SpringBoot使用Sharding-JDBC分库分表
本文介绍SpringBoot使用当当Sharding-JDBC进行分库分表。
1.有关Sharding-JDBC
有关Sharding-JDBC介绍这里就不在多说,之前Sharding-JDBC是当当网自研的关系型数据库的水平扩展框架,现在已经捐献给Apache,具体可以查看Github,地址是:https://shardingsphere.apache.org/document/current/cn/overview/
shardingsphere文档地址是:https://shardingsphere.apache.org/document/current/cn/overview/。
目前貌似还不能从Maven仓库下载依赖,需要手动下载源码打包使用,所以本文使用的还是当当网的依赖。
2.本文场景
2.1 数据库
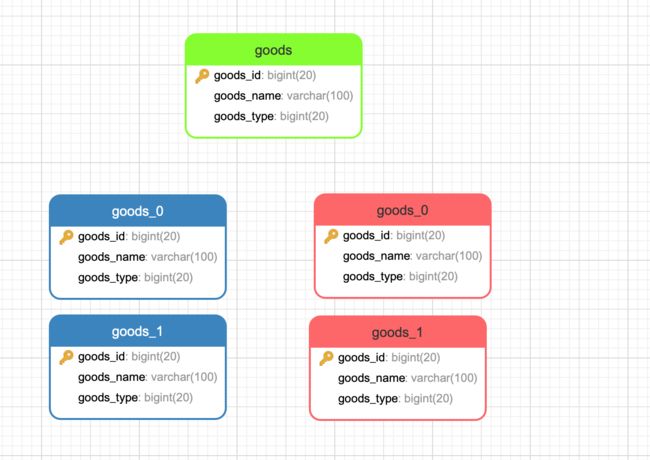
接下来介绍一下本文的场景,本文是分别创建了2个数据库database0和database1。其中每个数据库都创建了2个数据表,goods_0和goods_1,如图所示。这里蓝色的代表database0中的表,红色的代表database1中的表。绿色goods表是虚拟表(图画的比较丑,审美不好,凑合看吧)。
2.2 分库
本文分库样例比较简单,根据数据库表中字段goods_id的大小进行判断,如果goods_id大于20则使用database0,否则使用database1。
2.3 分表
分样例比较简单,根据数据库表中字段goods_type的数值的奇偶进行判断,奇数使用goods_1表,偶数使用goods_0表。
2.4 代码流程
流程大致是这样,在应用程序中我们操作虚拟表goods,但是当真正操作数据库的时候,会根据我们的分库分表规则进行匹配然后操作。
3.代码实现
本文使用SpringBoot2.0.3,SpringData-JPA,Druid连接池,和当当的sharding-jdbc。
3.1 建表SQL
创建表和数据库的SQL如下所示。
CREATE DATABASE database0;
USE database0;
DROP TABLE IF EXISTS `goods_0`;
CREATE TABLE `goods_0` (
`goods_id` bigint(20) NOT NULL,
`goods_name` varchar(100) COLLATE utf8_bin NOT NULL,
`goods_type` bigint(20) DEFAULT NULL,
PRIMARY KEY (`goods_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
DROP TABLE IF EXISTS `goods_1`;
CREATE TABLE `goods_1` (
`goods_id` bigint(20) NOT NULL,
`goods_name` varchar(100) COLLATE utf8_bin NOT NULL,
`goods_type` bigint(20) DEFAULT NULL,
PRIMARY KEY (`goods_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
CREATE DATABASE database1;
USE database1;
DROP TABLE IF EXISTS `goods_0`;
CREATE TABLE `goods_0` (
`goods_id` bigint(20) NOT NULL,
`goods_name` varchar(100) COLLATE utf8_bin NOT NULL,
`goods_type` bigint(20) DEFAULT NULL,
PRIMARY KEY (`goods_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
DROP TABLE IF EXISTS `goods_1`;
CREATE TABLE `goods_1` (
`goods_id` bigint(20) NOT NULL,
`goods_name` varchar(100) COLLATE utf8_bin NOT NULL,
`goods_type` bigint(20) DEFAULT NULL,
PRIMARY KEY (`goods_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
3.2 依赖文件
新建项目,加入当当的sharding-jdbc-core依赖和druid连接池,完整pom如下所示。
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.0.3.RELEASE
com.dalaoyang
springboot2_shardingjdbc_fkfb
0.0.1-SNAPSHOT
springboot2_shardingjdbc_fkfb
springboot2_shardingjdbc_fkfb
1.8
org.springframework.boot
spring-boot-starter-data-jpa
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-devtools
runtime
mysql
mysql-connector-java
runtime
org.springframework.boot
spring-boot-starter-test
test
org.projectlombok
lombok
true
com.alibaba
druid
1.1.9
com.dangdang
sharding-jdbc-core
1.5.4
org.springframework.boot
spring-boot-maven-plugin
3.3 配置信息
在配置信息中配置了两个数据库的信息和JPA的简单配置。
##Jpa配置
spring.jpa.database=mysql
spring.jpa.show-sql=true
spring.jpa.hibernate.ddl-auto=none
##数据库配置
##数据库database0地址
database0.url=jdbc:mysql://localhost:3306/database0?characterEncoding=utf8&useSSL=false
##数据库database0用户名
database0.username=root
##数据库database0密码
database0.password=root
##数据库database0驱动
database0.driverClassName=com.mysql.jdbc.Driver
##数据库database0名称
database0.databaseName=database0
##数据库database1地址
database1.url=jdbc:mysql://localhost:3306/database1?characterEncoding=utf8&useSSL=false
##数据库database1用户名
database1.username=root
##数据库database1密码
database1.password=root
##数据库database1驱动
database1.driverClassName=com.mysql.jdbc.Driver
##数据库database1名称
database1.databaseName=database1
3.4 启动类
启动类加入了@EnableAutoConfiguration取出数据库自动配置,使用@EnableTransactionManagement开启事务,使用@EnableConfigurationProperties注解加入配置实体,启动类完整代码请入所示。
package com.dalaoyang;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.transaction.annotation.EnableTransactionManagement;
@SpringBootApplication
@EnableAutoConfiguration(exclude={DataSourceAutoConfiguration.class})
@EnableTransactionManagement(proxyTargetClass = true)
@EnableConfigurationProperties
public class Springboot2ShardingjdbcFkfbApplication {
public static void main(String[] args) {
SpringApplication.run(Springboot2ShardingjdbcFkfbApplication.class, args);
}
}
3.5 实体类和数据库操作层
这里没什么好说的,就是简单的实体和Repository,只不过在Repository内加入between方法和in方法用于测试,代码如下所示。
Goods实体类。
package com.dalaoyang.entity;
import lombok.Data;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
/**
* @author yangyang
* @date 2019/1/29
*/
@Entity
@Table(name="goods")
@Data
public class Goods {
@Id
private Long goodsId;
private String goodsName;
private Long goodsType;
}
GoodsRepository类。
package com.dalaoyang.repository;
import com.dalaoyang.entity.Goods;
import org.springframework.data.jpa.repository.JpaRepository;
import java.util.List;
/**
* @author yangyang
* @date 2019/1/29
*/
public interface GoodsRepository extends JpaRepository {
List findAllByGoodsIdBetween(Long goodsId1,Long goodsId2);
List findAllByGoodsIdIn(List goodsIds);
}
3.6 数据库配置
本文使用了两个实体来接收数据库信息,并且创建数据源,也可以采用别的方式。首先看一下Database0Config和Database1Config两个类的代码。
Database0Config类。
package com.dalaoyang.database;
import com.alibaba.druid.pool.DruidDataSource;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
import javax.sql.DataSource;
/**
* @author yangyang
* @date 2019/1/30
*/
@Data
@ConfigurationProperties(prefix = "database0")
@Component
public class Database0Config {
private String url;
private String username;
private String password;
private String driverClassName;
private String databaseName;
public DataSource createDataSource() {
DruidDataSource result = new DruidDataSource();
result.setDriverClassName(getDriverClassName());
result.setUrl(getUrl());
result.setUsername(getUsername());
result.setPassword(getPassword());
return result;
}
}
Database1Config类。
package com.dalaoyang.database;
import com.alibaba.druid.pool.DruidDataSource;
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
import javax.sql.DataSource;
/**
* @author yangyang
* @date 2019/1/30
*/
@Data
@ConfigurationProperties(prefix = "database1")
@Component
public class Database1Config {
private String url;
private String username;
private String password;
private String driverClassName;
private String databaseName;
public DataSource createDataSource() {
DruidDataSource result = new DruidDataSource();
result.setDriverClassName(getDriverClassName());
result.setUrl(getUrl());
result.setUsername(getUsername());
result.setPassword(getPassword());
return result;
}
}
接下来新建DataSourceConfig用于创建数据源和使用分库分表策略,其中分库分表策略会调用分库算法类和分表算法类,DataSourceConfig类代码如下所示。
package com.dalaoyang.database;
import com.dalaoyang.config.DatabaseShardingAlgorithm;
import com.dalaoyang.config.TableShardingAlgorithm;
import com.dangdang.ddframe.rdb.sharding.api.ShardingDataSourceFactory;
import com.dangdang.ddframe.rdb.sharding.api.rule.DataSourceRule;
import com.dangdang.ddframe.rdb.sharding.api.rule.ShardingRule;
import com.dangdang.ddframe.rdb.sharding.api.rule.TableRule;
import com.dangdang.ddframe.rdb.sharding.api.strategy.database.DatabaseShardingStrategy;
import com.dangdang.ddframe.rdb.sharding.api.strategy.table.TableShardingStrategy;
import com.dangdang.ddframe.rdb.sharding.keygen.DefaultKeyGenerator;
import com.dangdang.ddframe.rdb.sharding.keygen.KeyGenerator;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import java.sql.SQLException;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
/**
* @author yangyang
* @date 2019/1/29
*/
@Configuration
public class DataSourceConfig {
@Autowired
private Database0Config database0Config;
@Autowired
private Database1Config database1Config;
@Autowired
private DatabaseShardingAlgorithm databaseShardingAlgorithm;
@Autowired
private TableShardingAlgorithm tableShardingAlgorithm;
@Bean
public DataSource getDataSource() throws SQLException {
return buildDataSource();
}
private DataSource buildDataSource() throws SQLException {
//分库设置
Map dataSourceMap = new HashMap<>(2);
//添加两个数据库database0和database1
dataSourceMap.put(database0Config.getDatabaseName(), database0Config.createDataSource());
dataSourceMap.put(database1Config.getDatabaseName(), database1Config.createDataSource());
//设置默认数据库
DataSourceRule dataSourceRule = new DataSourceRule(dataSourceMap, database0Config.getDatabaseName());
//分表设置,大致思想就是将查询虚拟表Goods根据一定规则映射到真实表中去
TableRule orderTableRule = TableRule.builder("goods")
.actualTables(Arrays.asList("goods_0", "goods_1"))
.dataSourceRule(dataSourceRule)
.build();
//分库分表策略
ShardingRule shardingRule = ShardingRule.builder()
.dataSourceRule(dataSourceRule)
.tableRules(Arrays.asList(orderTableRule))
.databaseShardingStrategy(new DatabaseShardingStrategy("goods_id", databaseShardingAlgorithm))
.tableShardingStrategy(new TableShardingStrategy("goods_type", tableShardingAlgorithm)).build();
DataSource dataSource = ShardingDataSourceFactory.createDataSource(shardingRule);
return dataSource;
}
@Bean
public KeyGenerator keyGenerator() {
return new DefaultKeyGenerator();
}
}
3.7 分库分表算法
由于这里只是简单的分库分表样例,所以分库类这里实现SingleKeyDatabaseShardingAlgorithm类,采用了单分片键数据源分片算法,需要重写三个方法,分别是:
- doEqualSharding:SQL中==的规则。
- doInSharding:SQL中in的规则。
- doBetweenSharding:SQL中between的规则。
本文分库规则是基于值大于20则使用database0,其余使用database1,所以简单if,else就搞定了,分库算法类DatabaseShardingAlgorithm代码如下所示。
package com.dalaoyang.config;
import com.dalaoyang.database.Database0Config;
import com.dalaoyang.database.Database1Config;
import com.dangdang.ddframe.rdb.sharding.api.ShardingValue;
import com.dangdang.ddframe.rdb.sharding.api.strategy.database.SingleKeyDatabaseShardingAlgorithm;
import com.google.common.collect.Range;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.Collection;
import java.util.LinkedHashSet;
/**
* 这里使用的都是单键分片策略
* 示例分库策略是:
* GoodsId<=20使用database0库
* 其余使用database1库
* @author yangyang
* @date 2019/1/30
*/
@Component
public class DatabaseShardingAlgorithm implements SingleKeyDatabaseShardingAlgorithm {
@Autowired
private Database0Config database0Config;
@Autowired
private Database1Config database1Config;
@Override
public String doEqualSharding(Collection availableTargetNames, ShardingValue shardingValue) {
Long value = shardingValue.getValue();
if (value <= 20L) {
return database0Config.getDatabaseName();
} else {
return database1Config.getDatabaseName();
}
}
@Override
public Collection doInSharding(Collection availableTargetNames, ShardingValue shardingValue) {
Collection result = new LinkedHashSet<>(availableTargetNames.size());
for (Long value : shardingValue.getValues()) {
if (value <= 20L) {
result.add(database0Config.getDatabaseName());
} else {
result.add(database1Config.getDatabaseName());
}
}
return result;
}
@Override
public Collection doBetweenSharding(Collection availableTargetNames,
ShardingValue shardingValue) {
Collection result = new LinkedHashSet<>(availableTargetNames.size());
Range range = shardingValue.getValueRange();
for (Long value = range.lowerEndpoint(); value <= range.upperEndpoint(); value++) {
if (value <= 20L) {
result.add(database0Config.getDatabaseName());
} else {
result.add(database1Config.getDatabaseName());
}
}
return result;
}
}
分表和分库类似,无非就是实现的类不一样,实现了SingleKeyTableShardingAlgorithm类,策略使用值奇偶分表,分表算法类TableShardingAlgorithm如代码清单所示。
package com.dalaoyang.config;
import com.dangdang.ddframe.rdb.sharding.api.ShardingValue;
import com.dangdang.ddframe.rdb.sharding.api.strategy.table.SingleKeyTableShardingAlgorithm;
import com.google.common.collect.Range;
import org.springframework.stereotype.Component;
import java.util.Collection;
import java.util.LinkedHashSet;
/**
* 这里使用的都是单键分片策略
* 示例分表策略是:
* GoodsType为奇数使用goods_1表
* GoodsType为偶数使用goods_0表
* @author yangyang
* @date 2019/1/30
*/
@Component
public class TableShardingAlgorithm implements SingleKeyTableShardingAlgorithm {
@Override
public String doEqualSharding(final Collection tableNames, final ShardingValue shardingValue) {
for (String each : tableNames) {
if (each.endsWith(shardingValue.getValue() % 2 + "")) {
return each;
}
}
throw new IllegalArgumentException();
}
@Override
public Collection doInSharding(final Collection tableNames, final ShardingValue shardingValue) {
Collection result = new LinkedHashSet<>(tableNames.size());
for (Long value : shardingValue.getValues()) {
for (String tableName : tableNames) {
if (tableName.endsWith(value % 2 + "")) {
result.add(tableName);
}
}
}
return result;
}
@Override
public Collection doBetweenSharding(final Collection tableNames,
final ShardingValue shardingValue) {
Collection result = new LinkedHashSet<>(tableNames.size());
Range range = shardingValue.getValueRange();
for (Long i = range.lowerEndpoint(); i <= range.upperEndpoint(); i++) {
for (String each : tableNames) {
if (each.endsWith(i % 2 + "")) {
result.add(each);
}
}
}
return result;
}
}
3.8 Controller
接下来创建一个Controller进行测试,保存方法使用了插入40条数据,根据我们的规则,会每个库插入20条,同时我这里还创建了三个查询方法,分别是查询全部,between查询,in查询,还有删除全部方法。Controller类代码如下所示。
package com.dalaoyang.controller;
import com.dalaoyang.entity.Goods;
import com.dalaoyang.repository.GoodsRepository;
import com.dangdang.ddframe.rdb.sharding.keygen.KeyGenerator;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.ArrayList;
import java.util.List;
/**
* @author yangyang
* @date 2019/1/29
*/
@RestController
public class GoodsController {
@Autowired
private KeyGenerator keyGenerator;
@Autowired
private GoodsRepository goodsRepository;
@GetMapping("save")
public String save(){
for(int i= 1 ; i <= 40 ; i ++){
Goods goods = new Goods();
goods.setGoodsId((long) i);
goods.setGoodsName( "shangpin" + i);
goods.setGoodsType((long) (i+1));
goodsRepository.save(goods);
}
return "success";
}
@GetMapping("select")
public String select(){
return goodsRepository.findAll().toString();
}
@GetMapping("delete")
public void delete(){
goodsRepository.deleteAll();
}
@GetMapping("query1")
public Object query1(){
return goodsRepository.findAllByGoodsIdBetween(10L, 30L);
}
@GetMapping("query2")
public Object query2(){
List goodsIds = new ArrayList<>();
goodsIds.add(10L);
goodsIds.add(15L);
goodsIds.add(20L);
goodsIds.add(25L);
return goodsRepository.findAllByGoodsIdIn(goodsIds);
}
}
4.测试
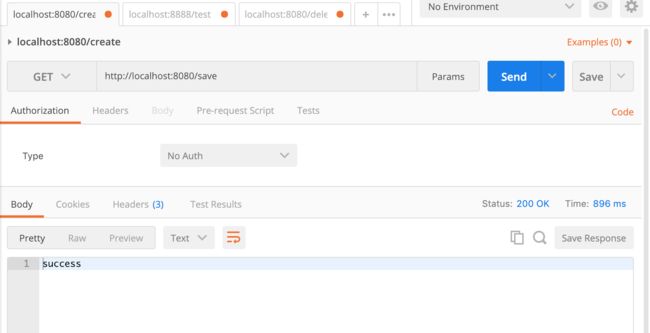
启动应用,在浏览器或HTTP请求工具访问http://localhost:8080/save,如图所示,返回success。
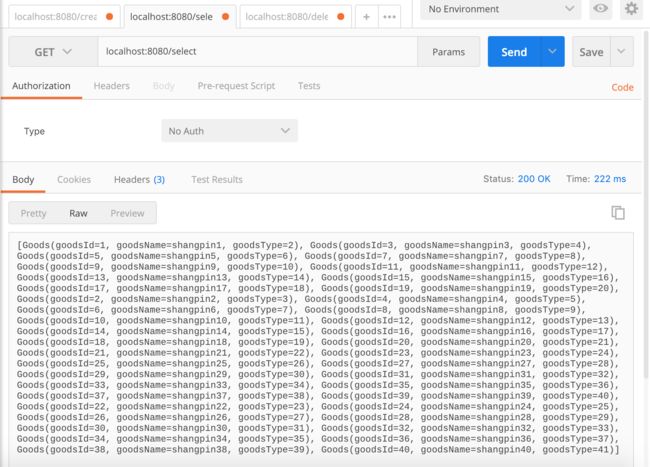
接下来在测试一下查询方法,访问http://localhost:8080/select,如图所示,可以看到插入数据没问题。
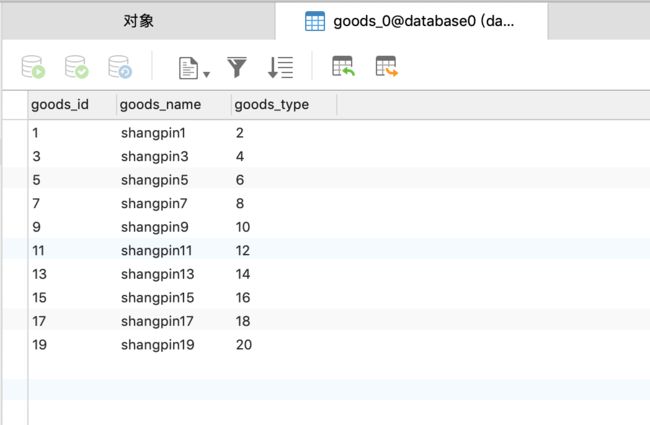
然后查看一下数据库,首先看database0,如图,每个表都有十条数据,如下所示。


接下来看database1,如下所示。

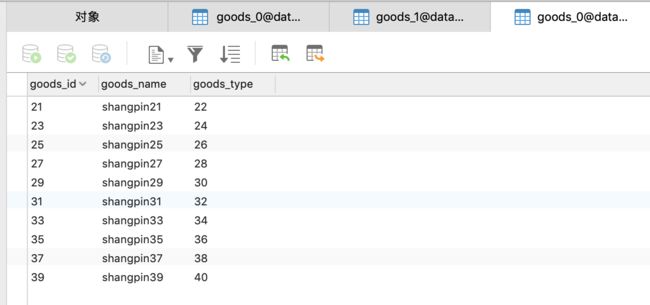
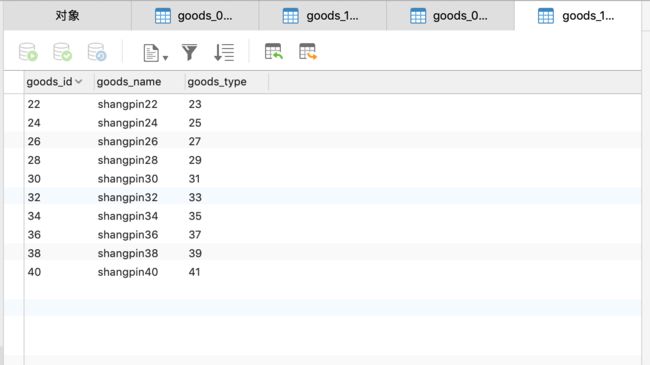
从上面几张图可以看出分库分表已经按照我们的策略来进行插入,至于其他几个测试这里就不做介绍了,无论是查询和删除都是可以成功的。
5 源码
源码地址:https://gitee.com/dalaoyang/springboot_learn/tree/master/springboot2_shardingjdbc_fkfb