目标检测——opencv cascade训练的一般使用流程与常见问题
opencv在2.4.0之后推出了能够支持HAAR、LBP、HOG三种特征的供cascade分类算法训练的程序,可以在opencv的bin文件目录下找到该opencv_traincascade.exe程序以及用来创建样本的opencv_createsamples.exe程序。(当然opencv也保留了之前只支持harr特征训练的opencv_haartraining.exe)
训练流程如下:
- 搭建环境,准备样本
新建一个空的文件夹training3(这个文件夹名随便起,但是要和后面的样本路径对应起来),将opencv_traincascade.exe和opencv_createsamples.exe从opencv的bin文件夹中拷贝至该文件夹中,并在training当前目录下创建两个新的文件夹pos和neg分别用来存放正样本和负样本。这里建议正样本和负样本的数量比例最好在1:2和1:3之间(为了尽可能地保证训练效果,当然不在这个比例之间也可训练),负样本图像中不要包含检测的目标并且要尽可能的多样化。我这里准备了300个车辆侧身的样本和800个负样本。
- 生成样本描述文件
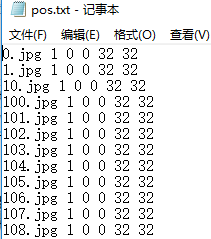
在pos目录下新建一个txt文件,在txt文件中输入dir /b > pos.txt 后保存,改后缀名为.bat生成脚本文件,双击该.bat文件运行可生成一个pos.txt,在pos.txt文本中ctrl+H将所有的jpg替换成jpg 1 0 0 32 32。jpg后面的五个数字信息分别表示样本中目标个数、目标在图像中的起始位置x、y、样本的尺寸大小width、height。因为我的正样本只包含目标,所以样本的起始位置为0 0,训练之前最好将正样本规格化为同一尺寸(最好是8的倍数,我这里用的是32*32,也可以56*56等等,但是不推荐正样本尺寸太大),负样本不需要规格化,但是要保证负样本的尺寸普遍大于正样本的尺寸,实在不放心可以把负样本给规格化了保证都大于正样本的尺寸。pos.txt文件中不应该包含除样本实例之外的条目(刚生成之后的pos.txt后面必然会有之前.bat的条目以及pos.txt自身的条目,将这些条目删除),pos.txt完成之后应该如下图所示:
然后就可以生成正样本vec文件了:返回到training3目录下,新建一个createsamples.txt文档中编辑
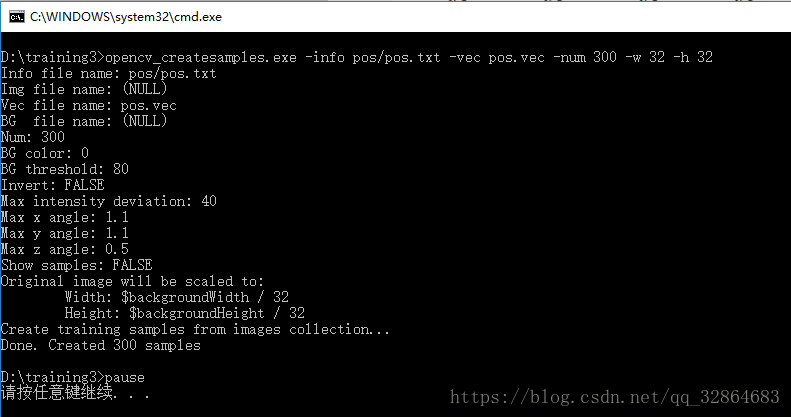
opencv_createsamples.exe -info pos/pos.txt -vec pos.vec -num 300 -w 32 -h 32
pause
其中-info表示指定的描述文件,-vec指定输出的vec文件名,-w-h表示规定的样本尺寸,-num表示创建的样本数目,然后修改后缀名为.bat生成脚本文件createsamples.bat文件,双击运行:
负样本的描述文件和正样本的处理方式有些不一样的地方:
在使用opencv_traincascade进行训练之前,负样本的描述文件也要配置完成才行。正样本描述文件在创建完成之后,在training3文件夹下生成了一个pos.vec文件,负样本只需要在training目录下生成一个.txt文件即可。
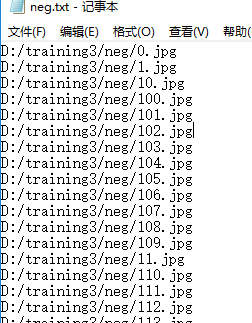
在neg文件夹下新建一个txt文件编辑内容为dir /b /s > neg.txt(加上/s指令是为了生成绝对路径),修改后缀名为.bat生成脚本文件,双击运行后生成neg.txt文件,在记事本中编辑neg.txt,使用ctrl+H将所有”\“替换成”/“(unix环境下的路径分隔符是”/“)。将完成好的neg.txt放在trainging3目录下,供后面的训练使用,如下图所示:
- 训练分类器
在training3目录下新建traincascade.txt文件,编辑该文本文件后修改后缀名为.bat生成脚本文件traincascade.bat。
opencv_traincascade.exe -data data -vec pos.vec -bg neg.txt -numPos 300 -numNeg 801 -numStages 20 -w 32 -h 32 -minHitRate 0.999 maxFalseAlarmRate 0.5 -precalcValBufSize 256 -precalcIdxBufSize 256 -mode ALL
pause各个参数含义如下所示:
-data
-vec
-bg
-numPos
-numNeg
-numStages
-precalcValBufSize
-precalcIdxBufSize
-baseFormatSave这个参数仅在使用Haar特征时有效。如果指定这个参数,那么级联分类器将以老的格式存储。
(precalcValBufSize和precalcIdxBufSize这两个参数不知道是给整个训练过程分配的内存大小还是每个stage分配的内存大小,还有一些说法说这个是给每个样本分配的内存。。。我尝试设置为1024的时候报错内存不足,后来改成了256就可以了,但是设置得太小会导致训练的时间过长,建议多尝试几次尽量把这两个参数设置得大一点)
训练之前training3文件夹之中准备好的文件应该如下图所示:
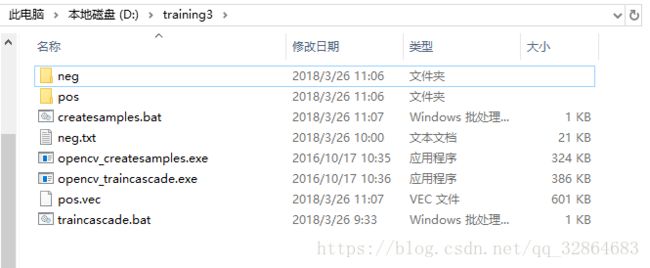
双击traincascade.bat运行开是训练,接下来就是漫长的等待了。。。。

生成的分类文件会存放在training3目录下data文件夹下:
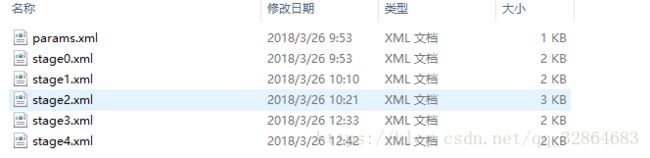
这里给出的截图只是训练了5个stage的xml文件,我之前设置的总stage数为20,所以要待所有的stage全部训练完毕才表示训练完成,最终会生成一个总的cascade.xml文件,检测的时候只需要这一个.xml文件就可以完成检测。之后我会再写一文讨论如何在c++编译环境下使用opencv中与级联分类器相关的CascadeClassifier类,从而实现目标检测。
- 常见问题
我在训练的过程中碰到了一些问题,在网上看了一些博客和问答,很多人也都碰到了相同的问题,但是这些问题在网络上所得到的解答不尽相同,有些人按照某些方法能恰如其当地解决问题,但是有些人用相同的办法却问题依旧,根本原因在于看似一样异常检出却有着不同的原因。我感觉要想真正找到问题所在就必须研究opencv和训练cascade分类器相关的源码,在此给出链接
https://blog.csdn.net/u011783201/article/details/52184300
比较常见的几个问题:
- 负样本描述文件neg.txt若没有放在opencv_traincascade目录下,并且neg.txt中的条目是含有样本的绝对路径的(最好用”/“做路径分隔符),否则在训练的时候会出现负样本无法创建的错误,即“Train dataset for temp stage can not be filled.Branch training terminated.”

- 如果训练到一半出现错误“Parameters can not be written, because file data/params.xml can not be opened”,则需要在训练文件夹下自己手动创建一个文件夹data。
- 当出现Training parameters are loaded from the parameter file in data folder!Please empty the data folder if you want to use your own set of parameters.terminate called after throwing an instance of 'std::bad_alloc'
what(): std::bad_alloc的错误的时候,说明当前的正样本的尺寸可能不合适(最初我的样本是56*56就报了这个错误,后来我改成了32*32就可以正常训练了),一般可能是尺寸太大,建议把尺寸缩小一点。

- 内存分配不适当导致内存不够:调整precalcValBufSize和precalcIdxBufSize这两个参数的大小(起始不输入这两个参数也可以自动分配)
