1004Java面试知识点准备
单一应用型框架和分布式架构的区别?
单一应用型框架的优缺点:
优点:网站流量小,只有一个应用(项目),所有的功能捆绑在一个应用中.部署简单及成本低.业务简单,开发成本小.
缺点:代码耦合度高,开发和维护困难.服务器负载有限 .无法针对不同模块进行针对性优化,单点容错率第,并发能力差.
总结来讲之前做的pv_webT项目包含移动端农户+业务员/微信小程序/后台管理系统代码耦合在一起,网站流量小,部署倒是简单,但是应用负载能力差,针对不同模块如移动端农户和业务员模块需要个性化维护需要使用过滤器/拦截器进行区别话对待,针对性优化难度高,同时单个应用如农户端业务员端出现问题,容错率差需要整个项目都重新部署,并发上讲太多功能在一个应用服务器并发能力差.
分布式架构的优缺点:
优点:分布式降低代码耦合,开发人员只需了解自己负责的业务代码,无需整体不相关的部分。系统可扩展性大,负载大,维护方便.
缺点:维护成本高,小公司来讲分布式架构应用部署 维护成本高.
Java中wait与sleep有什么区别?
1.方法出处,wait方法是Object中的成员方法,sleep是Thread中的静态方法
2.sleep可以在任何地方使用,而wait方法必须在同步代码块中或方法中使用否则会抛出异常
3.sleep不会释放当前线程占用的对象锁,wait方法会释放当前线程占用的对象所,只有在调用notify或者notifyAll方法时才可以让线程由阻塞状态进入可执行状态.(因为sleep方法使线程暂停一段执行时间,让出cpu时间,指定等待时间过了,需要一直被监控,所以对象所不会被释放,而wait方法放弃对象锁,进入对象线程等待池,只有主动调用notify或者notifyAll才会被唤醒,不需要对象监听,所以放弃锁.)
4.sleep方法会因为其他线程调用intercept方法而抛出中断异常错误,需要手动捕获,而wait则没有这个问题.
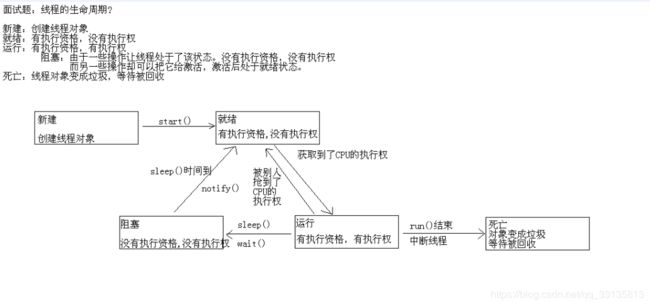
另外讲述一下线程的5中状态:分别包含创建/就绪/运行/阻塞/销毁/
阻塞使用2中方法如wait、sleep方法.
yield线程暂停,让优先级更高的线程优先执行.
joinf方法:线程加入.新加入的线程先执行完后,再执行当前线程.
volatile和synchronzied的作用
- volatile的本质是告诉jvm当前变量在寄存器中的值不确定,需要从主内存中读取.而synchronzied是锁定当前变量,只有当前线程可以访问,其他线程都不可以访问.
- volatile仅能使用在变量级别,而synchrozied可以在变量,方法,类中使用.
- volatile保证了当前的变量的多线程的可见性,但不保证原子性.而synchronzied保证了变量的可见性以及原子性.
- volatile修饰的变量在其他线程可以访问,而synchronzied修饰的变量只能被当前线程访问。
- volatile标记的变量不会被编译器优化,而synchrozied修饰的变量会被编译器优化.
所以总结上述的volatile与sychronzied之间的区别主要在于volatile在于告诉jvm当前变量在寄存器中不确定,需要去从主内存从读取.而synchronzied则是锁定当前对象,只能被当前线程访问,其他线程不可访问.同时修饰的变量volatile范围更小,只能是变量.而synchronzied可以修饰变量 方法和类.同时在多线程上vloatile其他线程可访问,而synchronzied其他线程不可访问.同时又提到一个概念就是vloatile仅保证了可见性,而synchronzied保证了可见性和原子性.同时在编译器优化层面volatile是被优化的,而synchronzied不被优化.另外在使用过程中发现volatile使用范围只能在类或成员方法中,而synchronzied使用范围更广.所以在2者的区别上无非就是作用+修饰范围+多线程作用+编译器优化这几方面讲.
Java中的原子类实现机制是什么?具体原理是什么?
采用硬件提供的原子操作指令去实现的.即CAS机制.存在三个值,内存值,预期值,比较值.通过比较内存值和预期值是否一致,如果一致,则进行数据修改.否则重试.
Spring中都用到了哪些?主要原理是什么?
Spring框架中主要使用到了IOC,AOP.MVC.IOC指的是控制反转,通过反射类获取对象实例,然后在调用的时候主动注入.AOP面向切面,主要指的利用动态代理实现m,主要应用于日志输出,事物控制,异常处理层面(实际项目中事物控制通过ControllerAdvice控制器增强创建事物控制,达到业务层实现类发生异常事物回滚控制的目的.日志输出指的是利用拦截器用哪一个接口,方法,调用时间,参数等必要日志,避免大量重复的工作。而异常处理指的是对控制层进行一个异常处理,ControllerAdvice利用该工具类实现异常处理的目的)
关于数据库性能优化之explain指令如何使用?文章参考链接
explain模拟优化器执行SQL语句,从而找到SQL语句的性能瓶颈在哪里?
通过explain执行计划得出来的信息包含以下几项:重要的几项主要是id,select_type,type,key、rows、Extra.
![]()
- id执行select子句或操作表的顺序 ,如果是子查询语句序号会递增,而如果序号一致,表示操作表的顺序.
- select_type指的是主查询或者子查询的类别,如简单查询时SIMPLE,UNION类型.
- type类型是性能优化的重要指标(最好能够达到range或者ref指标以上)效率从高到底依次system>const>eq_ref>ref》range>index>ALL.
system:指的是表中只存在一条数据.const指的是通过查询只有一条符合记录的数据.eq_ref指的视图是主键或者唯一索引查询出的数据.ref指的是通过通过非唯一性索引查询出来的数据.index指的通过给定范围查询出的列.这种查询相比全表索引查询新能更好一点.index通过索引查询全表.而All通过磁盘查找全表(新能最差) - possible_keys指的是如果查询字段中如果存在索引,则列举出来.但并不一定在实际查询中使用.
- key实际使用的索引,如果为空,则没有使用索引.
- key_len表示索引中使用的字节数,查询中使用的索引的长度(最大可能长度),并非实际使用长度,理论上长度越短越好。key_len是根据表定义计算而得的,不是通过表内检索出的
所以综上所述:利用EXPLAIN是对SQL语句优化的重要手段,通过id,select_type,table,type,possible_key,keys.可以看出SQL语句查询的大致结构,是否使用索引.type类型又分为system,const,eq_ref唯一索引,ref非唯一索性.range范围索引查询,index,all,一般来讲查询效率必须是range以上,说白了就是必须分页查询不能一次性查询过多数据,因为查询没有使用索引,而全局扫描的查询效率是很慢的,就比如之前业务员端没有分页查询一样,但是索引的使用如index,经常是联合索引和单列索引结合使用的,如果使用了索引但实际上没有发挥作用,效率也会很低的,那就回全表扫表如限制条件的联合索引使用不当,这就是关于SQL语句优化的解决思路问题.
单列索引和联合索引的理解?参考文章链接
- 单列索引指的是一个字段列使用一个索引,如果在多条件查询的时候会根据优化器的最优索引策略,可能使用一个索引,也有可能使用多个索引.但是单个单列索引会在底层创建的多个B+索引树,浪费磁盘空间和搜索效率.
- 多列索引a,b,c的本质是在 底层创建一个a单列索引+a,b联合索引+a,b,c联合索引.所以就有一个最左原则,即从左边开始为起点,只要是连续的索引都能匹配上,实际上a,c能够匹配是因为a单列索引起作用了.所以联合索引的顺序考虑非常重要,效率高的,查询使用频率高的放前面.a,b和b,a的效率都是有效的.
如果同时存在单列索引和多列索引优化器如何选择?
根优化器查询策略 ,当一条语句由多个索引可以走的时候,会根据查询成本来决定的(如时间等).
索引使用的一些基本概念?为什么不在每一个列上创建索引?
- (索引的使用位置)索引的使用是在where限制条件里面
- (索引创建字段的前提)索引的创建是基于某个字段值连续,且数据量大的情况下的.如果一个字段就2个值,没有必要创建索引的
- (磁盘空间的是使用)索引的创建会在磁盘栈用空间,导致修改删除数据的成本增高(因为需要维护索引)
- (必要性)同时多个单列索引的创建,会在底层创建多个B+索引树,搜索效率下降.同时根据业务创建一个多列索引相比多个单列索引更靠谱.