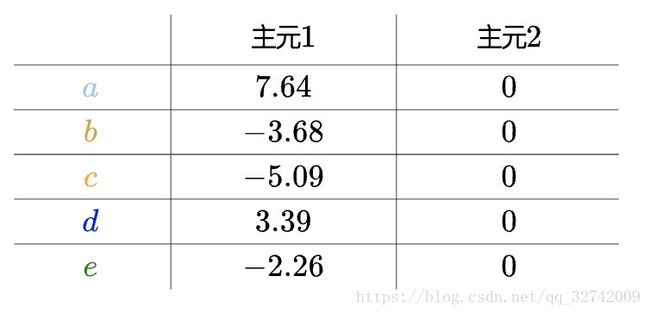
因为“主元2”全都为0,完全是多余的,我们只需要“主元1”就够了,这样就又把数据降为了一维,而且没有丢失任何信息:
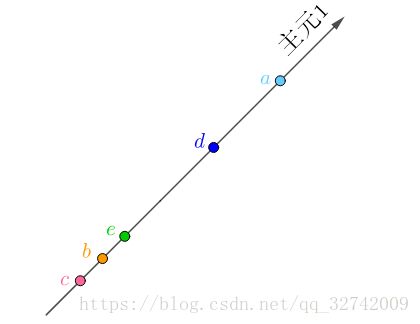
2 非理想情况如何降维?
上面是比较极端的情况,就是房价和面积完全正比,所以二维数据会在一条直线上。
现实中虽然正比,但总会有些出入:

把这个二维数据画在坐标轴上,横纵坐标分别为“房价”、“面积”,虽然数据看起来很接近一条直线,但是终究不在一条直线上:

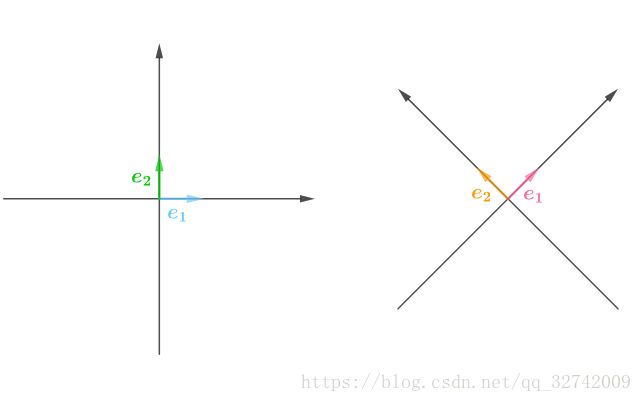
那么应该怎么降维呢?分析一下,从线性代数的角度来看,二维坐标系总有各自的标准正交基(也就是两两正交、模长为1的基),![]() :
:
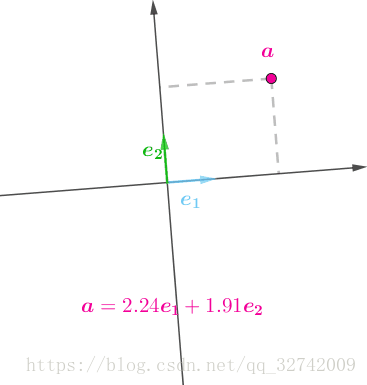
在某坐标系有一个点,![]() ,它表示在该坐标系下标准正交基
,它表示在该坐标系下标准正交基![]() 的线性组合:
的线性组合:
![]()
只是在不同坐标系中,![]() 的值会有所不同(旋转的坐标表示不同的坐标系):动图,建议看原网站。
的值会有所不同(旋转的坐标表示不同的坐标系):动图,建议看原网站。
因为![]() 到原点的距离
到原点的距离![]() 不会因为坐标系改变而改变:
不会因为坐标系改变而改变:
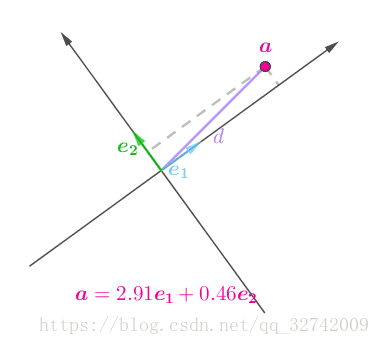
而:
![]()
所以,在某坐标系下分配给![]() 较多,那么分配给
较多,那么分配给![]() 的就必然较少,反之亦然。最极端的情况是,在某个坐标系下,全部分配给了
的就必然较少,反之亦然。最极端的情况是,在某个坐标系下,全部分配给了![]() ,使得
,使得![]() :
:
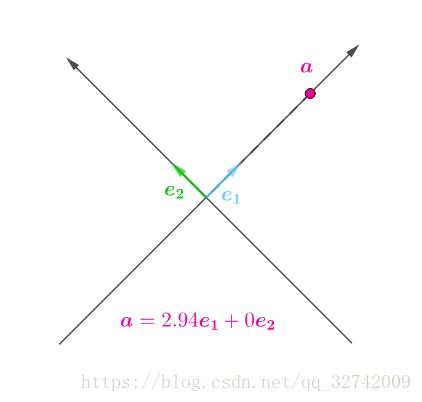
那么在这个坐标系中,就可以降维了,去掉![]() 并不会丢失信息:
并不会丢失信息:
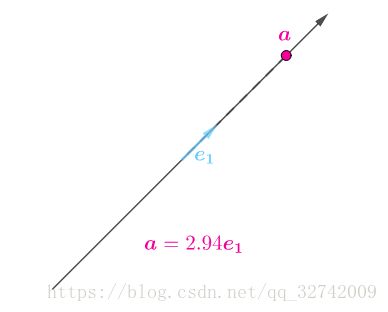
如果是两个点![]() ,情况就复杂一些:
,情况就复杂一些:

为了降维,应该选择尽量多分配给![]() ,少分配给
,少分配给![]() 的坐标系。
的坐标系。
3 主元分析(PCA)
具体怎么做呢?假设有如下数据:(a、b为样本,X、Y为特征)
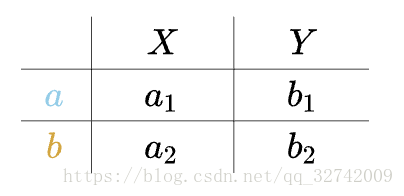
上面的数据这么解读,表示有两个点:
![]()
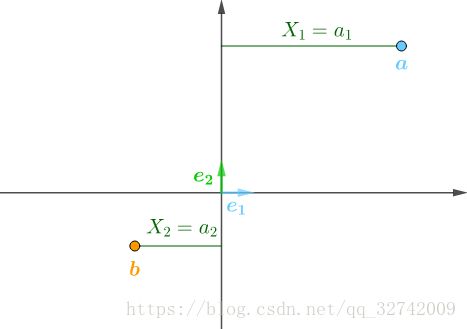
这两个点在初始坐标系下(也就是自然基![]() )下坐标值为:
)下坐标值为:
![]()
图示如下:
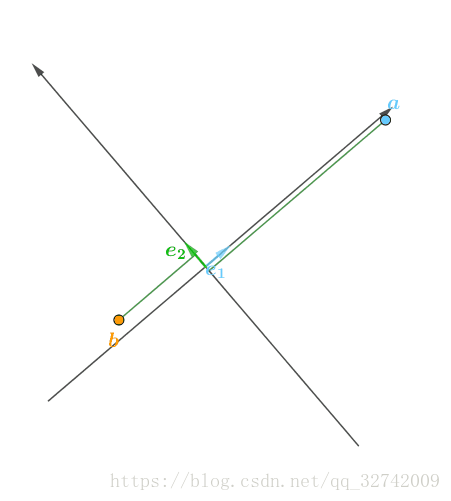
随着坐标系的不同,![]() 的值会不断变化:
的值会不断变化:
要想尽量多分配给![]() ,借鉴最小二乘法(请参考如何理解最小二乘法)的思想,就是让:
,借鉴最小二乘法(请参考如何理解最小二乘法)的思想,就是让:

要求这个问题,先看看![]() 怎么表示,假设:
怎么表示,假设:
![]()
根据点积的几何意义(如何通俗地理解协方差和点积)有:
![]()
![]()
那么:
上式其实是一个二次型(可以参看如何通俗地理解二次型):

这里矩阵![]() 就是二次型,是一个对称矩阵,可以进行如下的奇异值分解(可以参看如何通俗地理解奇异值分解):
就是二次型,是一个对称矩阵,可以进行如下的奇异值分解(可以参看如何通俗地理解奇异值分解):
![]()
其中,![]() 为正交矩阵,即
为正交矩阵,即![]() 。
。
而![]() 是对角矩阵:
是对角矩阵:
![]()
其中,![]() 是奇异值,
是奇异值,![]() 。
。
将![]() 代回去:
代回去:
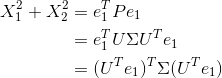
因为![]() 是正交矩阵,所以令:
是正交矩阵,所以令:
![]()
所得的![]() 也是单位向量,即:
也是单位向量,即:
![]()
继续回代:
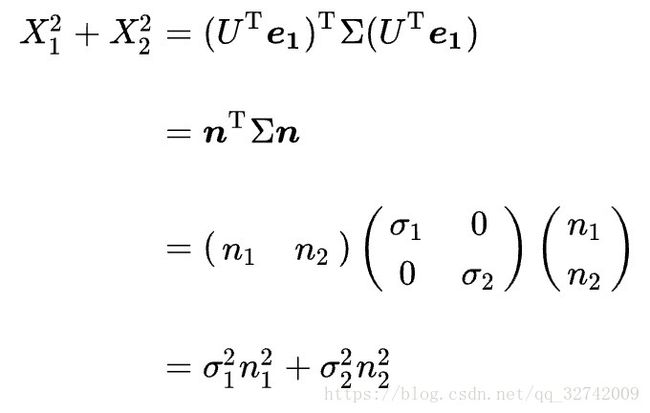
最初求最大值的问题就转化为了:

感兴趣可以用拉格朗日乘子法计算上述条件极值(参看如何通俗地理解拉格朗日乘子法以及KKT条件),结果是当![]() 时取到极值。
时取到极值。
因此可以推出要寻找的主元1,即:

4 协方差矩阵
上一节的数据:

我们按行来解读,得到了两个向量![]() :
:

在这个基础上推出了矩阵:
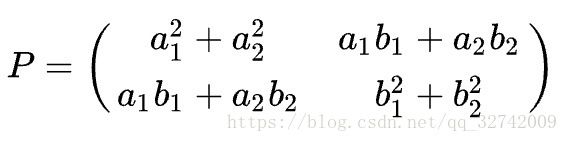
这个矩阵是求解主元1、主元2的关键。
如果我们按列来解读,可以得到两个向量![]() :
:
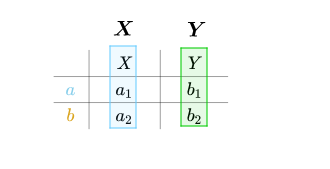
即:
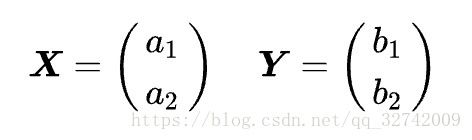
那么刚才求出来的矩阵就可以表示为:

之前说过“中心化”后的样本方差(关于样本方差、协方差可以参看这篇文章:如何通俗地理解协方差和点积):

样本协方差为:

两相比较可以得到一个新的矩阵,也就是协方差矩阵:
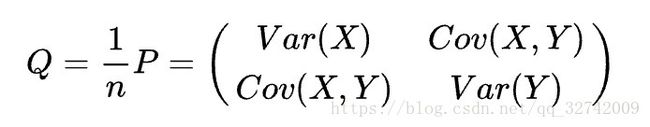
![]() 都可以进行奇异值分解:
都可以进行奇异值分解:
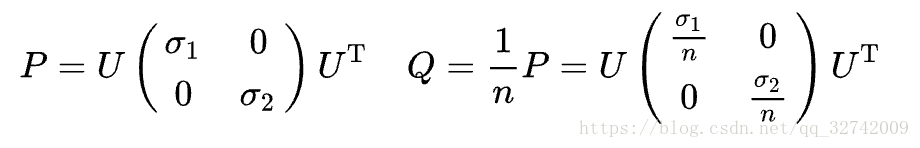
可见,协方差矩阵![]() 的奇异值分解和
的奇异值分解和![]() 相差无几,只是奇异值缩小了
相差无几,只是奇异值缩小了![]() 倍,但是不妨碍奇异值之间的大小关系,所以在实际问题中,往往都是直接分解协方差矩阵
倍,但是不妨碍奇异值之间的大小关系,所以在实际问题中,往往都是直接分解协方差矩阵![]() 。
。
5 实战
回到使用之前“中心化”了的数据:
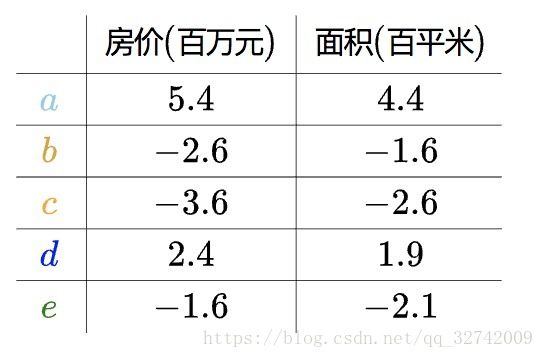
这些数据按行,在自然基下画出来就是:
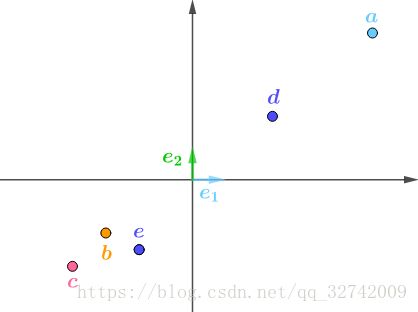
按列解读得到两个向量:
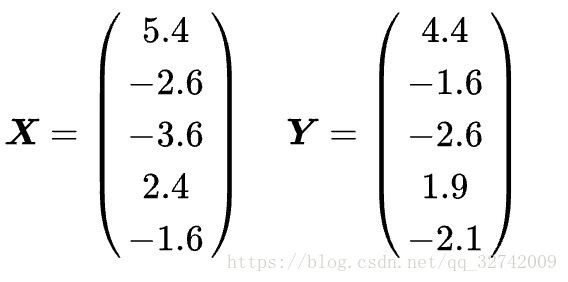
组成协方差矩阵:
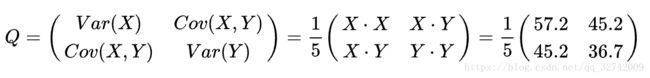
进行奇异值分解:

根据之前的分析,主元1应该匹配最大奇异值对应的奇异向量,主元2匹配最小奇异值对应的奇异向量,即:

以这两个为主元画出来的坐标系就是这样的:
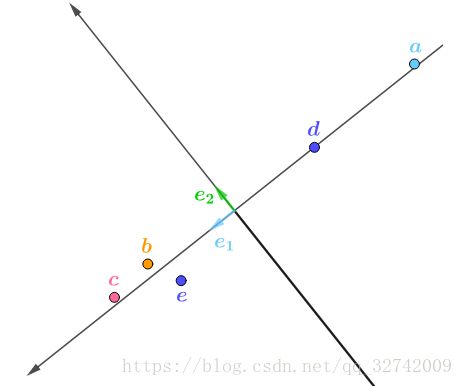
如下算出新坐标,比如对于![]() :
:
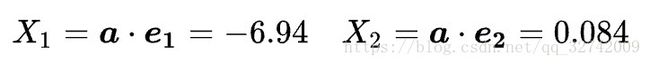
以此类推,得到新的数据表:

主元2整体来看,数值很小,丢掉损失的信息也非常少,这样就实现了非理想情况下的降维。