数据挖掘文本分类实验
一、文本分类:
用电脑对文本集(或其他实体或物件)按照一定的分类体系或标准进行自动分类标记。本实验从中国新闻网爬取了10类(财经、国际、It、健康、军事、能源、汽车、体育、文化、娱乐)共180多万篇新闻,经过分词、取名词、去掉停用词、计算tfidf降低维度、然后生成分类器的输入数据,采用朴素贝叶斯作为baseline,还用了svm和libsvm分类器来对这100万篇文章进行分类。然后输出分类结果和一些其他评估数据。
构建语料库
本次实验,我们使用的预料库是我们利用python编写爬虫程序在中国新闻网(http://www.chinanews.com/)爬取的数据集。新闻分类共有十类,分别是:财经、国际、互联网、健康、军事、能源、汽车、体育、文化和娱乐。
二 、实验步骤
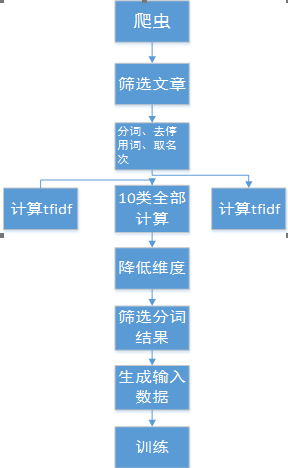
上图为本次试验的处理流程,爬数据,筛选文章,分词,去停用次,取名次,计算每类的tfidf降低维度,筛选分词结果,生成输入数据,训练
爬虫代码
# -*- coding: utf-8 -*-
import scrapy
from scrapy.http import Request
from scrapy.selector import Selector
import os
import codecs
import time
import datetime
mkpath = "C:\\Users\\chenteng\\Desktop\\NEWS-PA\\newsPa\\caijing\\"
#txtid = 0
#base_dir = mkpath
class NewsSpider(scrapy.Spider):
name = 'news'
allowed_domains = ['chinanews.com']
start_urls = ['http://www.chinanews.com/']
def parse(self, response):
date_list = getBetweenDay("20091201")
for day in date_list:
year = day[0:4]
dayday = day[4:8]
#global base_dir
#base_dir = mkpath+day+"\\"
#mkdir(base_dir)
#global txtid
#txtid = 0
#time.sleep(0.1)
total = "http://www.chinanews.com/scroll-news/cj/{0}/{1}/news.shtml".format(year,dayday)
yield Request(total,meta = {"day":day},callback = self.info_1)
def info_1(self,response):
selector = Selector(response)
day = response.meta["day"]
base_dir = mkpath+day+"\\"
mkdir(base_dir)
txtid = 0
print "===============base_dir=============="
list = selector.xpath("//div[@class='dd_bt']/a/@href").extract()
for url in list:
txtid += 1
filename = base_dir + str(txtid) +'.txt'
yield Request(url,meta = {"filename":filename},callback = self.info_2)
def info_2(self,response):
selector = Selector(response)
filename = response.meta["filename"]
print "===============filename=============="
list = selector.xpath("//div[@class='left_zw']/p/text()").extract()
print list
#global txtid
#txtid +=1
#filename = base_dir + str(txtid) +'.txt'
#print filename
f = codecs.open(filename,'a','utf-8')
for i in range(len(list)-1):
print '=========' + str(i) + "=========="
f.write(list[i])
f.close()
def mkdir(path):
# 去除首位空格
path=path.strip()
# 去除尾部 \ 符号
path=path.rstrip("\\")
# 判断路径是否存在
# 存在 True
# 不存在 False
isExists=os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(path)
print path+' 创建成功'
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print path+' 目录已存在'
return False
def getBetweenDay(begin_date):
date_list = []
begin_date = datetime.datetime.strptime(begin_date, "%Y%m%d")
end_date = datetime.datetime.strptime(time.strftime('%Y%m%d',time.localtime(time.time())), "%Y%m%d")
while begin_date <= end_date:
date_str = begin_date.strftime("%Y%m%d")
date_list.append(date_str)
begin_date += datetime.timedelta(days=1)
return date_list预处理代码(每步都存储了中间文件,比较慢)
# -*- coding: utf-8 -*-
import jieba
import jieba.posseg as pseg
import os,re,collections
import sys
import numpy as np
from numpy import nan as Na
import pandas as pd
from pandas import Series,DataFrame
sys.setrecursionlimit(999999999)#增加递归次数
stopwords = {}.fromkeys([ line.rstrip() for line in open('stopwords.txt','r',encoding='utf-8')])
#stopwords = {}.fromkeys(['时代', '新机遇','机遇','意识','人'])
#遍历txt文件,分词、取名次、去停用词
#filepath为文件夹路径list,i是第几类
#会一层一层遍历到最内层的txt读取新闻并进行分词
def gci(filepath,i):
#遍历filepath下所有文件,包括子目录
files = os.listdir(filepath)
for fi in files:
path = os.path.join(filepath,fi)
if os.path.isdir(path):
gci(path)
else:
sliptword(path,i)
#分词、取名次、去停用词
#path是文本路径,i是类
#oriDictPathList[i]是第i类的字典
def sliptword(path,i):
print(path)
# news为我原来放新闻的文件夹名字,用正则表达式把它替换成split,换个文件夹保存
strinfo = re.compile('news')
writepath=strinfo.sub('split',path) #分词结果写入的路径split
with open(path, "r",encoding='utf-8') as f:
text = f.read()
str = ""
str2=""
result = pseg.cut(text) ##词性标注,标注句子分词后每个词的词性
for w in result:#遍历每个词语
if w.flag.startswith('n'):#如果词性是n开头的说明是名次,留下
if w.word not in stopwords:#如果不在停用次表里,留下保存在字符串里
str = str + w.word+"\n"
str2 =str2+w.word+" "
with open(writepath,"a")as f:
f.write(str)
with open(oriDictPathList[i], "a")as f:
f.write(str2)
#计算tfdif
#oriDictPathList为原始的字典list,存放每类的所有词语,不去重,维度很高
def tfidf(oriDictPathList):
import sklearn
from sklearn.feature_extraction.text import CountVectorizer
# 语料
corpus=[]#存放每类的字典
for i in range(len(oriDictPathList)):
print(i,"\n")
with open(oriDictPathList[i],'r',encoding='utf-8')as f:
corpus.append(f.read())
print(len(corpus[i]),"\n")
# corpus = [
# 'This is the first document.',
# 'This is the second second document.',
# 'And the third one.',
# 'Is this the first document?',
# ]
# 将文本中的词语转换为词频矩阵
vectorizer = CountVectorizer()
# 计算个词语出现的次数
X = vectorizer.fit_transform(corpus)
# 获取词袋中所有文本关键词
word = vectorizer.get_feature_names()
#把10类中出现的所有词语存放到allword.txt里
with open("E:\\新建文件夹\\文本\\新建文件夹\\python\\DataMinning\\tfidf\\allword.txt",'w',encoding='utf-8') as f:
print(len(word))
s='\n'.join(word)
print(len(s))
f.write('\n'.join(word))
# 查看词频结果
# print("X.toarray():",X.toarray())
#np.set_printoptions(threshold='nan')
np.set_printoptions(threshold=np.inf)
print(1)
#wordfrepath为存放每类词频文件的list
#每个文件写如本类的词频,此时的词频维度是多类的总维度
for i in range(len(wordfrepath)):
print("i:",i)
s = str(X.toarray()[i])
s = s.lstrip('[')
s = s.rstrip(']')
with open(wordfrepath[i], 'w', encoding='utf-8')as f:
f.write(s)
from sklearn.feature_extraction.text import TfidfTransformer
# 类调用
transformer = TfidfTransformer()
print("transformer:",transformer)
# 将词频矩阵X统计成TF-IDF值
tfidf = transformer.fit_transform(X)
# 查看数据结构 tfidf[i][j]表示i类文本中的tf-idf权重
# print("tfidf.toarray()",tfidf.toarray())
np.set_printoptions(threshold=np.inf)#加上这句可以全输出或者全写入,不然中间是省略号
print(2)
#tfidfpath为存放每类的tfidf数值的list
for i in range(len(tfidfpath)):
print(i)
s = str(tfidf.toarray()[i])
s = s.lstrip('[')
s = s.rstrip(']')
with open(tfidfpath[i], 'w', encoding='utf-8')as f:
f.write(s)
#快排,因为要挑选出每类tfidf数值最大的若干个词语,同时还要把对应词语也筛选出来,所以手写快排用它的索引
def parttion(v1,v2, left, right):
key1 = v1[left]
key2 = v2[left]
low = left
high = right
while low < high:
while (low < high) and (v1[high] <= key1):
high -= 1
v1[low] = v1[high]
v2[low] = v2[high]
while (low < high) and (v1[low] >= key1):
low += 1
v1[high] = v1[low]
v2[high] = v2[low]
v1[low] = key1
v2[low] = key2
return low
def quicksort(v1,v2, left, right):
if left < right:
p = parttion(v1,v2, left, right)
print(p)
quicksort(v1,v2, left, p-1)
quicksort(v1,v2, p+1, right)
return v1,v2
#降低维度
#把每类的tfidf和对应的词语重排序,写入新文件newtfidfpath,newdictpath
def reducedimension(tfidfpath,allwordpath,newtfidfpath,newdictpath):
for i in range(len(tfidfpath)):
with open(tfidfpath[i],'r',encoding='utf-8')as f:
text=f.read()
tfidftemp = text.split()
with open(allwordpath,'r',encoding='utf-8')as f:
text=f.read()
allwordlisttemp =text.split()
tfidflist = []
allwordlist = []
for j in range(len(tfidftemp)):
k = float(tfidftemp[j])
if k > 9.99999999e-05:
tfidflist.append(k)
allwordlist.append(allwordlisttemp[j])
newtfidflist,newallwordlist=quicksort(tfidflist,allwordlist,0,len(tfidflist)-1)
with open(newtfidfpath[i],'w',encoding='utf-8')as f:
f.write(" ".join(str(newtfidflist)))
with open(newdictpath[i],'w',encoding='utf-8')as f:
f.write(" ".join(newallwordlist))
#创建新字典
#在每类里找前n个tfidf最大的词语放进总字典,这里用scipy里dataframe和series合并
def createdict(newtfidfpath,newdictpath,dictpath):
l=[]
for i in range(len(newtfidfpath)):
with open(newtfidfpath[i],'r',encoding='utf-8')as f:
tfidflist=[float(e) for e in f.read().split()[0:1000]]
with open(newdictpath[i],'r',encoding='utf-8')as f:
wordlist=f.read().split()[0:1000]
s=Series(tfidflist,wordlist)
l.append(s)
dictdataframe = pd.DataFrame(l)
#存起来
pd.set_option('max_colwidth', 20000000)
with open(dictpath,'w',encoding='utf-8')as f:
f.write(" ".join(dictdataframe.columns.tolist()))
#根据新字典重新分词,新的分词结果存放在newsplit里,把不在字典里的词语扔掉
def createnewsplit(dictpath,splitPath):
strinfo = re.compile('split') # news
with open(dictpath,'r',encoding='utf-8')as f:
worddict=f.read().split()
for i in range(len(splitPath)):
files=os.listdir(splitPath[i])
index1=1
for fi in files:
path = os.path.join(splitPath, fi)
if index1 >= 0:
try:
list1 = [line.rstrip('\n') for line in open(path, 'r',encoding='utf-8')]
except:
list1 = [line.rstrip('\n') for line in open(path, 'r')]
list2=[e for e in list1 if e in worddict]
list3=list(set(list1))
writepath = strinfo.sub('newsplit', path) # 分词结果写入的路径split
with open(writepath, 'w', encoding='utf-8')as f:
f.write(" ".join(list3))
#print("index1",index1)
index1 = index1 + 1
#生成svm的输入数据
def svminputdata(dictpath,SplitPathList):
with open(dictpath,'r',encoding='utf-8')as f:
dict=f.read().split()
rindex=list(range(len(dict)))
#rindex=["t"+str(e) for e in range(len(dict))]
sd=Series(np.ones(len(dict)).tolist(),index=dict)
strinfo = re.compile('split') # news
trainindex=1
testindex=1
for i in range(len(SplitPathList)):
index1 = 1
num=i+1
files = os.listdir(SplitPathList[i])
for fi in files:
#print("s1")
path=os.path.join(SplitPathList[i],fi)
try:
with open(path, 'r', encoding='utf-8')as f:
list1 = f.read().split()
except:
with open(path, 'r')as f:
list1 = f.read().split()
list2 = [e for e in list1 if e in dict]
s = Series(list2)
s = s.value_counts()
s2 = Series(s.values, index=s.index)
s3 = s2 * sd
s3 = Series(s3.values, index=rindex)
s4 = s3[s3.notnull()]
s4index = s4.index
s4values = s4.values
if index1<=500:
if trainindex>=0:
str1 = ""
for j in range(len(s4)):
str1 = str1 + str(trainindex) + " " + str(s4index[j]) + " " + str(int(s4values[j])) + "\n"
with open("E:\\新建文件夹\\文本\\新建文件夹\\python\\DataMinning\\inputdata\\svm\\train1.data", 'a',
encoding='utf-8')as f:
f.write(str1)
with open("E:\\新建文件夹\\文本\\新建文件夹\\python\\DataMinning\\inputdata\\svm\\train1.label", 'a',
encoding='utf-8')as f:
f.write(str(num) + "\n")
writepath = strinfo.sub('splitwordfre', path)
trainindex += 1
if index1>500 and index1<=1000:
if testindex>=0:
str1 = ""
for j in range(len(s4)):
str1 = str1 + str(int(testindex)) + " " + str(s4index[j]) + " " + str(int(s4values[j])) + "\n"
with open("E:\\新建文件夹\\文本\\新建文件夹\\python\\DataMinning\\inputdata\\svm\\test1.data", 'a',
encoding='utf-8')as f:
f.write(str1)
with open("E:\\新建文件夹\\文本\\新建文件夹\\python\\DataMinning\\inputdata\\svm\\test1.label", 'a',
encoding='utf-8')as f:
f.write(str(num) + "\n")
writepath = strinfo.sub('splitwordfre', path)
testindex += 1
if index1==1000:
break
index1+=1
print("type trainindex testindex articleindex",num," ",trainindex," ",testindex," ",index1)
# 生成libsvm的输入数据,libsvm很慢
def libsvminputdata(dictpath, newdictpath,newtfidfpath,newSplitPathList):
with open(dictpath,'r',encoding='utf-8')as f:
dict=f.read().split()
sd=Series(np.ones(len(dict)).tolist(),index=dict)
print(len(dict))
sl=[]
rindex=[float(e) for e in range(len(dict))]
for i in range(len(newdictpath)):
with open(newdictpath[i], 'r', encoding='utf-8')as f:
alldict = f.read().split()
with open(newtfidfpath[i], 'r', encoding='utf-8')as f:
alltfidf = [float(e) for e in f.read().split()]
print(len(alldict))
print(len(alltfidf))
sad = Series(alltfidf, index=alldict)
sl.append(sad)
for i in range(len(newSplitPathList)):
files = os.listdir(newSplitPathList[i])
num=i+1
for fi in files:
path=os.path.join(newSplitPathList[i],fi)
try:
with open(path, 'r', encoding='utf-8')as f:
list1 = f.read().split()
except:
with open(path,'r')as f:
list1=f.read().split()
s=Series(np.ones(len(list1)).tolist(),index=list1)
print("s1",len(s))
s2=s*sl[i]
print("s2",len(s2))
s3=s2*sd
print("s3",len(s3))
break
s4=s3[s3.notnull()]
s4index=s4.index
s4values=s4.values
str1=""
for j in range(len(s4)):
str1 = str1+str(trainindex) + " " +str(s4index[j])+" "+str(int(s4values[j]))+"\n"
with open("",'a',encoding='utf-8')as f:
f.write(str1)
with open("",'a',encoding='utf-8')as f:
f.write(str(num)+"\n")
break